 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions
May 23, 2023

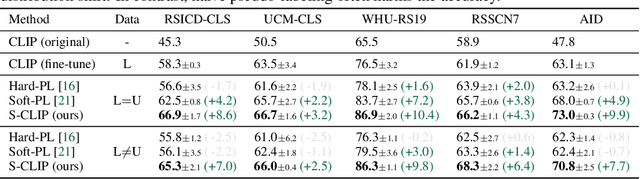

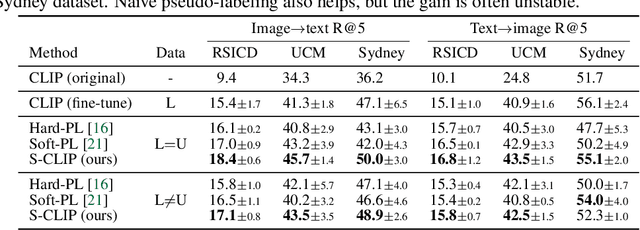
Vision-language models, such as contrastive language-image pre-training (CLIP), have demonstrated impressive results in natural image domains. However, these models often struggle when applied to specialized domains like remote sensing, and adapting to such domains is challenging due to the limited number of image-text pairs available for training. To address this, we propose S-CLIP, a semi-supervised learning method for training CLIP that utilizes additional unpaired images. S-CLIP employs two pseudo-labeling strategies specifically designed for contrastive learning and the language modality. The caption-level pseudo-label is given by a combination of captions of paired images, obtained by solving an optimal transport problem between unpaired and paired images. The keyword-level pseudo-label is given by a keyword in the caption of the nearest paired image, trained through partial label learning that assumes a candidate set of labels for supervision instead of the exact one. By combining these objectives, S-CLIP significantly enhances the training of CLIP using only a few image-text pairs, as demonstrated in various specialist domains, including remote sensing, fashion, scientific figures, and comics. For instance, S-CLIP improves CLIP by 10% for zero-shot classification and 4% for image-text retrieval on the remote sensing benchmark, matching the performance of supervised CLIP while using three times fewer image-text pairs.
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 06, 2023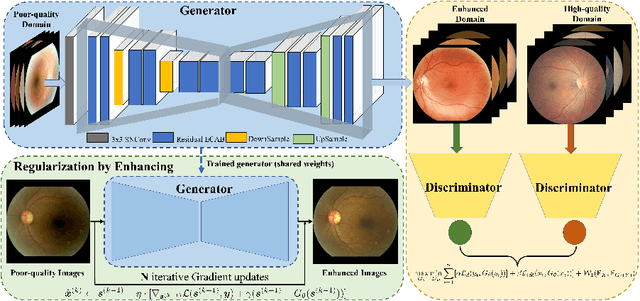
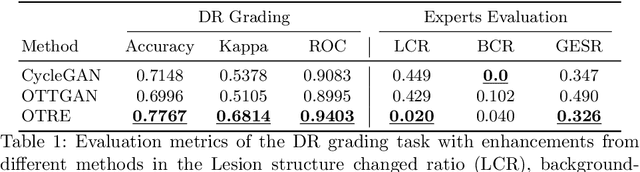
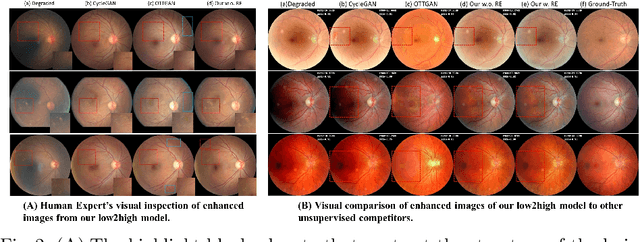
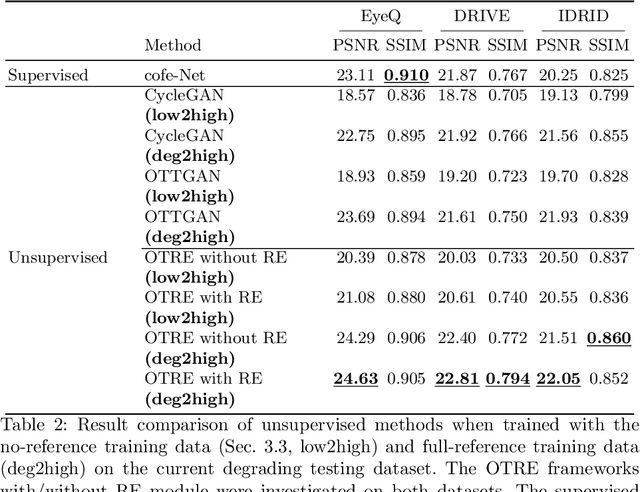
Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the \emph{Optimal Transport (OT)} theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as \emph{regularization by enhancing (RE)}. We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Toward Real Flare Removal: A Comprehensive Pipeline and A New Benchmark
Jun 28, 2023

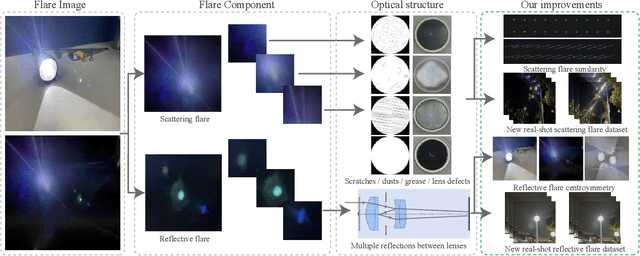

Photographing in the under-illuminated scenes, the presence of complex light sources often leave strong flare artifacts in images, where the intensity, the spectrum, the reflection, and the aberration altogether contribute the deterioration. Besides the image quality, it also influence the performance of down-stream visual applications. Thus, removing the lens flare and ghosts is a challenge issue especially in low-light environment. However, existing methods for flare removal mainly restricted to the problems of inadequate simulation and real-world capture, where the categories of scattered flares are singular and the reflected ghosts are unavailable. Therefore, a comprehensive deterioration procedure is crucial for constructing the dataset of flare removal. Based on the theoretical analysis and real-world evaluation, we propose a well-developed methodology for generating the data-pairs with flare deterioration. The procedure is comprehensive, where the similarity of scattered flares and the symmetric effect of reflected ghosts are realized. Moreover, we also construct a real-shot pipeline that respectively processes the effects of scattering and reflective flares, aiming to directly generate the data for end-to-end methods. Experimental results show that the proposed methodology add diversity to the existing flare datasets and construct a comprehensive mapping procedure for flare data pairs. And our method facilities the data-driven model to realize better restoration in flare images and proposes a better evaluation system based on real shots, resulting promote progress in the area of real flare removal.
