 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cumulative Spatial Knowledge Distillation for Vision Transformers
Jul 17, 2023
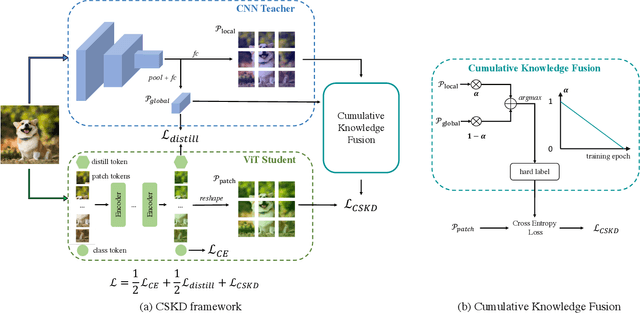
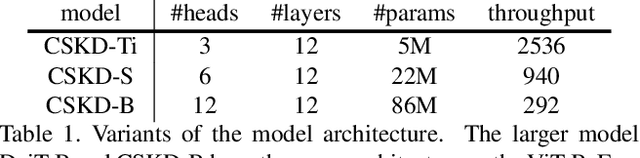
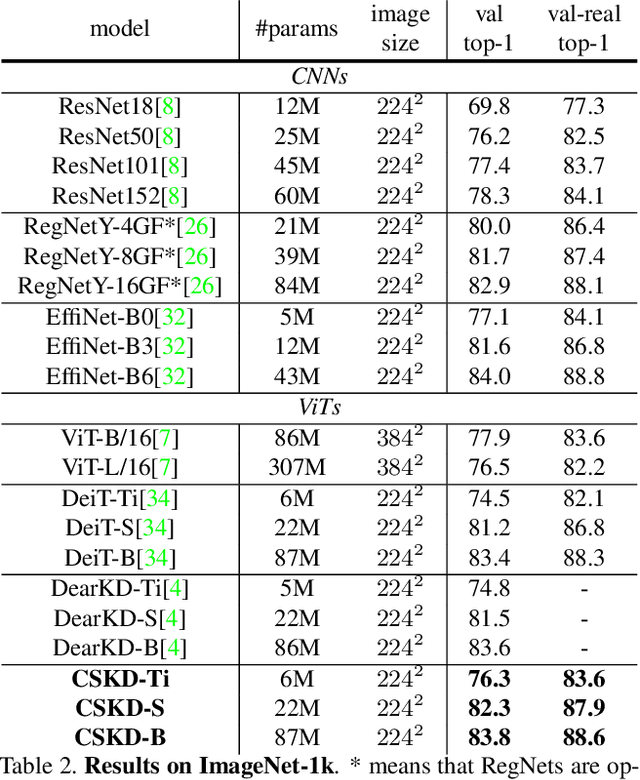
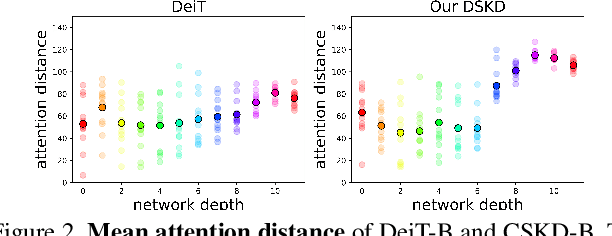
Distilling knowledge from convolutional neural networks (CNNs) is a double-edged sword for vision transformers (ViTs). It boosts the performance since the image-friendly local-inductive bias of CNN helps ViT learn faster and better, but leading to two problems: (1) Network designs of CNN and ViT are completely different, which leads to different semantic levels of intermediate features, making spatial-wise knowledge transfer methods (e.g., feature mimicking) inefficient. (2) Distilling knowledge from CNN limits the network convergence in the later training period since ViT's capability of integrating global information is suppressed by CNN's local-inductive-bias supervision. To this end, we present Cumulative Spatial Knowledge Distillation (CSKD). CSKD distills spatial-wise knowledge to all patch tokens of ViT from the corresponding spatial responses of CNN, without introducing intermediate features. Furthermore, CSKD exploits a Cumulative Knowledge Fusion (CKF) module, which introduces the global response of CNN and increasingly emphasizes its importance during the training. Applying CKF leverages CNN's local inductive bias in the early training period and gives full play to ViT's global capability in the later one. Extensive experiments and analysis on ImageNet-1k and downstream datasets demonstrate the superiority of our CSKD. Code will be publicly available.
