 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEChO-Agent: Evidence Chain Orchestration Agent for Audio Reasoning
Jun 13, 2026While LALMs show promise on audio question answering, they fail to focus on question-relevant segments of audio and provide a clear, checkable reasoning process when dealing with complex audio reasoning. Reinforcement learning and tool-augmented prompting can help models better relate questions to audio but lack a reliable way to understand, integrate, and self-verify audio segments. To address this gap, we present EChO-Agent, a modular agent framework that reformulates complex audio QA as a planning, tool execution, evidence integration, and answer verification workflow. Experiments on MMAR benchmark show EChO-Agent improves both accuracy and rubric scores over baseline and ablation studies show evidence integration is the key factor.
LLM-as-a-Reviewer: Benchmarking Their Ability, Divergence, and Prompt Injection Resistance as Paper Reviewers
May 25, 2026Large language models (LLMs) are increasingly used in academic peer review, yet their reliability, alignment with human judgment, and robustness to adversarial attacks remain poorly understood. We present a systematic benchmark of LLM-as-a-Reviewer on 898 papers stratified from NeurIPS and ICLR, evaluating 12 LLMs along three axes: rating calibration, divergence from human reviewers, and resistance to prompt injection embedded via an invisible font-mapping attack. We find that LLMs systematically overrate weaker submissions and diverge from humans in topical emphasis, under-flagging Clarity and over-flagging Reproducibility, while producing reviews two to three times longer with lower lexical diversity and a more standardized vocabulary. Prompt injection remains highly effective. Simple hidden instructions can promote low-scoring papers to acceptance-level ratings in a substantial fraction of cases, with effectiveness varying sharply across model families. While LLMs offer utility in structuring evaluations, their integration into peer review requires safeguards against both intrinsic biases and adversarial risks.
Evaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
ASDA: Audio Spectrogram Differential Attention Mechanism for Self-Supervised Representation Learning
Jul 03, 2025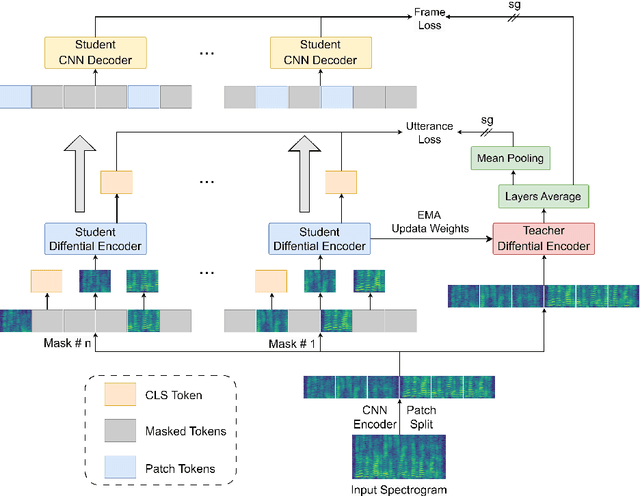
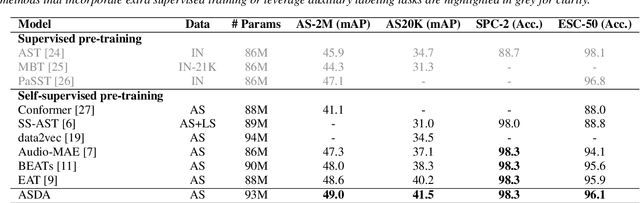
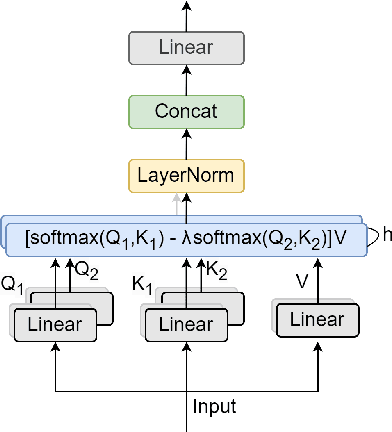
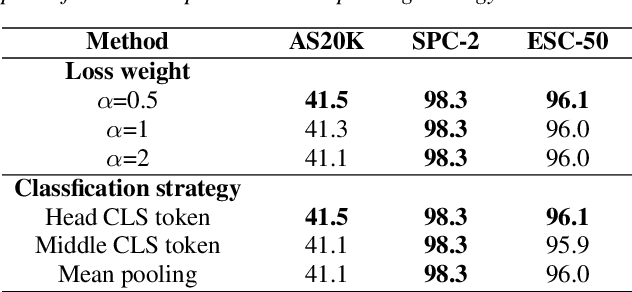
In recent advancements in audio self-supervised representation learning, the standard Transformer architecture has emerged as the predominant approach, yet its attention mechanism often allocates a portion of attention weights to irrelevant information, potentially impairing the model's discriminative ability. To address this, we introduce a differential attention mechanism, which effectively mitigates ineffective attention allocation through the integration of dual-softmax operations and appropriately tuned differential coefficients. Experimental results demonstrate that our ASDA model achieves state-of-the-art (SOTA) performance across multiple benchmarks, including audio classification (49.0% mAP on AS-2M, 41.5% mAP on AS20K), keyword spotting (98.3% accuracy on SPC-2), and environmental sound classification (96.1% accuracy on ESC-50). These results highlight ASDA's effectiveness in audio tasks, paving the way for broader applications.
