 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CSP: Self-Supervised Contrastive Spatial Pre-Training for Geospatial-Visual Representations
May 09, 2023
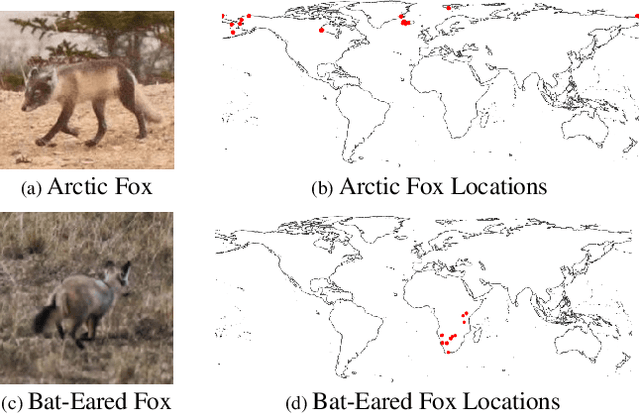
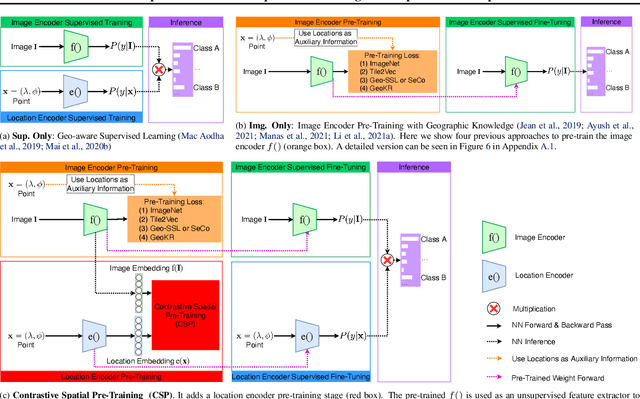
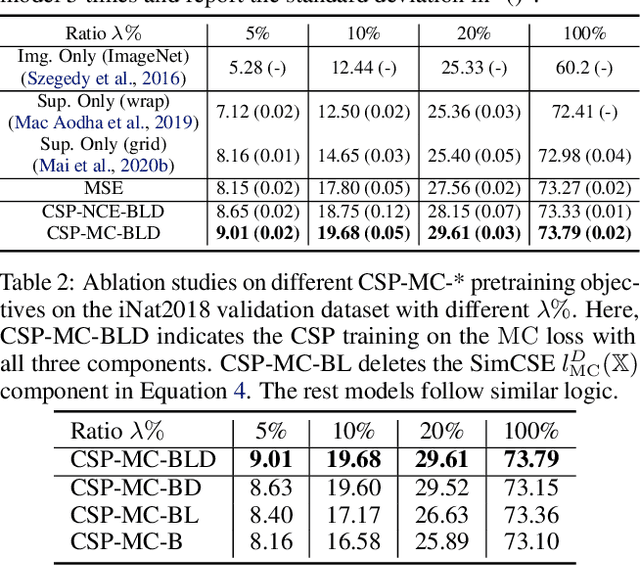

Geo-tagged images are publicly available in large quantities, whereas labels such as object classes are rather scarce and expensive to collect. Meanwhile, contrastive learning has achieved tremendous success in various natural image and language tasks with limited labeled data. However, existing methods fail to fully leverage geospatial information, which can be paramount to distinguishing objects that are visually similar. To directly leverage the abundant geospatial information associated with images in pre-training, fine-tuning, and inference stages, we present Contrastive Spatial Pre-Training (CSP), a self-supervised learning framework for geo-tagged images. We use a dual-encoder to separately encode the images and their corresponding geo-locations, and use contrastive objectives to learn effective location representations from images, which can be transferred to downstream supervised tasks such as image classification. Experiments show that CSP can improve model performance on both iNat2018 and fMoW datasets. Especially, on iNat2018, CSP significantly boosts the model performance with 10-34% relative improvement with various labeled training data sampling ratios.