Liver Tumor Screening and Diagnosis in CT with Pixel-Lesion-Patient Network
Jul 17, 2023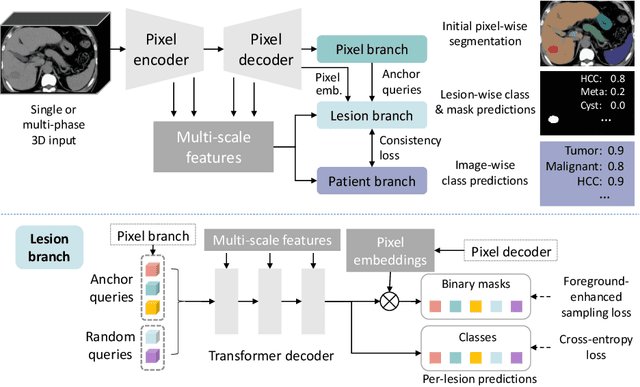

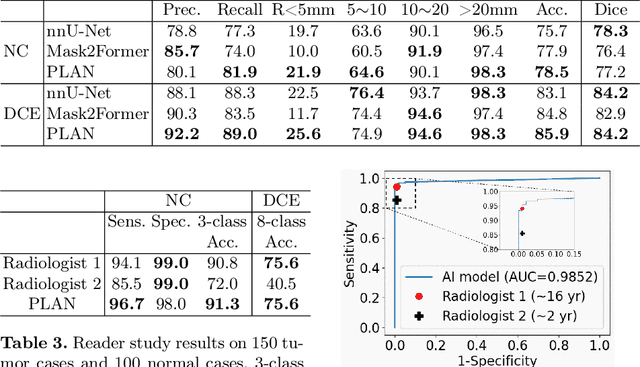
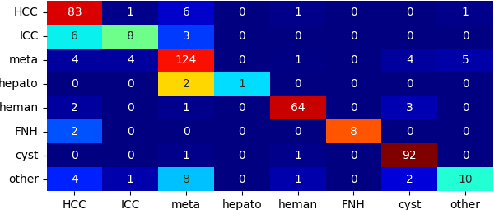
Liver tumor segmentation and classification are important tasks in computer aided diagnosis. We aim to address three problems: liver tumor screening and preliminary diagnosis in non-contrast computed tomography (CT), and differential diagnosis in dynamic contrast-enhanced CT. A novel framework named Pixel-Lesion-pAtient Network (PLAN) is proposed. It uses a mask transformer to jointly segment and classify each lesion with improved anchor queries and a foreground-enhanced sampling loss. It also has an image-wise classifier to effectively aggregate global information and predict patient-level diagnosis. A large-scale multi-phase dataset is collected containing 939 tumor patients and 810 normal subjects. 4010 tumor instances of eight types are extensively annotated. On the non-contrast tumor screening task, PLAN achieves 95% and 96% in patient-level sensitivity and specificity. On contrast-enhanced CT, our lesion-level detection precision, recall, and classification accuracy are 92%, 89%, and 86%, outperforming widely used CNN and transformers for lesion segmentation. We also conduct a reader study on a holdout set of 250 cases. PLAN is on par with a senior human radiologist, showing the clinical significance of our results.