PrimeK-Net: Multi-scale Spectral Learning via Group Prime-Kernel Convolutional Neural Networks for Single Channel Speech Enhancement
Feb 27, 2025Single-channel speech enhancement is a challenging ill-posed problem focused on estimating clean speech from degraded signals. Existing studies have demonstrated the competitive performance of combining convolutional neural networks (CNNs) with Transformers in speech enhancement tasks. However, existing frameworks have not sufficiently addressed computational efficiency and have overlooked the natural multi-scale distribution of the spectrum. Additionally, the potential of CNNs in speech enhancement has yet to be fully realized. To address these issues, this study proposes a Deep Separable Dilated Dense Block (DSDDB) and a Group Prime Kernel Feedforward Channel Attention (GPFCA) module. Specifically, the DSDDB introduces higher parameter and computational efficiency to the Encoder/Decoder of existing frameworks. The GPFCA module replaces the position of the Conformer, extracting deep temporal and frequency features of the spectrum with linear complexity. The GPFCA leverages the proposed Group Prime Kernel Feedforward Network (GPFN) to integrate multi-granularity long-range, medium-range, and short-range receptive fields, while utilizing the properties of prime numbers to avoid periodic overlap effects. Experimental results demonstrate that PrimeK-Net, proposed in this study, achieves state-of-the-art (SOTA) performance on the VoiceBank+Demand dataset, reaching a PESQ score of 3.61 with only 1.41M parameters.
Mamba-SEUNet: Mamba UNet for Monaural Speech Enhancement
Dec 21, 2024In recent speech enhancement (SE) research, transformer and its variants have emerged as the predominant methodologies. However, the quadratic complexity of the self-attention mechanism imposes certain limitations on practical deployment. Mamba, as a novel state-space model (SSM), has gained widespread application in natural language processing and computer vision due to its strong capabilities in modeling long sequences and relatively low computational complexity. In this work, we introduce Mamba-SEUNet, an innovative architecture that integrates Mamba with U-Net for SE tasks. By leveraging bidirectional Mamba to model forward and backward dependencies of speech signals at different resolutions, and incorporating skip connections to capture multi-scale information, our approach achieves state-of-the-art (SOTA) performance. Experimental results on the VCTK+DEMAND dataset indicate that Mamba-SEUNet attains a PESQ score of 3.59, while maintaining low computational complexity. When combined with the Perceptual Contrast Stretching technique, Mamba-SEUNet further improves the PESQ score to 3.73.
Dense-TSNet: Dense Connected Two-Stage Structure for Ultra-Lightweight Speech Enhancement
Sep 18, 2024



Speech enhancement aims to improve speech quality and intelligibility in noisy environments. Recent advancements have concentrated on deep neural networks, particularly employing the Two-Stage (TS) architecture to enhance feature extraction. However, the complexity and size of these models remain significant, which limits their applicability in resource-constrained scenarios. Designing models suitable for edge devices presents its own set of challenges. Narrow lightweight models often encounter performance bottlenecks due to uneven loss landscapes. Additionally, advanced operators such as Transformers or Mamba may lack the practical adaptability and efficiency that convolutional neural networks (CNNs) offer in real-world deployments. To address these challenges, we propose Dense-TSNet, an innovative ultra-lightweight speech enhancement network. Our approach employs a novel Dense Two-Stage (Dense-TS) architecture, which, compared to the classic Two-Stage architecture, ensures more robust refinement of the objective function in the later training stages. This leads to improved final performance, addressing the early convergence limitations of the baseline model. We also introduce the Multi-View Gaze Block (MVGB), which enhances feature extraction by incorporating global, channel, and local perspectives through convolutional neural networks (CNNs). Furthermore, we discuss how the choice of loss function impacts perceptual quality. Dense-TSNet demonstrates promising performance with a compact model size of around 14K parameters, making it particularly well-suited for deployment in resource-constrained environments.