ImageBind: One Embedding Space To Bind Them All
May 09, 2023


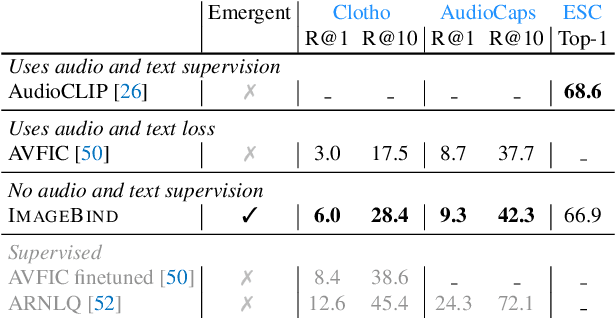
We present ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. We show that all combinations of paired data are not necessary to train such a joint embedding, and only image-paired data is sufficient to bind the modalities together. ImageBind can leverage recent large scale vision-language models, and extends their zero-shot capabilities to new modalities just by using their natural pairing with images. It enables novel emergent applications 'out-of-the-box' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation. The emergent capabilities improve with the strength of the image encoder and we set a new state-of-the-art on emergent zero-shot recognition tasks across modalities, outperforming specialist supervised models. Finally, we show strong few-shot recognition results outperforming prior work, and that ImageBind serves as a new way to evaluate vision models for visual and non-visual tasks.
Beyond Pretrained Features: Noisy Image Modeling Provides Adversarial Defense
Feb 02, 2023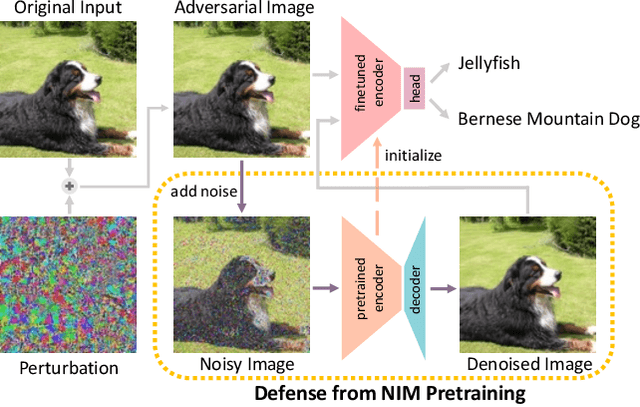
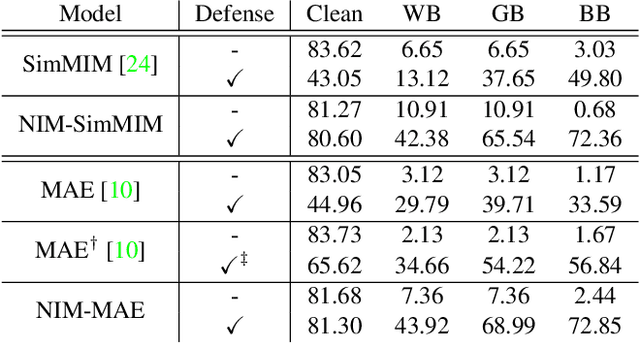
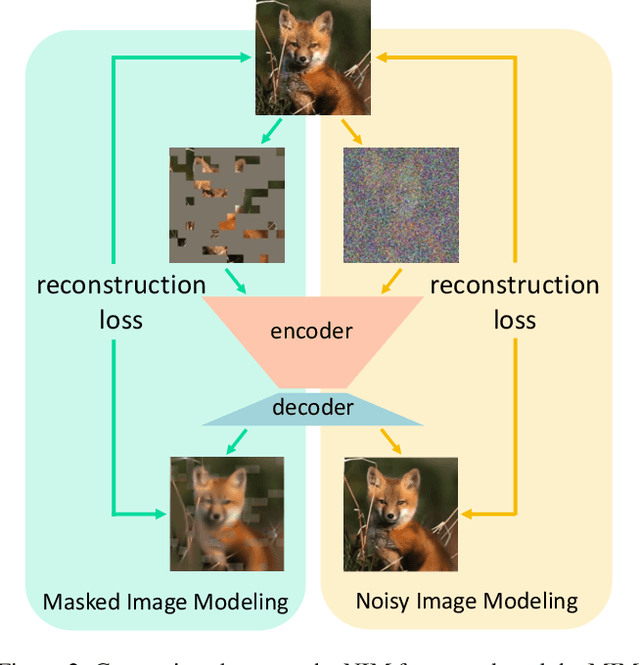
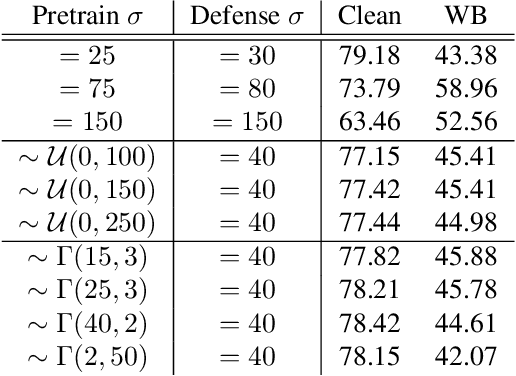
Masked Image Modeling (MIM) has been a prevailing framework for self-supervised visual representation learning. Within the pretraining-finetuning paradigm, the MIM framework trains an encoder by reconstructing masked image patches with the help of a decoder which would be abandoned when the encoder is used for finetuning. Despite its state-of-the-art performance on clean images, MIM models are vulnerable to adversarial attacks, limiting its real-world application, and few studies have focused on this issue. In this paper, we have discovered that noisy image modeling (NIM), a variant of MIM that uses denoising as the pre-text task, provides not only good pretrained visual features, but also effective adversarial defense for downstream models. To achieve a better accuracy-robustness trade-off, we further propose to sample the hyperparameter