PuMer: Pruning and Merging Tokens for Efficient Vision Language Models
May 27, 2023
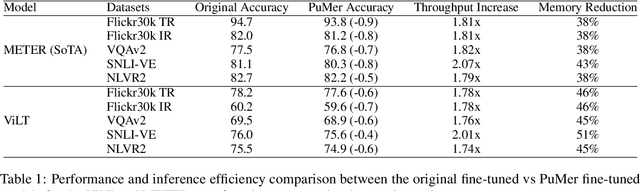
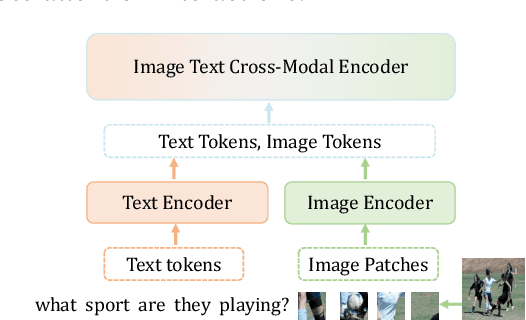
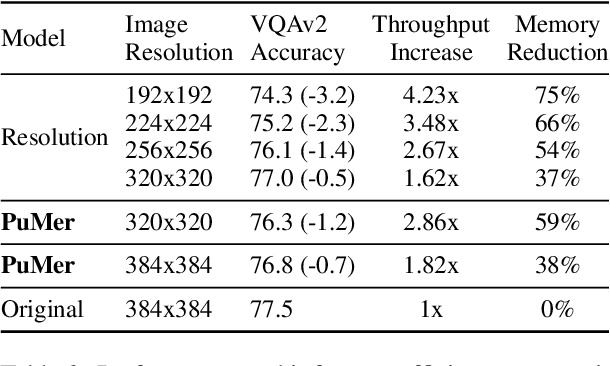
Large-scale vision language (VL) models use Transformers to perform cross-modal interactions between the input text and image. These cross-modal interactions are computationally expensive and memory-intensive due to the quadratic complexity of processing the input image and text. We present PuMer: a token reduction framework that uses text-informed Pruning and modality-aware Merging strategies to progressively reduce the tokens of input image and text, improving model inference speed and reducing memory footprint. PuMer learns to keep salient image tokens related to the input text and merges similar textual and visual tokens by adding lightweight token reducer modules at several cross-modal layers in the VL model. Training PuMer is mostly the same as finetuning the original VL model but faster. Our evaluation for two vision language models on four downstream VL tasks shows PuMer increases inference throughput by up to 2x and reduces memory footprint by over 50% while incurring less than a 1% accuracy drop.
FishDreamer: Towards Fisheye Semantic Completion via Unified Image Outpainting and Segmentation
Mar 24, 2023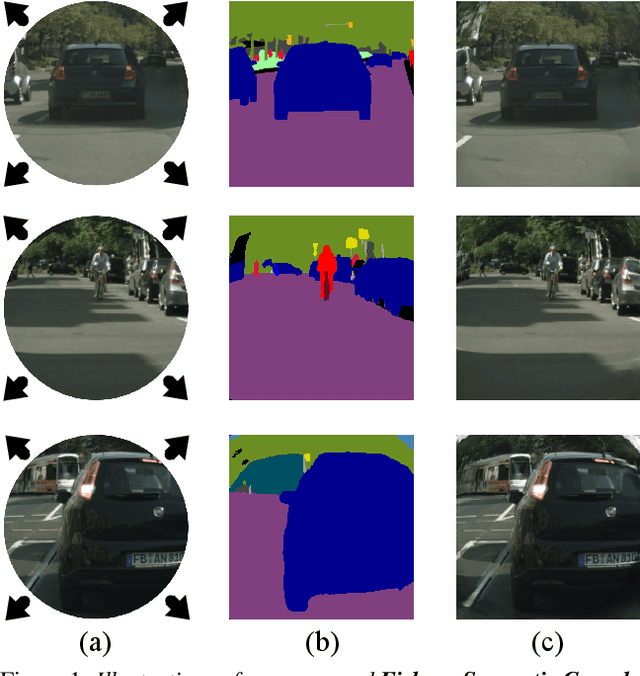
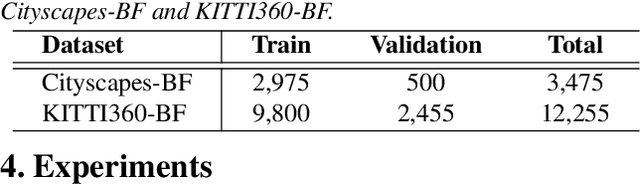
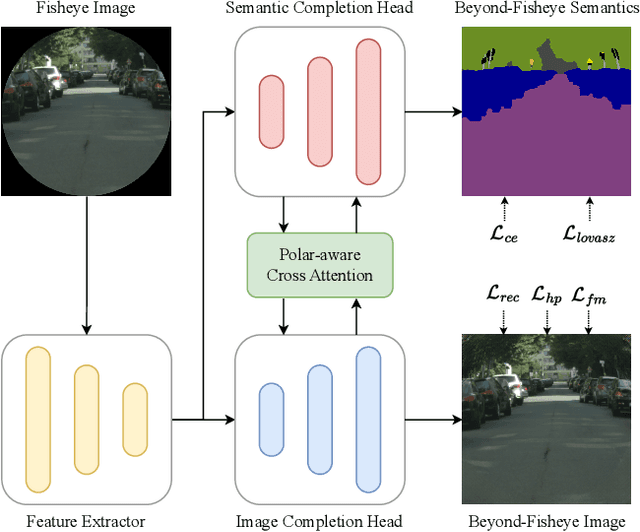
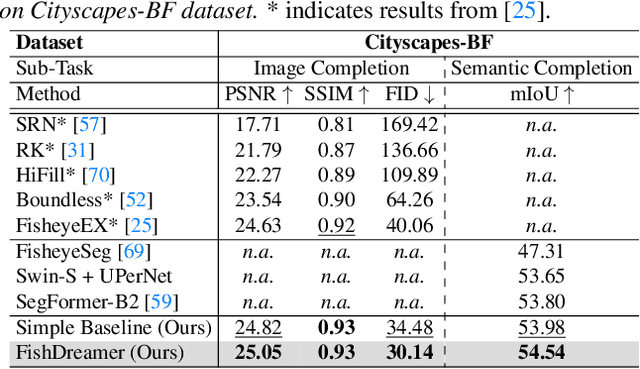
This paper raises the new task of Fisheye Semantic Completion (FSC), where dense texture, structure, and semantics of a fisheye image are inferred even beyond the sensor field-of-view (FoV). Fisheye cameras have larger FoV than ordinary pinhole cameras, yet its unique special imaging model naturally leads to a blind area at the edge of the image plane. This is suboptimal for safety-critical applications since important perception tasks, such as semantic segmentation, become very challenging within the blind zone. Previous works considered the out-FoV outpainting and in-FoV segmentation separately. However, we observe that these two tasks are actually closely coupled. To jointly estimate the tightly intertwined complete fisheye image and scene semantics, we introduce the new FishDreamer which relies on successful ViTs enhanced with a novel Polar-aware Cross Attention module (PCA) to leverage dense context and guide semantically-consistent content generation while considering different polar distributions. In addition to the contribution of the novel task and architecture, we also derive Cityscapes-BF and KITTI360-BF datasets to facilitate training and evaluation of this new track. Our experiments demonstrate that the proposed FishDreamer outperforms methods solving each task in isolation and surpasses alternative approaches on the Fisheye Semantic Completion. Code and datasets will be available at https://github.com/MasterHow/FishDreamer.