EGE-UNet: an Efficient Group Enhanced UNet for skin lesion segmentation
Jul 17, 2023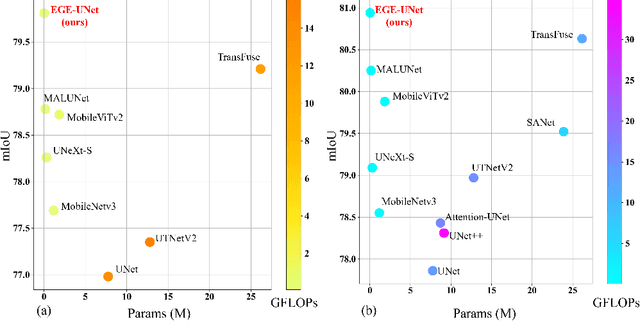
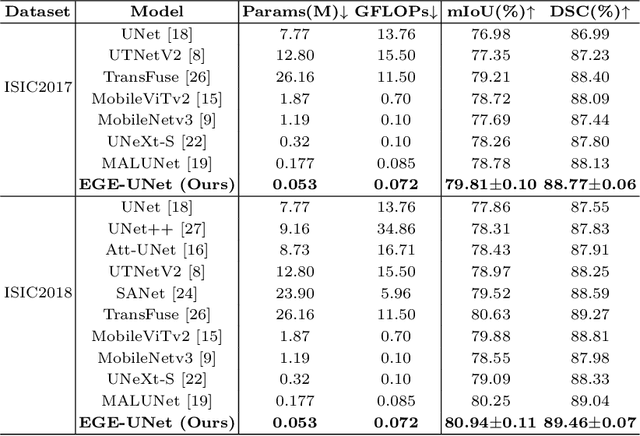
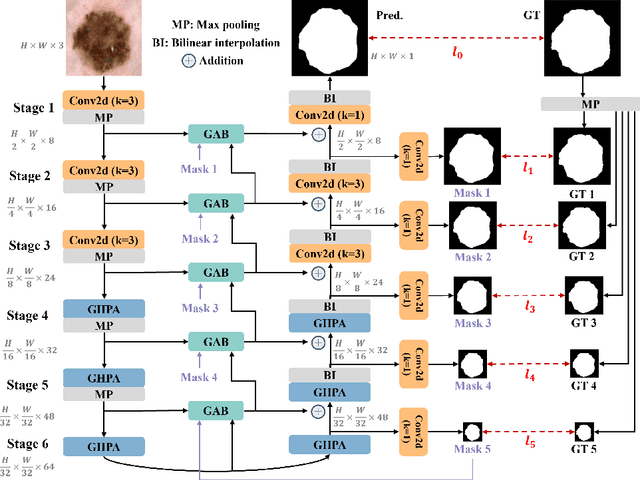
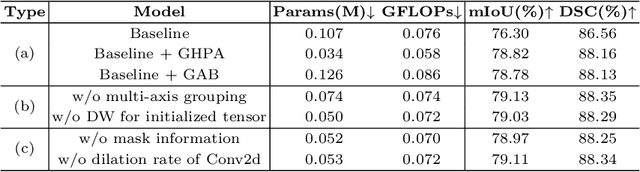
Transformer and its variants have been widely used for medical image segmentation. However, the large number of parameter and computational load of these models make them unsuitable for mobile health applications. To address this issue, we propose a more efficient approach, the Efficient Group Enhanced UNet (EGE-UNet). We incorporate a Group multi-axis Hadamard Product Attention module (GHPA) and a Group Aggregation Bridge module (GAB) in a lightweight manner. The GHPA groups input features and performs Hadamard Product Attention mechanism (HPA) on different axes to extract pathological information from diverse perspectives. The GAB effectively fuses multi-scale information by grouping low-level features, high-level features, and a mask generated by the decoder at each stage. Comprehensive experiments on the ISIC2017 and ISIC2018 datasets demonstrate that EGE-UNet outperforms existing state-of-the-art methods. In short, compared to the TransFuse, our model achieves superior segmentation performance while reducing parameter and computation costs by 494x and 160x, respectively. Moreover, to our best knowledge, this is the first model with a parameter count limited to just 50KB. Our code is available at https://github.com/JCruan519/EGE-UNet.