that controls the reconstruction difficulty from random distributions instead of setting it globally, and fine-tune downstream networks with denoised images. Experimental results demonstrate that our pre-trained denoising autoencoders are effective against different white-box, gray-box, and black-box attacks without being trained with adversarial images, while not harming the clean accuracy of fine-tuned models. Source code and models will be made available.
Pre-training Contextualized World Models with In-the-wild Videos for Reinforcement Learning
May 29, 2023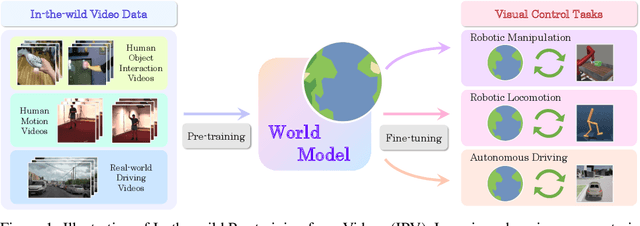
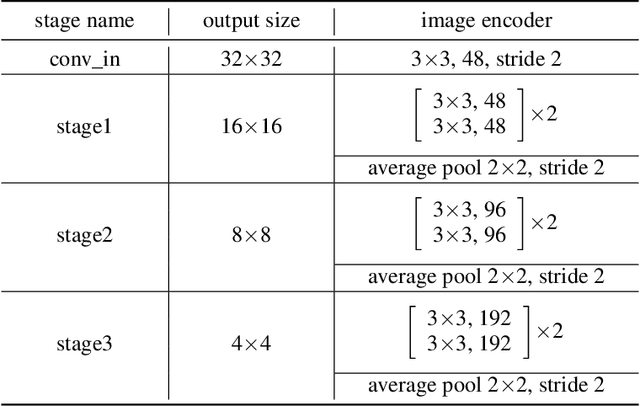
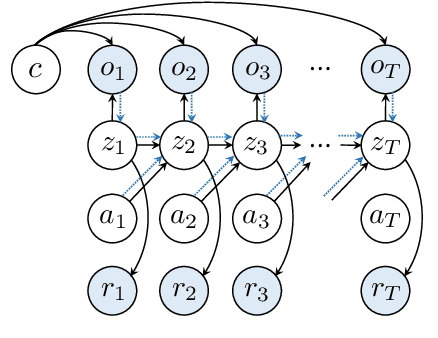

Unsupervised pre-training methods utilizing large and diverse datasets have achieved tremendous success across a range of domains. Recent work has investigated such unsupervised pre-training methods for model-based reinforcement learning (MBRL) but is limited to domain-specific or simulated data. In this paper, we study the problem of pre-training world models with abundant in-the-wild videos for efficient learning of downstream visual control tasks. However, in-the-wild videos are complicated with various contextual factors, such as intricate backgrounds and textured appearance, which precludes a world model from extracting shared world knowledge to generalize better. To tackle this issue, we introduce Contextualized World Models (ContextWM) that explicitly model both the context and dynamics to overcome the complexity and diversity of in-the-wild videos and facilitate knowledge transfer between distinct scenes. Specifically, a contextualized extension of the latent dynamics model is elaborately realized by incorporating a context encoder to retain contextual information and empower the image decoder, which allows the latent dynamics model to concentrate on essential temporal variations. Our experiments show that in-the-wild video pre-training equipped with ContextWM can significantly improve the sample-efficiency of MBRL in various domains, including robotic manipulation, locomotion, and autonomous driving.
