 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA BERT-Style Self-Supervised Learning CNN for Disease Identification from Retinal Images
Apr 25, 2025In the field of medical imaging, the advent of deep learning, especially the application of convolutional neural networks (CNNs) has revolutionized the analysis and interpretation of medical images. Nevertheless, deep learning methods usually rely on large amounts of labeled data. In medical imaging research, the acquisition of high-quality labels is both expensive and difficult. The introduction of Vision Transformers (ViT) and self-supervised learning provides a pre-training strategy that utilizes abundant unlabeled data, effectively alleviating the label acquisition challenge while broadening the breadth of data utilization. However, ViT's high computational density and substantial demand for computing power, coupled with the lack of localization characteristics of its operations on image patches, limit its efficiency and applicability in many application scenarios. In this study, we employ nn-MobileNet, a lightweight CNN framework, to implement a BERT-style self-supervised learning approach. We pre-train the network on the unlabeled retinal fundus images from the UK Biobank to improve downstream application performance. We validate the results of the pre-trained model on Alzheimer's disease (AD), Parkinson's disease (PD), and various retinal diseases identification. The results show that our approach can significantly improve performance in the downstream tasks. In summary, this study combines the benefits of CNNs with the capabilities of advanced self-supervised learning in handling large-scale unlabeled data, demonstrating the potential of CNNs in the presence of label scarcity.
Many-MobileNet: Multi-Model Augmentation for Robust Retinal Disease Classification
Dec 03, 2024



In this work, we propose Many-MobileNet, an efficient model fusion strategy for retinal disease classification using lightweight CNN architecture. Our method addresses key challenges such as overfitting and limited dataset variability by training multiple models with distinct data augmentation strategies and different model complexities. Through this fusion technique, we achieved robust generalization in data-scarce domains while balancing computational efficiency with feature extraction capabilities.
TPOT: Topology Preserving Optimal Transport in Retinal Fundus Image Enhancement
Nov 03, 2024



Retinal fundus photography enhancement is important for diagnosing and monitoring retinal diseases. However, early approaches to retinal image enhancement, such as those based on Generative Adversarial Networks (GANs), often struggle to preserve the complex topological information of blood vessels, resulting in spurious or missing vessel structures. The persistence diagram, which captures topological features based on the persistence of topological structures under different filtrations, provides a promising way to represent the structure information. In this work, we propose a topology-preserving training paradigm that regularizes blood vessel structures by minimizing the differences of persistence diagrams. We call the resulting framework Topology Preserving Optimal Transport (TPOT). Experimental results on a large-scale dataset demonstrate the superiority of the proposed method compared to several state-of-the-art supervised and unsupervised techniques, both in terms of image quality and performance in the downstream blood vessel segmentation task. The code is available at https://github.com/Retinal-Research/TPOT.
EViT-Unet: U-Net Like Efficient Vision Transformer for Medical Image Segmentation on Mobile and Edge Devices
Oct 19, 2024



With the rapid development of deep learning, CNN-based U-shaped networks have succeeded in medical image segmentation and are widely applied for various tasks. However, their limitations in capturing global features hinder their performance in complex segmentation tasks. The rise of Vision Transformer (ViT) has effectively compensated for this deficiency of CNNs and promoted the application of ViT-based U-networks in medical image segmentation. However, the high computational demands of ViT make it unsuitable for many medical devices and mobile platforms with limited resources, restricting its deployment on resource-constrained and edge devices. To address this, we propose EViT-UNet, an efficient ViT-based segmentation network that reduces computational complexity while maintaining accuracy, making it ideal for resource-constrained medical devices. EViT-UNet is built on a U-shaped architecture, comprising an encoder, decoder, bottleneck layer, and skip connections, combining convolutional operations with self-attention mechanisms to optimize efficiency. Experimental results demonstrate that EViT-UNet achieves high accuracy in medical image segmentation while significantly reducing computational complexity.
PDL: Regularizing Multiple Instance Learning with Progressive Dropout Layers
Aug 19, 2023Multiple instance learning (MIL) was a weakly supervised learning approach that sought to assign binary class labels to collections of instances known as bags. However, due to their weak supervision nature, the MIL methods were susceptible to overfitting and required assistance in developing comprehensive representations of target instances. While regularization typically effectively combated overfitting, its integration with the MIL model has been frequently overlooked in prior studies. Meanwhile, current regularization methods for MIL have shown limitations in their capacity to uncover a diverse array of representations. In this study, we delve into the realm of regularization within the MIL model, presenting a novel approach in the form of a Progressive Dropout Layer (PDL). We aim to not only address overfitting but also empower the MIL model in uncovering intricate and impactful feature representations. The proposed method was orthogonal to existing MIL methods and could be easily integrated into them to boost performance. Our extensive evaluation across a range of MIL benchmark datasets demonstrated that the incorporation of the PDL into multiple MIL methods not only elevated their classification performance but also augmented their potential for weakly-supervised feature localizations.
NNMobile-Net: Rethinking CNN Design for Deep Learning-Based Retinopathy Research
Jun 02, 2023Retinal diseases (RD) are the leading cause of severe vision loss or blindness. Deep learning-based automated tools play an indispensable role in assisting clinicians in diagnosing and monitoring RD in modern medicine. Recently, an increasing number of works in this field have taken advantage of Vision Transformer to achieve state-of-the-art performance with more parameters and higher model complexity compared to Convolutional Neural Networks (CNNs). Such sophisticated and task-specific model designs, however, are prone to be overfitting and hinder their generalizability. In this work, we argue that a channel-aware and well-calibrated CNN model may overcome these problems. To this end, we empirically studied CNN's macro and micro designs and its training strategies. Based on the investigation, we proposed a no-new-MobleNet (nn-MobileNet) developed for retinal diseases. In our experiments, our generic, simple and efficient model superseded most current state-of-the-art methods on four public datasets for multiple tasks, including diabetic retinopathy grading, fundus multi-disease detection, and diabetic macular edema classification. Our work may provide novel insights into deep learning architecture design and advance retinopathy research.
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 09, 2023



Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Optimal Transport Guided Unsupervised Learning for Enhancing low-quality Retinal Images
Feb 06, 2023



Real-world non-mydriatic retinal fundus photography is prone to artifacts, imperfections and low-quality when certain ocular or systemic co-morbidities exist. Artifacts may result in inaccuracy or ambiguity in clinical diagnoses. In this paper, we proposed a simple but effective end-to-end framework for enhancing poor-quality retinal fundus images. Leveraging the optimal transport theory, we proposed an unpaired image-to-image translation scheme for transporting low-quality images to their high-quality counterparts. We theoretically proved that a Generative Adversarial Networks (GAN) model with a generator and discriminator is sufficient for this task. Furthermore, to mitigate the inconsistency of information between the low-quality images and their enhancements, an information consistency mechanism was proposed to maximally maintain structural consistency (optical discs, blood vessels, lesions) between the source and enhanced domains. Extensive experiments were conducted on the EyeQ dataset to demonstrate the superiority of our proposed method perceptually and quantitatively.
Self-Supervised Equivariant Regularization Reconciles Multiple Instance Learning: Joint Referable Diabetic Retinopathy Classification and Lesion Segmentation
Oct 12, 2022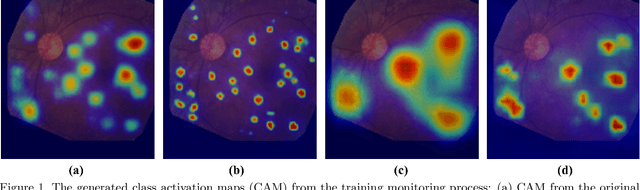
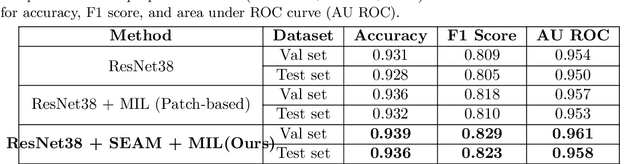
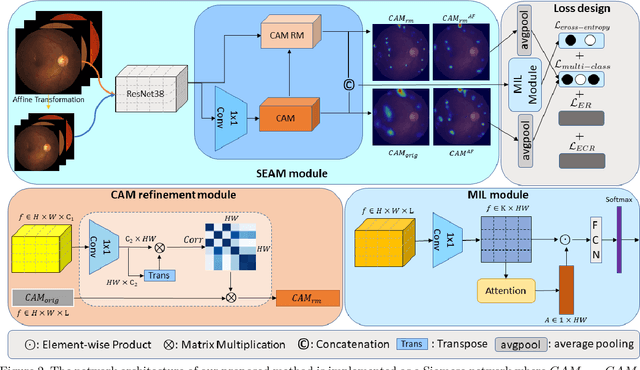

Lesion appearance is a crucial clue for medical providers to distinguish referable diabetic retinopathy (rDR) from non-referable DR. Most existing large-scale DR datasets contain only image-level labels rather than pixel-based annotations. This motivates us to develop algorithms to classify rDR and segment lesions via image-level labels. This paper leverages self-supervised equivariant learning and attention-based multi-instance learning (MIL) to tackle this problem. MIL is an effective strategy to differentiate positive and negative instances, helping us discard background regions (negative instances) while localizing lesion regions (positive ones). However, MIL only provides coarse lesion localization and cannot distinguish lesions located across adjacent patches. Conversely, a self-supervised equivariant attention mechanism (SEAM) generates a segmentation-level class activation map (CAM) that can guide patch extraction of lesions more accurately. Our work aims at integrating both methods to improve rDR classification accuracy. We conduct extensive validation experiments on the Eyepacs dataset, achieving an area under the receiver operating characteristic curve (AU ROC) of 0.958, outperforming current state-of-the-art algorithms.