On the Real-Time Semantic Segmentation of Aphid Clusters in the Wild
Jul 17, 2023
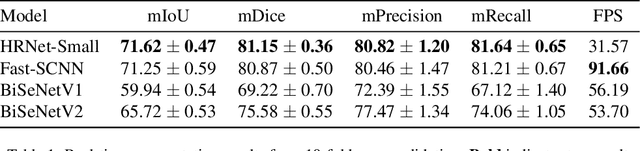

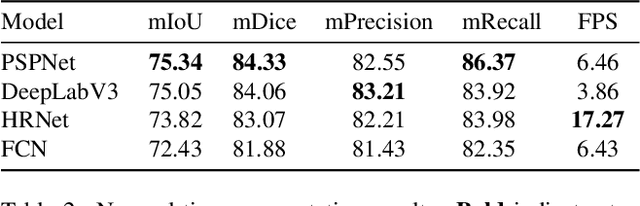
Aphid infestations can cause extensive damage to wheat and sorghum fields and spread plant viruses, resulting in significant yield losses in agriculture. To address this issue, farmers often rely on chemical pesticides, which are inefficiently applied over large areas of fields. As a result, a considerable amount of pesticide is wasted on areas without pests, while inadequate amounts are applied to areas with severe infestations. The paper focuses on the urgent need for an intelligent autonomous system that can locate and spray infestations within complex crop canopies, reducing pesticide use and environmental impact. We have collected and labeled a large aphid image dataset in the field, and propose the use of real-time semantic segmentation models to segment clusters of aphids. A multiscale dataset is generated to allow for learning the clusters at different scales. We compare the segmentation speeds and accuracy of four state-of-the-art real-time semantic segmentation models on the aphid cluster dataset, benchmarking them against nonreal-time models. The study results show the effectiveness of a real-time solution, which can reduce inefficient pesticide use and increase crop yields, paving the way towards an autonomous pest detection system.
UAlberta at SemEval-2023 Task 1: Context Augmentation and Translation for Multilingual Visual Word Sense Disambiguation
Jun 24, 2023

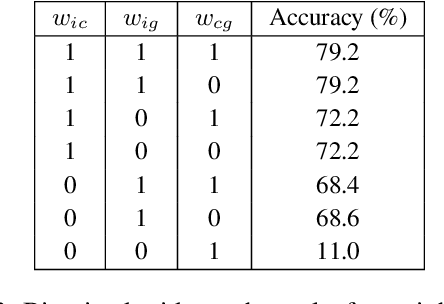
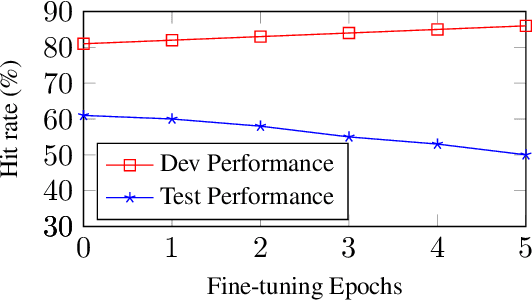
We describe the systems of the University of Alberta team for the SemEval-2023 Visual Word Sense Disambiguation (V-WSD) Task. We present a novel algorithm that leverages glosses retrieved from BabelNet, in combination with text and image encoders. Furthermore, we compare language-specific encoders against the application of English encoders to translated texts. As the contexts given in the task datasets are extremely short, we also experiment with augmenting these contexts with descriptions generated by a language model. This yields substantial improvements in accuracy. We describe and evaluate additional V-WSD methods which use image generation and text-conditioned image segmentation. Overall, the results of our official submission rank us 18 out of 56 teams. Some of our unofficial results are even better than the official ones. Our code is publicly available at https://github.com/UAlberta-NLP/v-wsd.
