 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
May 13, 2026Multi-reference image generation aims to synthesize images from textual instructions while faithfully preserving subject identities from multiple reference images. Existing VLM-enhanced diffusion models commonly rely on decoupled visual conditioning: semantic ViT features are processed by the VLM for instruction understanding, whereas appearance-rich VAE features are injected later into the diffusion backbone. Despite its intuitive design, this separation makes it difficult for the model to associate each semantically grounded subject with visual details from the correct reference image. As a result, the model may recognize which subject is being referred to, but fail to preserve its identity and fine-grained appearance, leading to attribute leakage and cross-reference confusion in complex multi-reference settings. To address this issue, we propose UniCustom, a unified visual conditioning framework that fuses ViT and VAE features before VLM encoding. This early fusion exposes the VLM to both semantic cues and appearance-rich details, enabling its hidden states to jointly encode the referred subject and corresponding visual appearance with only a lightweight linear fusion layer. To learn such unified representations, we adopt a two-stage training strategy: reconstruction-oriented pretraining that preserves reference-specific appearance details in the fused hidden states, followed by supervised finetuning on single- and multi-reference generation tasks. We further introduce a slot-wise binding regularization that encourages each image slot to preserve low-level details of its corresponding reference, thereby reducing cross-reference entanglement. Experiments on two multi-reference generation benchmarks demonstrate that UniCustom consistently improves subject consistency, instruction following, and compositional fidelity over strong baselines.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
MotionRL: Align Text-to-Motion Generation to Human Preferences with Multi-Reward Reinforcement Learning
Oct 09, 2024



We introduce MotionRL, the first approach to utilize Multi-Reward Reinforcement Learning (RL) for optimizing text-to-motion generation tasks and aligning them with human preferences. Previous works focused on improving numerical performance metrics on the given datasets, often neglecting the variability and subjectivity of human feedback. In contrast, our novel approach uses reinforcement learning to fine-tune the motion generator based on human preferences prior knowledge of the human perception model, allowing it to generate motions that better align human preferences. In addition, MotionRL introduces a novel multi-objective optimization strategy to approximate Pareto optimality between text adherence, motion quality, and human preferences. Extensive experiments and user studies demonstrate that MotionRL not only allows control over the generated results across different objectives but also significantly enhances performance across these metrics compared to other algorithms.
Hyper-Connections
Sep 29, 2024



We present hyper-connections, a simple yet effective method that can serve as an alternative to residual connections. This approach specifically addresses common drawbacks observed in residual connection variants, such as the seesaw effect between gradient vanishing and representation collapse. Theoretically, hyper-connections allow the network to adjust the strength of connections between features at different depths and dynamically rearrange layers. We conduct experiments focusing on the pre-training of large language models, including dense and sparse models, where hyper-connections show significant performance improvements over residual connections. Additional experiments conducted on vision tasks also demonstrate similar improvements. We anticipate that this method will be broadly applicable and beneficial across a wide range of AI problems.
MASA: Motion-aware Masked Autoencoder with Semantic Alignment for Sign Language Recognition
May 31, 2024



Sign language recognition (SLR) has long been plagued by insufficient model representation capabilities. Although current pre-training approaches have alleviated this dilemma to some extent and yielded promising performance by employing various pretext tasks on sign pose data, these methods still suffer from two primary limitations: 1) Explicit motion information is usually disregarded in previous pretext tasks, leading to partial information loss and limited representation capability. 2) Previous methods focus on the local context of a sign pose sequence, without incorporating the guidance of the global meaning of lexical signs. To this end, we propose a Motion-Aware masked autoencoder with Semantic Alignment (MASA) that integrates rich motion cues and global semantic information in a self-supervised learning paradigm for SLR. Our framework contains two crucial components, i.e., a motion-aware masked autoencoder (MA) and a momentum semantic alignment module (SA). Specifically, in MA, we introduce an autoencoder architecture with a motion-aware masked strategy to reconstruct motion residuals of masked frames, thereby explicitly exploring dynamic motion cues among sign pose sequences. Moreover, in SA, we embed our framework with global semantic awareness by aligning the embeddings of different augmented samples from the input sequence in the shared latent space. In this way, our framework can simultaneously learn local motion cues and global semantic features for comprehensive sign language representation. Furthermore, we conduct extensive experiments to validate the effectiveness of our method, achieving new state-of-the-art performance on four public benchmarks.
Learning Generalizable Human Motion Generator with Reinforcement Learning
May 24, 2024