A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution
Jun 02, 2023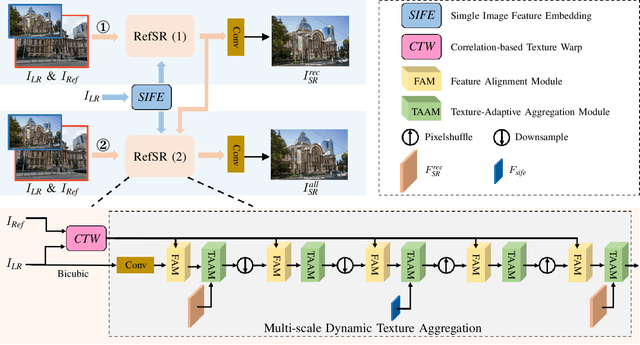
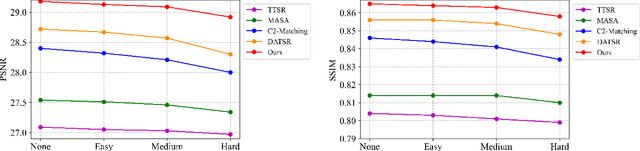

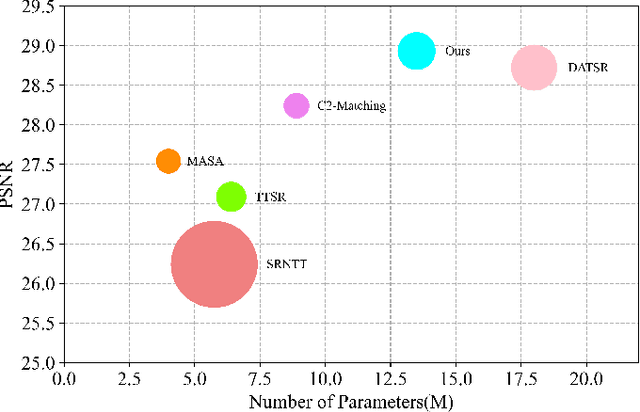
Reference-based super-resolution (RefSR) has gained considerable success in the field of super-resolution with the addition of high-resolution reference images to reconstruct low-resolution (LR) inputs with more high-frequency details, thereby overcoming some limitations of single image super-resolution (SISR). Previous research in the field of RefSR has mostly focused on two crucial aspects. The first is accurate correspondence matching between the LR and the reference (Ref) image. The second is the effective transfer and aggregation of similar texture information from the Ref images. Nonetheless, an important detail of perceptual loss and adversarial loss has been underestimated, which has a certain adverse effect on texture transfer and reconstruction. In this study, we propose a feature reuse framework that guides the step-by-step texture reconstruction process through different stages, reducing the negative impacts of perceptual and adversarial loss. The feature reuse framework can be used for any RefSR model, and several RefSR approaches have improved their performance after being retrained using our framework. Additionally, we introduce a single image feature embedding module and a texture-adaptive aggregation module. The single image feature embedding module assists in reconstructing the features of the LR inputs itself and effectively lowers the possibility of including irrelevant textures. The texture-adaptive aggregation module dynamically perceives and aggregates texture information between the LR inputs and the Ref images using dynamic filters. This enhances the utilization of the reference texture while reducing reference misuse. The source code is available at https://github.com/Yi-Yang355/FRFSR.
Democratizing Pathological Image Segmentation with Lay Annotators via Molecular-empowered Learning