Key-Locked Rank One Editing for Text-to-Image Personalization
May 02, 2023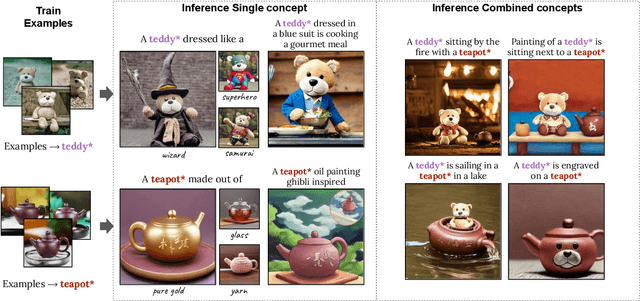



Text-to-image models (T2I) offer a new level of flexibility by allowing users to guide the creative process through natural language. However, personalizing these models to align with user-provided visual concepts remains a challenging problem. The task of T2I personalization poses multiple hard challenges, such as maintaining high visual fidelity while allowing creative control, combining multiple personalized concepts in a single image, and keeping a small model size. We present Perfusion, a T2I personalization method that addresses these challenges using dynamic rank-1 updates to the underlying T2I model. Perfusion avoids overfitting by introducing a new mechanism that "locks" new concepts' cross-attention Keys to their superordinate category. Additionally, we develop a gated rank-1 approach that enables us to control the influence of a learned concept during inference time and to combine multiple concepts. This allows runtime-efficient balancing of visual-fidelity and textual-alignment with a single 100KB trained model, which is five orders of magnitude smaller than the current state of the art. Moreover, it can span different operating points across the Pareto front without additional training. Finally, we show that Perfusion outperforms strong baselines in both qualitative and quantitative terms. Importantly, key-locking leads to novel results compared to traditional approaches, allowing to portray personalized object interactions in unprecedented ways, even in one-shot settings.
Histopathology Slide Indexing and Search: Are We There Yet?
Jun 29, 2023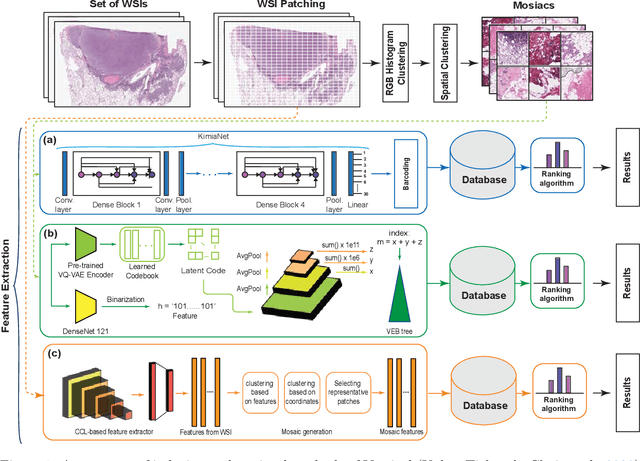


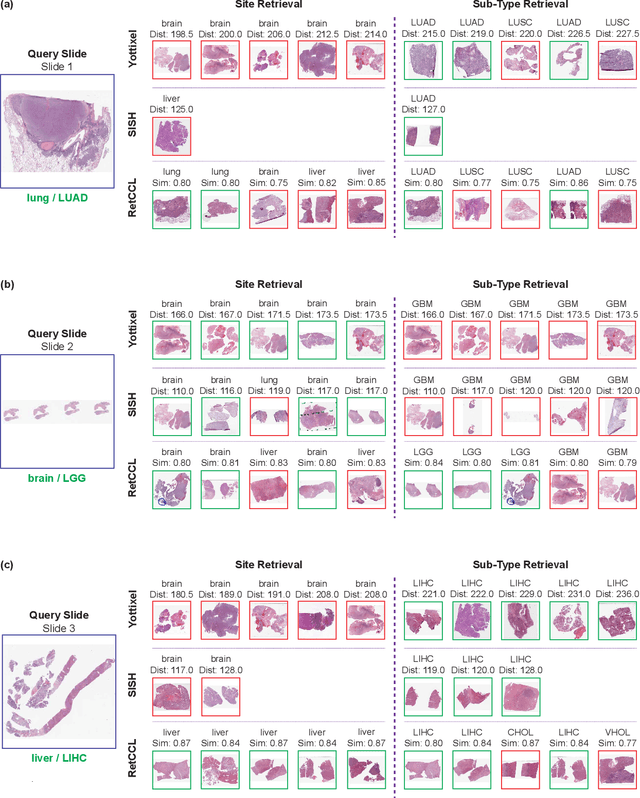
The search and retrieval of digital histopathology slides is an important task that has yet to be solved. In this case study, we investigate the clinical readiness of three state-of-the-art histopathology slide search engines, Yottixel, SISH, and RetCCL, on three patients with solid tumors. We provide a qualitative assessment of each model's performance in providing retrieval results