Text-driven human motion generation, as one of the vital tasks in computer-aided content creation, has recently attracted increasing attention. While pioneering research has largely focused on improving numerical performance metrics on given datasets, practical applications reveal a common challenge: existing methods often overfit specific motion expressions in the training data, hindering their ability to generalize to novel descriptions like unseen combinations of motions. This limitation restricts their broader applicability. We argue that the aforementioned problem primarily arises from the scarcity of available motion-text pairs, given the many-to-many nature of text-driven motion generation. To tackle this problem, we formulate text-to-motion generation as a Markov decision process and present \textbf{InstructMotion}, which incorporate the trail and error paradigm in reinforcement learning for generalizable human motion generation. Leveraging contrastive pre-trained text and motion encoders, we delve into optimizing reward design to enable InstructMotion to operate effectively on both paired data, enhancing global semantic level text-motion alignment, and synthetic text-only data, facilitating better generalization to novel prompts without the need for ground-truth motion supervision. Extensive experiments on prevalent benchmarks and also our synthesized unpaired dataset demonstrate that the proposed InstructMotion achieves outstanding performance both quantitatively and qualitatively.
I$^2$MD: 3D Action Representation Learning with Inter- and Intra-modal Mutual Distillation
Oct 24, 2023



Recent progresses on self-supervised 3D human action representation learning are largely attributed to contrastive learning. However, in conventional contrastive frameworks, the rich complementarity between different skeleton modalities remains under-explored. Moreover, optimized with distinguishing self-augmented samples, models struggle with numerous similar positive instances in the case of limited action categories. In this work, we tackle the aforementioned problems by introducing a general Inter- and Intra-modal Mutual Distillation (I$^2$MD) framework. In I$^2$MD, we first re-formulate the cross-modal interaction as a Cross-modal Mutual Distillation (CMD) process. Different from existing distillation solutions that transfer the knowledge of a pre-trained and fixed teacher to the student, in CMD, the knowledge is continuously updated and bidirectionally distilled between modalities during pre-training. To alleviate the interference of similar samples and exploit their underlying contexts, we further design the Intra-modal Mutual Distillation (IMD) strategy, In IMD, the Dynamic Neighbors Aggregation (DNA) mechanism is first introduced, where an additional cluster-level discrimination branch is instantiated in each modality. It adaptively aggregates highly-correlated neighboring features, forming local cluster-level contrasting. Mutual distillation is then performed between the two branches for cross-level knowledge exchange. Extensive experiments on three datasets show that our approach sets a series of new records.
Masked Motion Predictors are Strong 3D Action Representation Learners
Aug 14, 2023



In 3D human action recognition, limited supervised data makes it challenging to fully tap into the modeling potential of powerful networks such as transformers. As a result, researchers have been actively investigating effective self-supervised pre-training strategies. In this work, we show that instead of following the prevalent pretext task to perform masked self-component reconstruction in human joints, explicit contextual motion modeling is key to the success of learning effective feature representation for 3D action recognition. Formally, we propose the Masked Motion Prediction (MAMP) framework. To be specific, the proposed MAMP takes as input the masked spatio-temporal skeleton sequence and predicts the corresponding temporal motion of the masked human joints. Considering the high temporal redundancy of the skeleton sequence, in our MAMP, the motion information also acts as an empirical semantic richness prior that guide the masking process, promoting better attention to semantically rich temporal regions. Extensive experiments on NTU-60, NTU-120, and PKU-MMD datasets show that the proposed MAMP pre-training substantially improves the performance of the adopted vanilla transformer, achieving state-of-the-art results without bells and whistles. The source code of our MAMP is available at https://github.com/maoyunyao/MAMP.
Detect Any Shadow: Segment Anything for Video Shadow Detection
May 26, 2023