propnet: Propagating 2D Annotation to 3D Segmentation for Gastric Tumors on CT Scans
May 29, 2023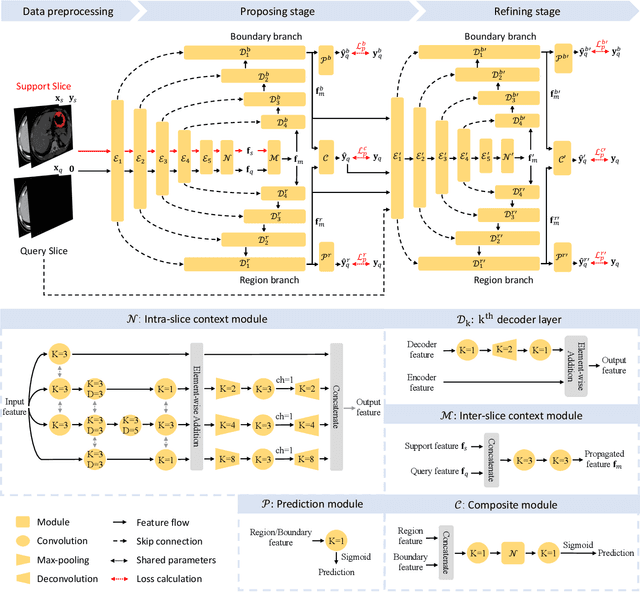
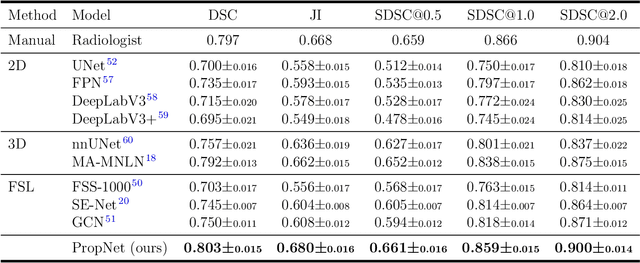
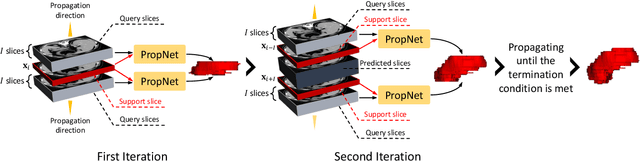

**Background:** Accurate 3D CT scan segmentation of gastric tumors is pivotal for diagnosis and treatment. The challenges lie in the irregular shapes, blurred boundaries of tumors, and the inefficiency of existing methods. **Purpose:** We conducted a study to introduce a model, utilizing human-guided knowledge and unique modules, to address the challenges of 3D tumor segmentation. **Methods:** We developed the PropNet framework, propagating radiologists' knowledge from 2D annotations to the entire 3D space. This model consists of a proposing stage for coarse segmentation and a refining stage for improved segmentation, using two-way branches for enhanced performance and an up-down strategy for efficiency. **Results:** With 98 patient scans for training and 30 for validation, our method achieves a significant agreement with manual annotation (Dice of 0.803) and improves efficiency. The performance is comparable in different scenarios and with various radiologists' annotations (Dice between 0.785 and 0.803). Moreover, the model shows improved prognostic prediction performance (C-index of 0.620 vs. 0.576) on an independent validation set of 42 patients with advanced gastric cancer. **Conclusions:** Our model generates accurate tumor segmentation efficiently and stably, improving prognostic performance and reducing high-throughput image reading workload. This model can accelerate the quantitative analysis of gastric tumors and enhance downstream task performance.