May 31, 2023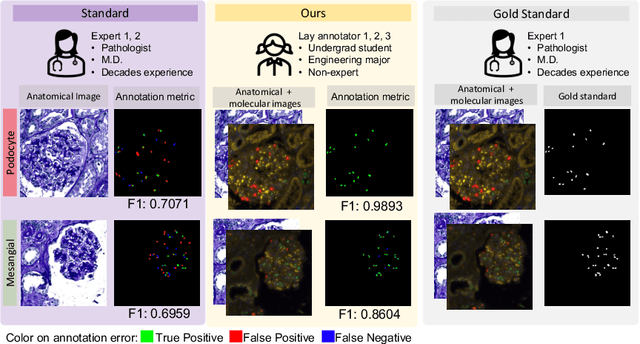
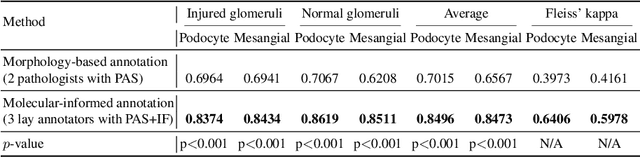
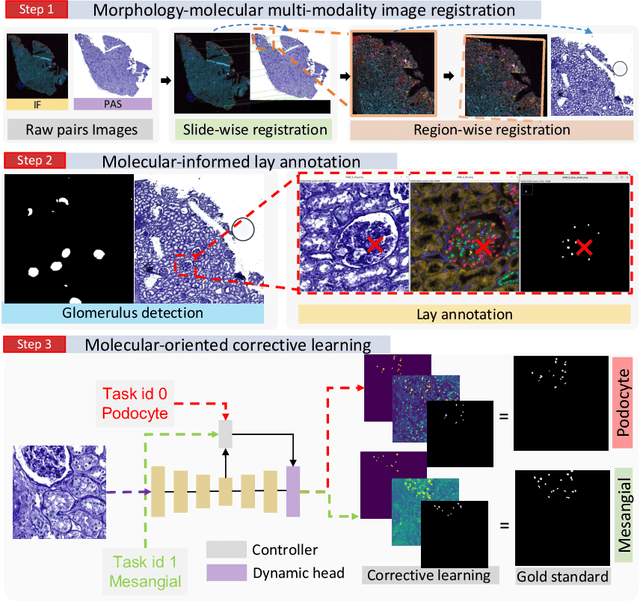
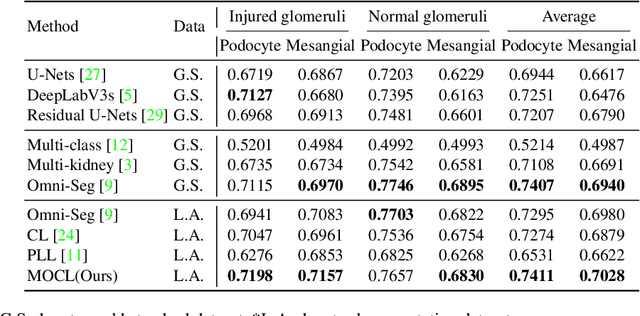
Multi-class cell segmentation in high-resolution Giga-pixel whole slide images (WSI) is critical for various clinical applications. Training such an AI model typically requires labor-intensive pixel-wise manual annotation from experienced domain experts (e.g., pathologists). Moreover, such annotation is error-prone when differentiating fine-grained cell types (e.g., podocyte and mesangial cells) via the naked human eye. In this study, we assess the feasibility of democratizing pathological AI deployment by only using lay annotators (annotators without medical domain knowledge). The contribution of this paper is threefold: (1) We proposed a molecular-empowered learning scheme for multi-class cell segmentation using partial labels from lay annotators; (2) The proposed method integrated Giga-pixel level molecular-morphology cross-modality registration, molecular-informed annotation, and molecular-oriented segmentation model, so as to achieve significantly superior performance via 3 lay annotators as compared with 2 experienced pathologists; (3) A deep corrective learning (learning with imperfect label) method is proposed to further improve the segmentation performance using partially annotated noisy data. From the experimental results, our learning method achieved F1 = 0.8496 using molecular-informed annotations from lay annotators, which is better than conventional morphology-based annotations (F1 = 0.7051) from experienced pathologists. Our method democratizes the development of a pathological segmentation deep model to the lay annotator level, which consequently scales up the learning process similar to a non-medical computer vision task. The official implementation and cell annotations are publicly available at https://github.com/hrlblab/MolecularEL.