that are reliable and useful to pathologists. We found that all three image search engines fail to produce consistently reliable results and have difficulties in capturing granular and subtle features of malignancy, limiting their diagnostic accuracy. Based on our findings, we also propose a minimal set of requirements to further advance the development of accurate and reliable histopathology image search engines for successful clinical adoption.
Text-to-image Diffusion Models in Generative AI: A Survey
Apr 02, 2023


This survey reviews text-to-image diffusion models in the context that diffusion models have emerged to be popular for a wide range of generative tasks. As a self-contained work, this survey starts with a brief introduction of how a basic diffusion model works for image synthesis, followed by how condition or guidance improves learning. Based on that, we present a review of state-of-the-art methods on text-conditioned image synthesis, i.e., text-to-image. We further summarize applications beyond text-to-image generation: text-guided creative generation and text-guided image editing. Beyond the progress made so far, we discuss existing challenges and promising future directions.
Sphere2Vec: A General-Purpose Location Representation Learning over a Spherical Surface for Large-Scale Geospatial Predictions
Jul 03, 2023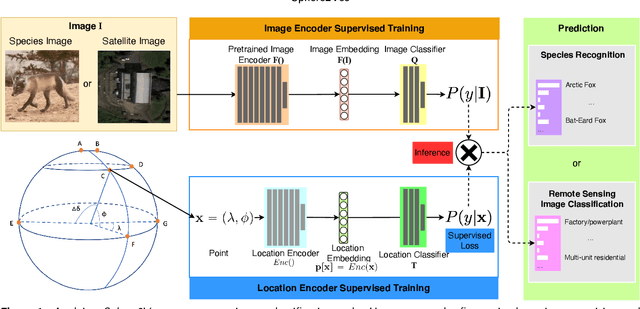
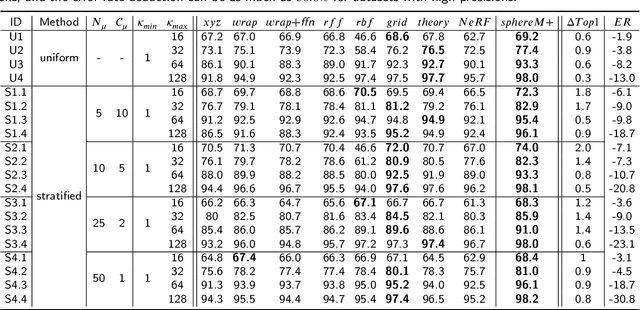
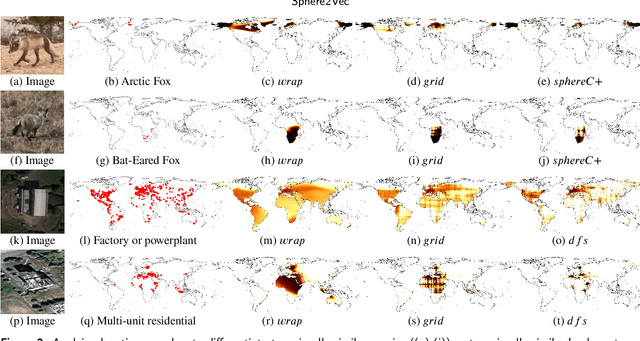
Generating learning-friendly representations for points in space is a fundamental and long-standing problem in ML. Recently, multi-scale encoding schemes (such as Space2Vec and NeRF) were proposed to directly encode any point in 2D/3D Euclidean space as a high-dimensional vector, and has been successfully applied to various geospatial prediction and generative tasks. However, all current 2D and 3D location encoders are designed to model point distances in Euclidean space. So when applied to large-scale real-world GPS coordinate datasets, which require distance metric learning on the spherical surface, both types of models can fail due to the map projection distortion problem (2D) and the