 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Looped Transformers
May 22, 2026We introduce training-free looped transformers, in which a lightweight inference-time wrapper loops a contiguous mid-stack block of layers of a frozen checkpoint without additional fine-tuning, continued training, or architectural changes. Unlike prior looped transformer methods that train with the looped structure end-to-end, we retrofit recurrence onto pretrained models at test time. We show that naive block reapplication usually degrades performance, highlighting the importance of the loop application strategy. Motivated by viewing a pre-norm transformer block as a forward Euler step on an ODE, we instead treat looping as a refinement of the same approximation, replacing one large update with smaller damped sub-steps. Across seven dense, sparse MoE, and MLA+MoE model families, our method improves Qwen3-4B-Instruct by +2.64 pp on MMLU-Pro, Qwen3-30B-A3B-Instruct by +1.14 pp on CommonsenseQA, and Moonlight-16B-A3B-Instruct by +1.20 pp on OpenBookQA.
Cautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
GAIR: Improving Multimodal Geo-Foundation Model with Geo-Aligned Implicit Representations
Mar 20, 2025



Advancements in vision and language foundation models have inspired the development of geo-foundation models (GeoFMs), enhancing performance across diverse geospatial tasks. However, many existing GeoFMs primarily focus on overhead remote sensing (RS) data while neglecting other data modalities such as ground-level imagery. A key challenge in multimodal GeoFM development is to explicitly model geospatial relationships across modalities, which enables generalizability across tasks, spatial scales, and temporal contexts. To address these limitations, we propose GAIR, a novel multimodal GeoFM architecture integrating overhead RS data, street view (SV) imagery, and their geolocation metadata. We utilize three factorized neural encoders to project an SV image, its geolocation, and an RS image into the embedding space. The SV image needs to be located within the RS image's spatial footprint but does not need to be at its geographic center. In order to geographically align the SV image and RS image, we propose a novel implicit neural representations (INR) module that learns a continuous RS image representation and looks up the RS embedding at the SV image's geolocation. Next, these geographically aligned SV embedding, RS embedding, and location embedding are trained with contrastive learning objectives from unlabeled data. We evaluate GAIR across 10 geospatial tasks spanning RS image-based, SV image-based, and location embedding-based benchmarks. Experimental results demonstrate that GAIR outperforms state-of-the-art GeoFMs and other strong baselines, highlighting its effectiveness in learning generalizable and transferable geospatial representations.
TorchSpatial: A Location Encoding Framework and Benchmark for Spatial Representation Learning
Jun 21, 2024Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding, which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 4 geo-aware image regression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models' overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of different location encoders. We believe TorchSpatial will foster future advancement of spatial representation learning and spatial fairness in GeoAI research. The TorchSpatial model framework, LocBench, and Geo-Bias Score evaluation framework are available at https://github.com/seai-lab/TorchSpatial.
MC-GTA: Metric-Constrained Model-Based Clustering using Goodness-of-fit Tests with Autocorrelations
May 28, 2024



A wide range of (multivariate) temporal (1D) and spatial (2D) data analysis tasks, such as grouping vehicle sensor trajectories, can be formulated as clustering with given metric constraints. Existing metric-constrained clustering algorithms overlook the rich correlation between feature similarity and metric distance, i.e., metric autocorrelation. The model-based variations of these clustering algorithms (e.g. TICC and STICC) achieve SOTA performance, yet suffer from computational instability and complexity by using a metric-constrained Expectation-Maximization procedure. In order to address these two problems, we propose a novel clustering algorithm, MC-GTA (Model-based Clustering via Goodness-of-fit Tests with Autocorrelations). Its objective is only composed of pairwise weighted sums of feature similarity terms (square Wasserstein-2 distance) and metric autocorrelation terms (a novel multivariate generalization of classic semivariogram). We show that MC-GTA is effectively minimizing the total hinge loss for intra-cluster observation pairs not passing goodness-of-fit tests, i.e., statistically not originating from the same distribution. Experiments on 1D/2D synthetic and real-world datasets demonstrate that MC-GTA successfully incorporates metric autocorrelation. It outperforms strong baselines by large margins (up to 14.3% in ARI and 32.1% in NMI) with faster and stabler optimization (>10x speedup).
Img2Loc: Revisiting Image Geolocalization using Multi-modality Foundation Models and Image-based Retrieval-Augmented Generation
Mar 28, 2024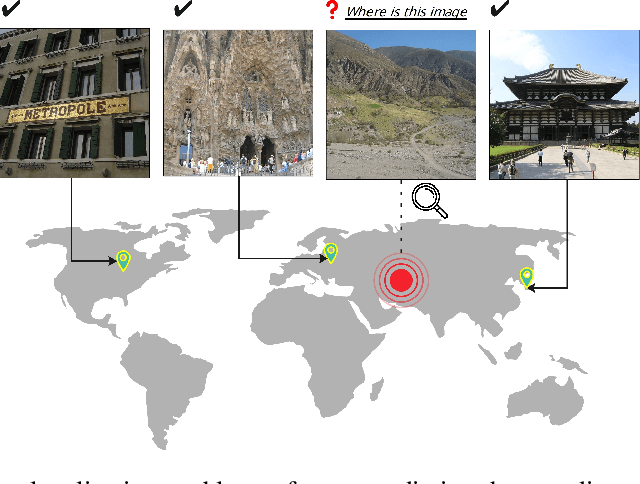
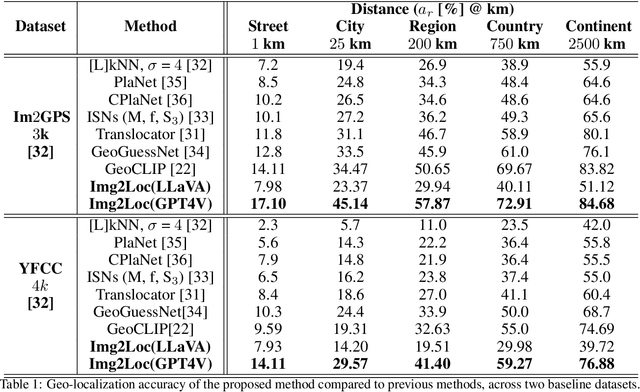
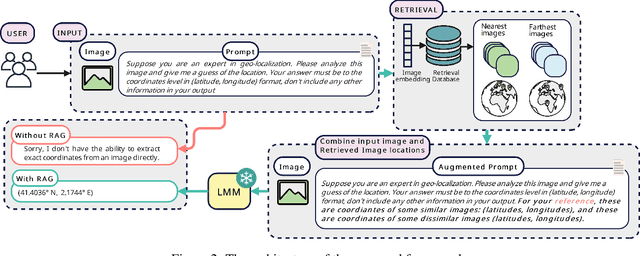
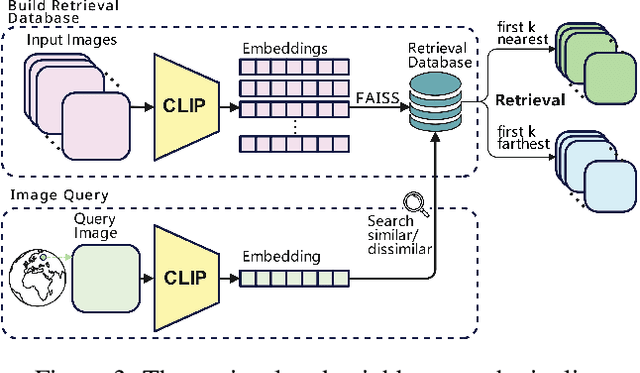
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.
SSIF: Learning Continuous Image Representation for Spatial-Spectral Super-Resolution
Sep 30, 2023