Learning Gradually Non-convex Image Priors Using Score Matching
Feb 21, 2023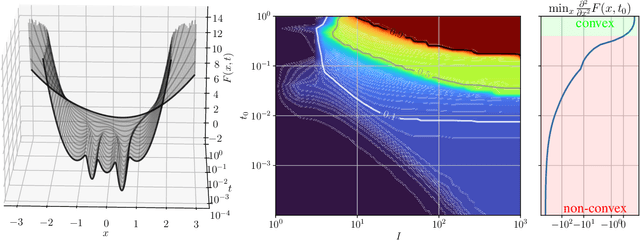
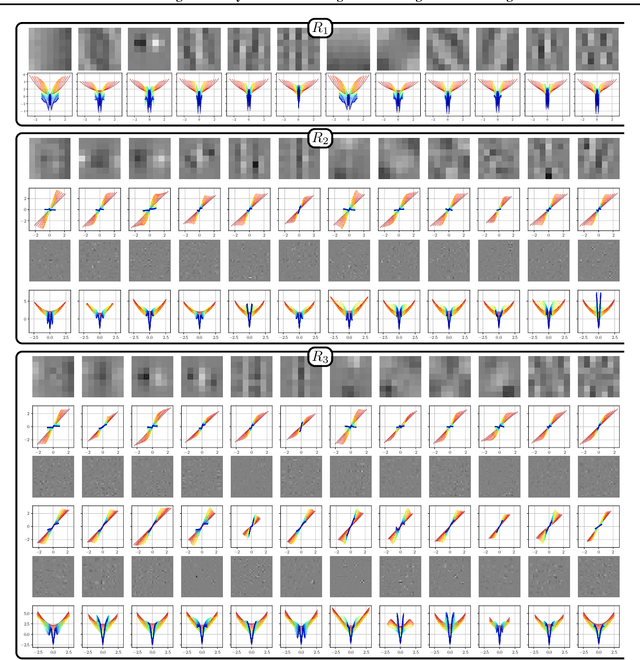
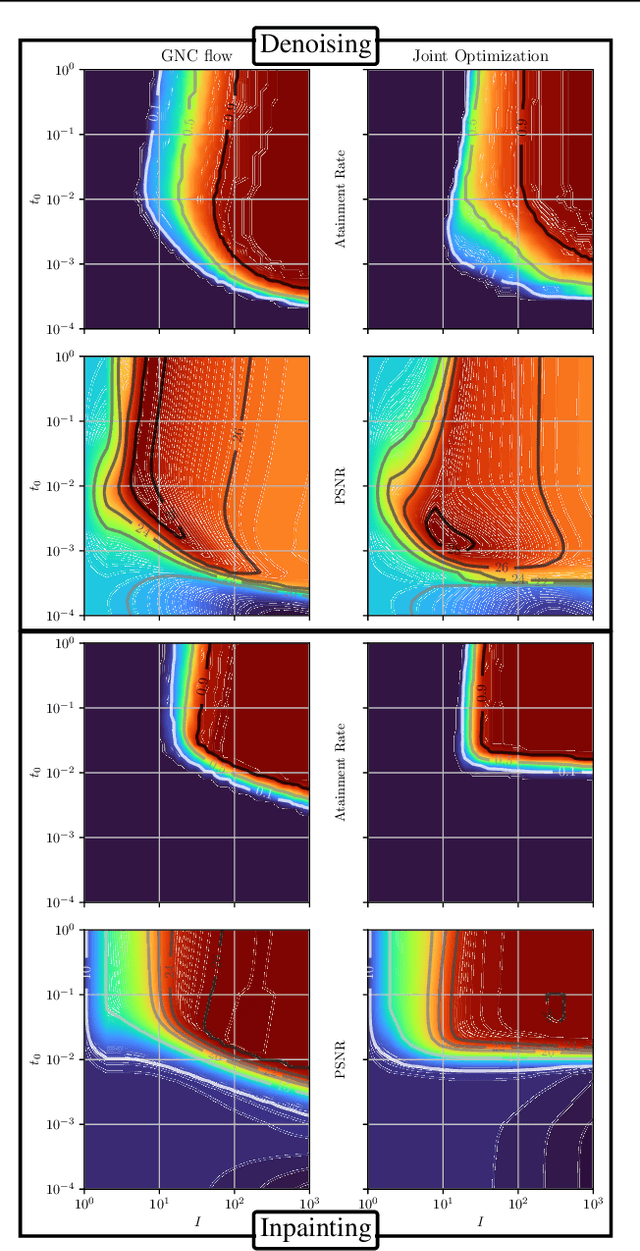
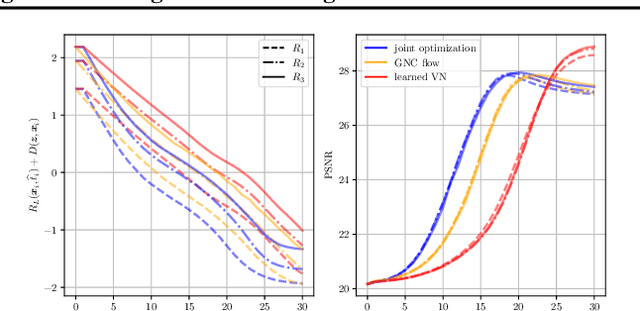
In this paper, we propose a unified framework of denoising score-based models in the context of graduated non-convex energy minimization. We show that for sufficiently large noise variance, the associated negative log density -- the energy -- becomes convex. Consequently, denoising score-based models essentially follow a graduated non-convexity heuristic. We apply this framework to learning generalized Fields of Experts image priors that approximate the joint density of noisy images and their associated variances. These priors can be easily incorporated into existing optimization algorithms for solving inverse problems and naturally implement a fast and robust graduated non-convexity mechanism.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023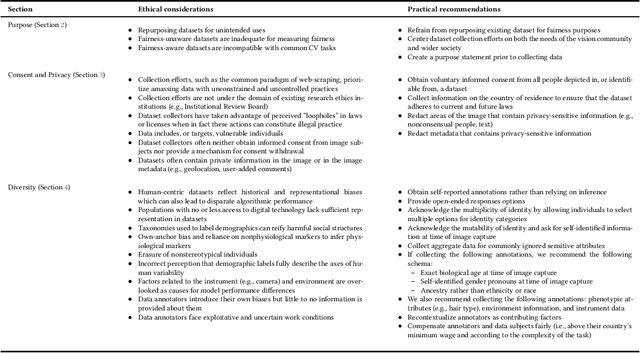