Domain-Aware Few-Shot Learning for Optical Coherence Tomography Noise Reduction
Jun 13, 2023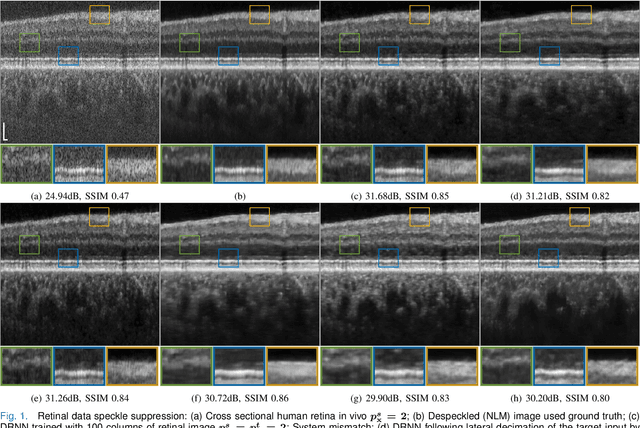
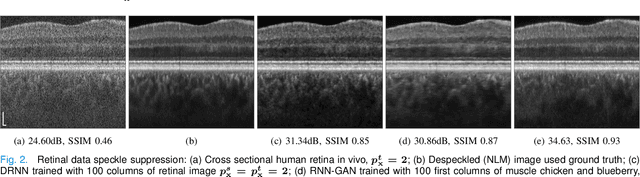
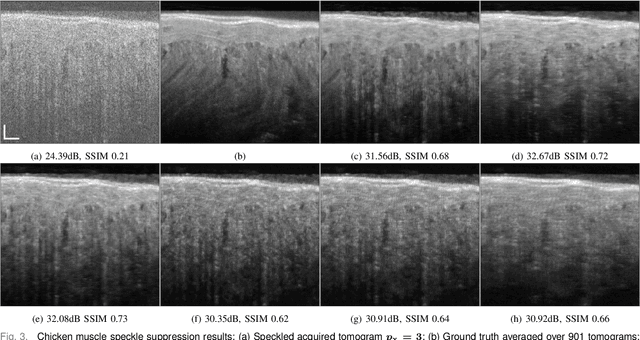
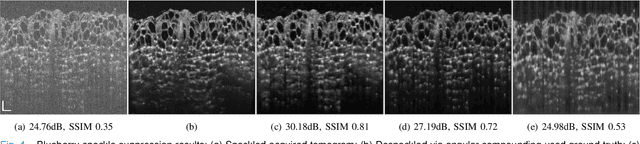
Speckle noise has long been an extensively studied problem in medical imaging. In recent years, there have been significant advances in leveraging deep learning methods for noise reduction. Nevertheless, adaptation of supervised learning models to unseen domains remains a challenging problem. Specifically, deep neural networks (DNNs) trained for computational imaging tasks are vulnerable to changes in the acquisition system's physical parameters, such as: sampling space, resolution, and contrast. Even within the same acquisition system, performance degrades across datasets of different biological tissues. In this work, we propose a few-shot supervised learning framework for optical coherence tomography (OCT) noise reduction, that offers a dramatic increase in training speed and requires only a single image, or part of an image, and a corresponding speckle suppressed ground truth, for training. Furthermore, we formulate the domain shift problem for OCT diverse imaging systems, and prove that the output resolution of a despeckling trained model is determined by the source domain resolution. We also provide possible remedies. We propose different practical implementations of our approach, verify and compare their applicability, robustness, and computational efficiency. Our results demonstrate significant potential for generally improving sample complexity, generalization, and time efficiency, for coherent and non-coherent noise reduction via supervised learning models, that can also be leveraged for other real-time computer vision applications.