Segment anything model (SAM) has achieved great success in the field of natural image segmentation. Nevertheless, SAM tends to classify shadows as background, resulting in poor segmentation performance for shadow detection task. In this paper, we propose an simple but effective approach for fine tuning SAM to detect shadows. Additionally, we also combine it with long short-term attention mechanism to extend its capabilities to video shadow detection. Specifically, we first fine tune SAM by utilizing shadow data combined with sparse prompts and apply the fine-tuned model to detect a specific frame (e.g., first frame) in the video with a little user assistance. Subsequently, using the detected frame as a reference, we employ a long short-term network to learn spatial correlations between distant frames and temporal consistency between contiguous frames, thereby achieving shadow information propagation across frames. Extensive experimental results demonstrate that our method outperforms the state-of-the-art techniques, with improvements of 17.2% and 3.3% in terms of MAE and IoU, respectively, validating the effectiveness of our method.
CMD: Self-supervised 3D Action Representation Learning with Cross-modal Mutual Distillation
Aug 30, 2022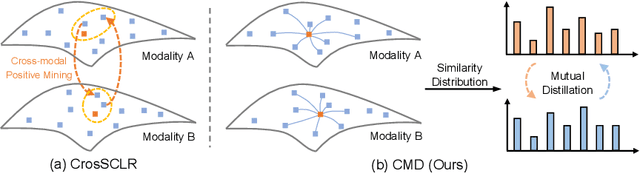
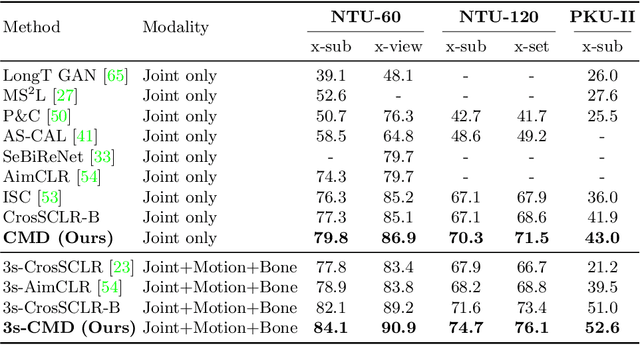
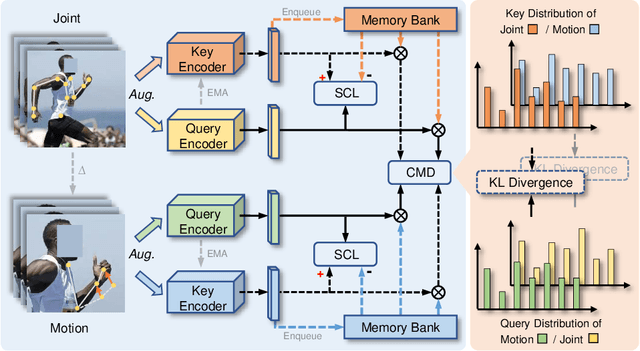
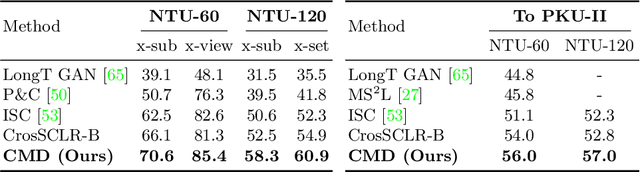
In 3D action recognition, there exists rich complementary information between skeleton modalities. Nevertheless, how to model and utilize this information remains a challenging problem for self-supervised 3D action representation learning. In this work, we formulate the cross-modal interaction as a bidirectional knowledge distillation problem. Different from classic distillation solutions that transfer the knowledge of a fixed and pre-trained teacher to the student, in this work, the knowledge is continuously updated and bidirectionally distilled between modalities. To this end, we propose a new Cross-modal Mutual Distillation (CMD) framework with the following designs. On the one hand, the neighboring similarity distribution is introduced to model the knowledge learned in each modality, where the relational information is naturally suitable for the contrastive frameworks. On the other hand, asymmetrical configurations are used for teacher and student to stabilize the distillation process and to transfer high-confidence information between modalities. By derivation, we find that the cross-modal positive mining in previous works can be regarded as a degenerated version of our CMD. We perform extensive experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD II datasets. Our approach outperforms existing self-supervised methods and sets a series of new records. The code is available at: https://github.com/maoyunyao/CMD