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.
DAFD: Domain Adaptation via Feature Disentanglement for Image Classification
Jan 30, 2023
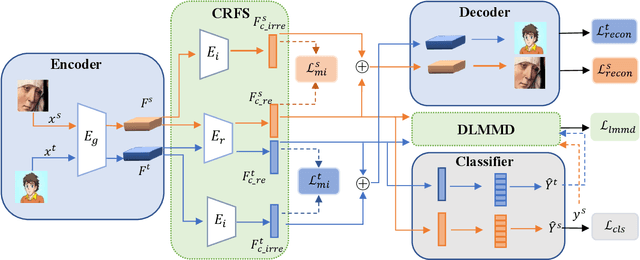
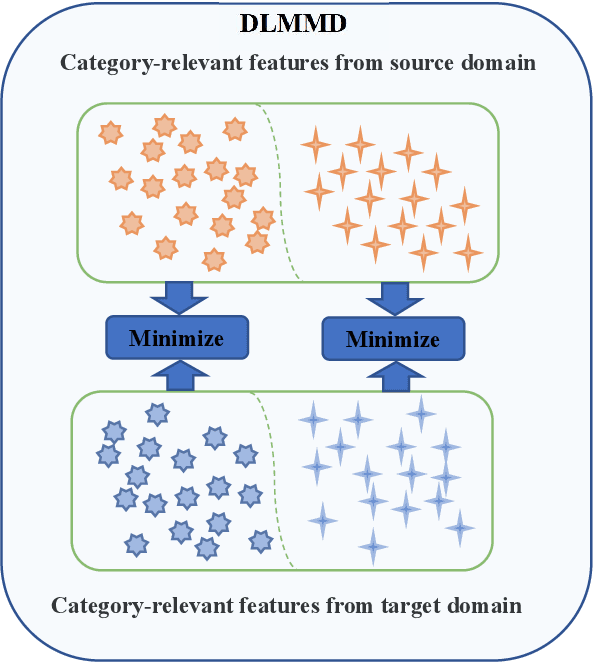

A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
Detect Any Shadow: Segment Anything for Video Shadow Detection
May 26, 2023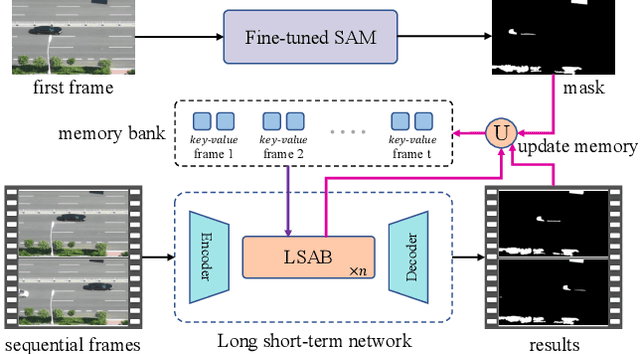
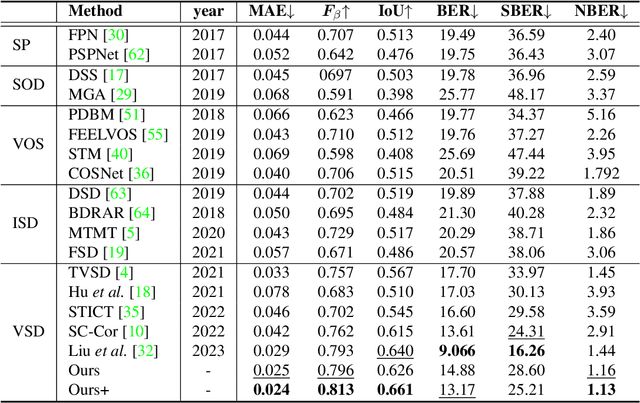
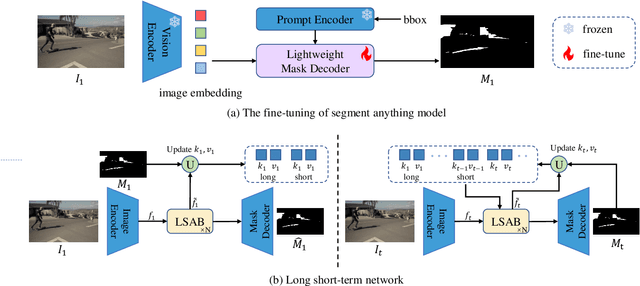
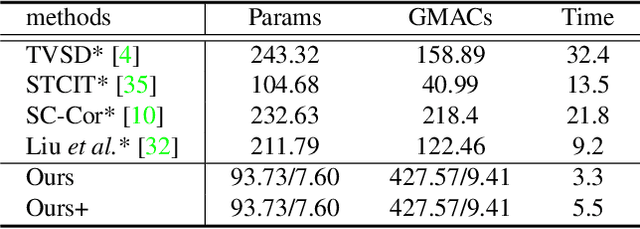
Segment anything model (SAM) has achieved great success in the field of natural image segmentation. Nevertheless, SAM tends to classify shadows as background, resulting in poor segmentation performance for shadow detection task. In this paper, we propose an simple but effective approach for fine tuning SAM to detect shadows. Additionally, we also combine it with long short-term attention mechanism to extend