 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothTurn: Learning to Turn Smoothly for Agile Navigation with Quadrupedal Robots
Mar 13, 2026Quadrupedal robots show great potential for valuable real-world applications such as fire rescue and industrial inspection. Such applications often require urgency and the ability to navigate agilely, which in turn demands the capability to change directions smoothly while running in high speed. Existing approaches for agile navigation typically learn a single-goal reaching policy by encouraging the robot to stay at the target position after reaching there. As a result, when the policy is used to reach sequential goals that require changing directions, it cannot anticipate upcoming maneuvers or maintain momentum across the switch of goals, thereby preventing the robot from fully exploiting its agility potential. In this work, we formulate the task as sequential local navigation, extending the single-goal-conditioned local navigation formulation in prior work. We then introduce SmoothTurn, a learning-based control framework that learns to turn smoothly while running rapidly for agile sequential local navigation. The framework adopts a novel sequential goal-reaching reward, an expanded observation space with a lookahead window for future goals, and an automatic goal curriculum that progressively expands the difficulty of sampled goal sequences based on the goal-reaching performance. The trained policy can be directly deployed on real quadrupedal robots with onboard sensors and computation. Both simulation and real-world empirical results show that SmoothTurn learns an agile locomotion policy that performs smooth turning across goals, with emergent behaviors such as controlling momentum when switching goals, facing towards the future goal in advance, and planning efficient paths. We have provided video demos of the learned motions in the supplementary materials. The source code and trained policies will be made available upon acceptance.
Beyond Pretrained Features: Noisy Image Modeling Provides Adversarial Defense
Feb 02, 2023



Masked Image Modeling (MIM) has been a prevailing framework for self-supervised visual representation learning. Within the pretraining-finetuning paradigm, the MIM framework trains an encoder by reconstructing masked image patches with the help of a decoder which would be abandoned when the encoder is used for finetuning. Despite its state-of-the-art performance on clean images, MIM models are vulnerable to adversarial attacks, limiting its real-world application, and few studies have focused on this issue. In this paper, we have discovered that noisy image modeling (NIM), a variant of MIM that uses denoising as the pre-text task, provides not only good pretrained visual features, but also effective adversarial defense for downstream models. To achieve a better accuracy-robustness trade-off, we further propose to sample the hyperparameter that controls the reconstruction difficulty from random distributions instead of setting it globally, and fine-tune downstream networks with denoised images. Experimental results demonstrate that our pre-trained denoising autoencoders are effective against different white-box, gray-box, and black-box attacks without being trained with adversarial images, while not harming the clean accuracy of fine-tuned models. Source code and models will be made available.
Towards Interpretable Deep Networks for Monocular Depth Estimation
Aug 11, 2021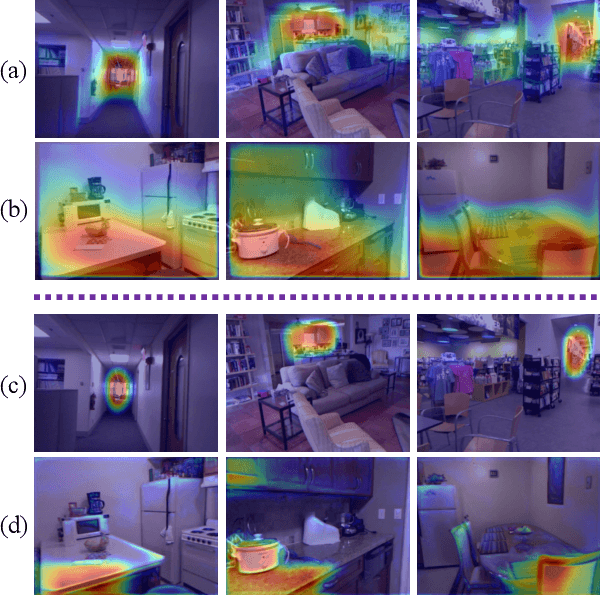

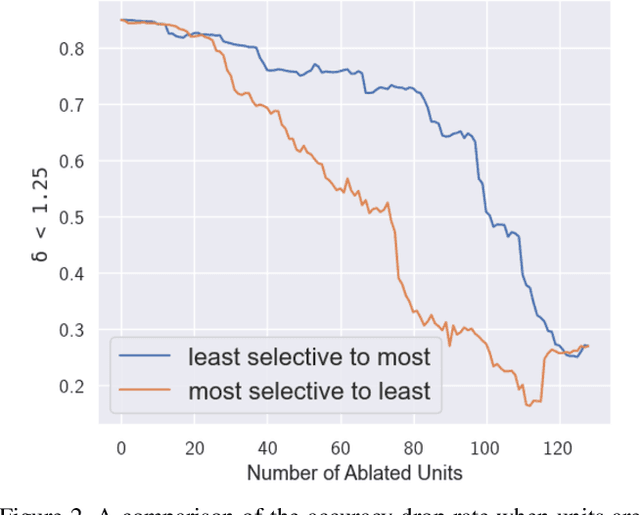
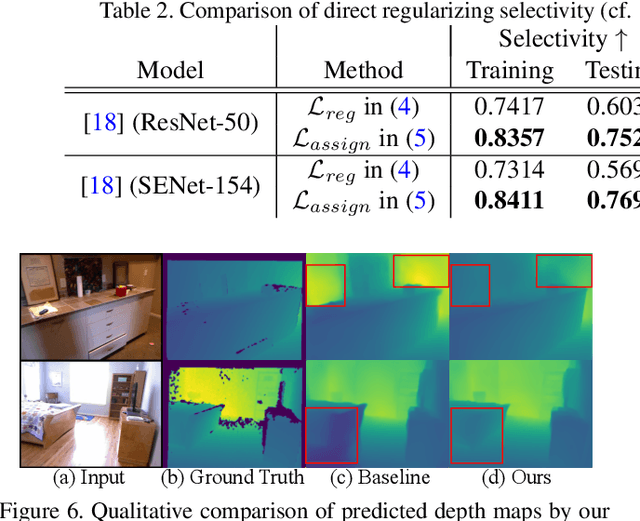
Deep networks for Monocular Depth Estimation (MDE) have achieved promising performance recently and it is of great importance to further understand the interpretability of these networks. Existing methods attempt to provide posthoc explanations by investigating visual cues, which may not explore the internal representations learned by deep networks. In this paper, we find that some hidden units of the network are selective to certain ranges of depth, and thus such behavior can be served as a way to interpret the internal representations. Based on our observations, we quantify the interpretability of a deep MDE network by the depth selectivity of its hidden units. Moreover, we then propose a method to train interpretable MDE deep networks without changing their original architectures, by assigning a depth range for each unit to select. Experimental results demonstrate that our method is able to enhance the interpretability of deep MDE networks by largely improving the depth selectivity of their units, while not harming or even improving the depth estimation accuracy. We further provide a comprehensive analysis to show the reliability of selective units, the applicability of our method on different layers, models, and datasets, and a demonstration on analysis of model error. Source code and models are available at https://github.com/youzunzhi/InterpretableMDE .