Parametric Implicit Face Representation for Audio-Driven Facial Reenactment
Jun 13, 2023
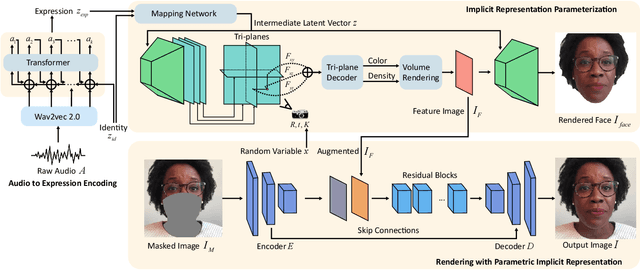

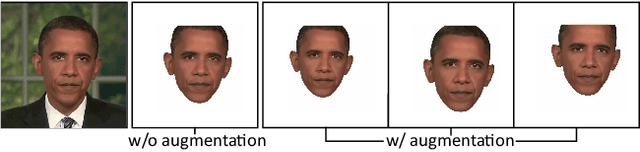
Audio-driven facial reenactment is a crucial technique that has a range of applications in film-making, virtual avatars and video conferences. Existing works either employ explicit intermediate face representations (e.g., 2D facial landmarks or 3D face models) or implicit ones (e.g., Neural Radiance Fields), thus suffering from the trade-offs between interpretability and expressive power, hence between controllability and quality of the results. In this work, we break these trade-offs with our novel parametric implicit face representation and propose a novel audio-driven facial reenactment framework that is both controllable and can generate high-quality talking heads. Specifically, our parametric implicit representation parameterizes the implicit representation with interpretable parameters of 3D face models, thereby taking the best of both explicit and implicit methods. In addition, we propose several new techniques to improve the three components of our framework, including i) incorporating contextual information into the audio-to-expression parameters encoding; ii) using conditional image synthesis to parameterize the implicit representation and implementing it with an innovative tri-plane structure for efficient learning; iii) formulating facial reenactment as a conditional image inpainting problem and proposing a novel data augmentation technique to improve model generalizability. Extensive experiments demonstrate that our method can generate more realistic results than previous methods with greater fidelity to the identities and talking styles of speakers.
PSSTRNet: Progressive Segmentation-guided Scene Text Removal Network
Jun 13, 2023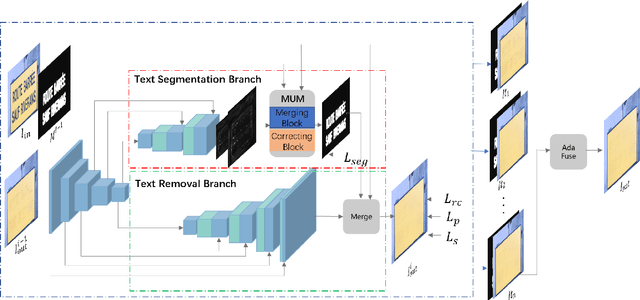
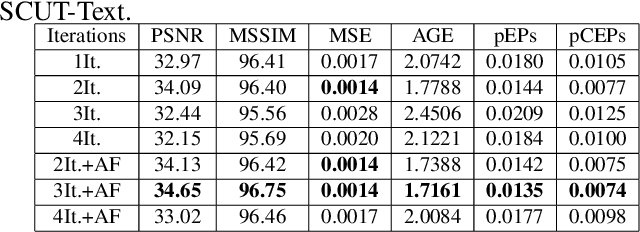

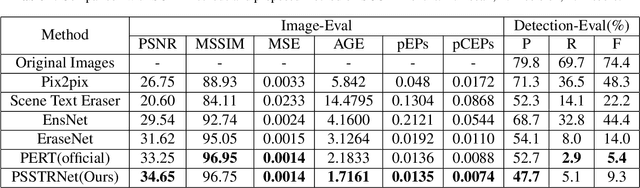
Scene text removal (STR) is a challenging task due to the complex text fonts, colors, sizes, and background textures in scene images. However, most previous methods learn both text location and background inpainting implicitly within a single network, which weakens the text localization mechanism and makes a lossy background. To tackle these problems, we propose a simple Progressive Segmentation-guided Scene Text Removal Network(PSSTRNet) to remove the text in the image iteratively. It contains two decoder branches, a text segmentation branch, and a text removal branch, with a shared encoder. The text segmentation branch generates text mask maps as the guidance for the regional removal branch. In each iteration, the original image, previous text removal result, and text mask are input to the network to extract the rest part of the text segments and cleaner text removal result. To get a more accurate text mask map, an update module is developed to merge the mask map in the current and previous stages. The final text removal result is obtained by adaptive fusion of results from all previous stages. A sufficient number of experiments and ablation studies conducted on the real and synthetic public datasets demonstrate our proposed method achieves state-of-the-art performance. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/PSSTRNet}{https://github.com/GuangtaoLyu/PSSTRNet.}
* Accepted by ICME2022