Whole Heart Perfusion with High-Multiband Simultaneous Multislice Imaging via Linear Phase Modulated Extended Field of View (SMILE)
Sep 06, 2024Purpose: To develop a simultaneous multislice (SMS) first-pass perfusion technique that can achieve whole heart coverage with high multi-band factors, while avoiding the issue of slice leakage. Methods: The proposed Simultaneous Multislice Imaging via Linear phase modulated Extended field of view (SMILE) treats the SMS acquisition and reconstruction within an extended field of view framework, allowing arbitrarily under-sampling of phase encoding lines of the extended k-space matrix and enabling the direct application of 2D parallel imaging reconstruction techniques. We presented a theoretical framework that offers insights into the performance of SMILE. We performed retrospective comparison on 28 subjects and prospective perfusion experiments on 49 patients undergoing routine clinical CMR studies with SMILE at multiband (MB) factors of 3-5, with a total acceleration factor ($R$) of 8 and 10 respectively, and compared SMILE to conventional SMS techniques using standard FOV 2D CAIPI acquisition and standard 2D slice separation techniques including split-slice GRAPPA and ROCK-SPIRiT. Results: Retrospective studies demonstrated 5.2 to 8.0 dB improvement in signal to error ratio (SER) of SMILE over CAIPI perfusion. Prospective studies showed good image quality with grades of 4.5 $\pm$ 0.5 for MB=3, $R$=8 and 3.6 $\pm$ 0.8 for MB=5, $R$=10. (5-point Likert Scale) Conclusion: The theoretical derivation and experimental results validate the SMILE's improved performance at high acceleration and MB factors as compared to the existing 2D CAIPI SMS acquisition and reconstruction techniques for first-pass myocardial perfusion imaging.
Research on Autonomous Driving Decision-making Strategies based Deep Reinforcement Learning
Aug 06, 2024



The behavior decision-making subsystem is a key component of the autonomous driving system, which reflects the decision-making ability of the vehicle and the driver, and is an important symbol of the high-level intelligence of the vehicle. However, the existing rule-based decision-making schemes are limited by the prior knowledge of designers, and it is difficult to cope with complex and changeable traffic scenarios. In this work, an advanced deep reinforcement learning model is adopted, which can autonomously learn and optimize driving strategies in a complex and changeable traffic environment by modeling the driving decision-making process as a reinforcement learning problem. Specifically, we used Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) for comparative experiments. DQN guides the agent to choose the best action by approximating the state-action value function, while PPO improves the decision-making quality by optimizing the policy function. We also introduce improvements in the design of the reward function to promote the robustness and adaptability of the model in real-world driving situations. Experimental results show that the decision-making strategy based on deep reinforcement learning has better performance than the traditional rule-based method in a variety of driving tasks.
MUSE: Flexible Voiceprint Receptive Fields and Multi-Path Fusion Enhanced Taylor Transformer for U-Net-based Speech Enhancement
Jun 07, 2024Achieving a balance between lightweight design and high performance remains a challenging task for speech enhancement. In this paper, we introduce Multi-path Enhanced Taylor (MET) Transformer based U-net for Speech Enhancement (MUSE), a lightweight speech enhancement network built upon the Unet architecture. Our approach incorporates a novel Multi-path Enhanced Taylor (MET) Transformer block, which integrates Deformable Embedding (DE) to enable flexible receptive fields for voiceprints. The MET Transformer is uniquely designed to fuse Channel and Spatial Attention (CSA) branches, facilitating channel information exchange and addressing spatial attention deficits within the Taylor-Transformer framework. Through extensive experiments conducted on the VoiceBank+DEMAND dataset, we demonstrate that MUSE achieves competitive performance while significantly reducing both training and deployment costs, boasting a mere 0.51M parameters.