Existing digital sensors capture images at fixed spatial and spectral resolutions (e.g., RGB, multispectral, and hyperspectral images), and each combination requires bespoke machine learning models. Neural Implicit Functions partially overcome the spatial resolution challenge by representing an image in a resolution-independent way. However, they still operate at fixed, pre-defined spectral resolutions. To address this challenge, we propose Spatial-Spectral Implicit Function (SSIF), a neural implicit model that represents an image as a function of both continuous pixel coordinates in the spatial domain and continuous wavelengths in the spectral domain. We empirically demonstrate the effectiveness of SSIF on two challenging spatio-spectral super-resolution benchmarks. We observe that SSIF consistently outperforms state-of-the-art baselines even when the baselines are allowed to train separate models at each spectral resolution. We show that SSIF generalizes well to both unseen spatial resolutions and spectral resolutions. Moreover, SSIF can generate high-resolution images that improve the performance of downstream tasks (e.g., land use classification) by 1.7%-7%.
Sphere2Vec: A General-Purpose Location Representation Learning over a Spherical Surface for Large-Scale Geospatial Predictions
Jul 03, 2023



Generating learning-friendly representations for points in space is a fundamental and long-standing problem in ML. Recently, multi-scale encoding schemes (such as Space2Vec and NeRF) were proposed to directly encode any point in 2D/3D Euclidean space as a high-dimensional vector, and has been successfully applied to various geospatial prediction and generative tasks. However, all current 2D and 3D location encoders are designed to model point distances in Euclidean space. So when applied to large-scale real-world GPS coordinate datasets, which require distance metric learning on the spherical surface, both types of models can fail due to the map projection distortion problem (2D) and the spherical-to-Euclidean distance approximation error (3D). To solve these problems, we propose a multi-scale location encoder called Sphere2Vec which can preserve spherical distances when encoding point coordinates on a spherical surface. We developed a unified view of distance-reserving encoding on spheres based on the DFS. We also provide theoretical proof that the Sphere2Vec preserves the spherical surface distance between any two points, while existing encoding schemes do not. Experiments on 20 synthetic datasets show that Sphere2Vec can outperform all baseline models on all these datasets with up to 30.8% error rate reduction. We then apply Sphere2Vec to three geo-aware image classification tasks - fine-grained species recognition, Flickr image recognition, and remote sensing image classification. Results on 7 real-world datasets show the superiority of Sphere2Vec over multiple location encoders on all three tasks. Further analysis shows that Sphere2Vec outperforms other location encoder models, especially in the polar regions and data-sparse areas because of its nature for spherical surface distance preservation. Code and data are available at https://gengchenmai.github.io/sphere2vec-website/.
* 30 Pages, 16 figures. Accepted to ISPRS Journal of Photogrammetry and Remote Sensing
CSP: Self-Supervised Contrastive Spatial Pre-Training for Geospatial-Visual Representations
May 09, 2023



Geo-tagged images are publicly available in large quantities, whereas labels such as object classes are rather scarce and expensive to collect. Meanwhile, contrastive learning has achieved tremendous success in various natural image and language tasks with limited labeled data. However, existing methods fail to fully leverage geospatial information, which can be paramount to distinguishing objects that are visually similar. To directly leverage the abundant geospatial information associated with images in pre-training, fine-tuning, and inference stages, we present Contrastive Spatial Pre-Training (CSP), a self-supervised learning framework for geo-tagged images. We use a dual-encoder to separately encode the images and their corresponding geo-locations, and use contrastive objectives to learn effective location representations from images, which can be transferred to downstream supervised tasks such as image classification. Experiments show that CSP can improve model performance on both iNat2018 and fMoW datasets. Especially, on iNat2018, CSP significantly boosts the model performance with 10-34% relative improvement with various labeled training data sampling ratios.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023



Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.