its capabilities to video shadow detection. Specifically, we first fine tune SAM by utilizing shadow data combined with sparse prompts and apply the fine-tuned model to detect a specific frame (e.g., first frame) in the video with a little user assistance. Subsequently, using the detected frame as a reference, we employ a long short-term network to learn spatial correlations between distant frames and temporal consistency between contiguous frames, thereby achieving shadow information propagation across frames. Extensive experimental results demonstrate that our method outperforms the state-of-the-art techniques, with improvements of 17.2% and 3.3% in terms of MAE and IoU, respectively, validating the effectiveness of our method.
GVdoc: Graph-based Visual Document Classification
May 26, 2023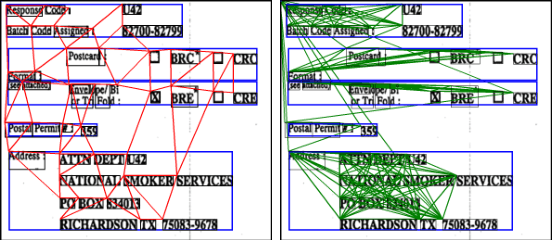
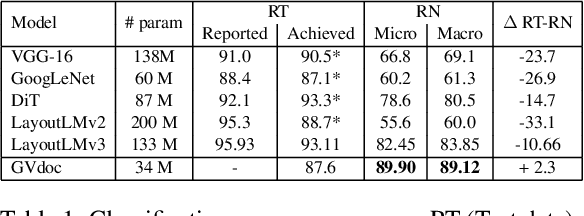
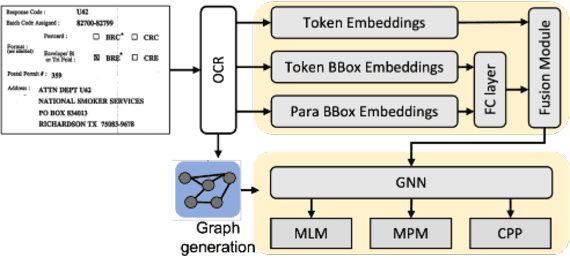

The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.