spherical-to-Euclidean distance approximation error (3D). To solve these problems, we propose a multi-scale location encoder called Sphere2Vec which can preserve spherical distances when encoding point coordinates on a spherical surface. We developed a unified view of distance-reserving encoding on spheres based on the DFS. We also provide theoretical proof that the Sphere2Vec preserves the spherical surface distance between any two points, while existing encoding schemes do not. Experiments on 20 synthetic datasets show that Sphere2Vec can outperform all baseline models on all these datasets with up to 30.8% error rate reduction. We then apply Sphere2Vec to three geo-aware image classification tasks - fine-grained species recognition, Flickr image recognition, and remote sensing image classification. Results on 7 real-world datasets show the superiority of Sphere2Vec over multiple location encoders on all three tasks. Further analysis shows that Sphere2Vec outperforms other location encoder models, especially in the polar regions and data-sparse areas because of its nature for spherical surface distance preservation. Code and data are available at https://gengchenmai.github.io/sphere2vec-website/.
* 30 Pages, 16 figures. Accepted to ISPRS Journal of Photogrammetry and Remote Sensing
Experimental Security Analysis of DNN-based Adaptive Cruise Control under Context-Aware Perception Attacks
Jul 18, 2023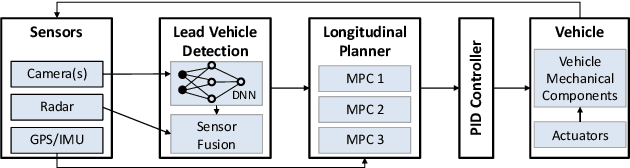

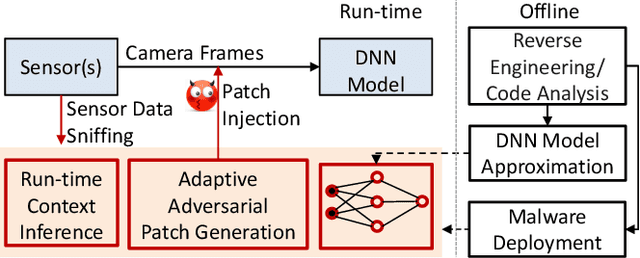
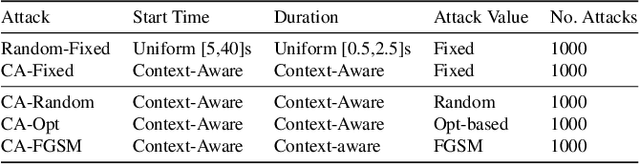
Adaptive Cruise Control (ACC) is a widely used driver assistance feature for maintaining desired speed and safe distance to the leading vehicles. This paper evaluates the security of the deep neural network (DNN) based ACC systems under stealthy perception attacks that strategically inject perturbations into camera data to cause forward collisions. We present a combined knowledge-and-data-driven approach to design a context-aware strategy for the selection of the most critical times for triggering the attacks and a novel optimization-based method for the adaptive generation of image perturbations at run-time. We evaluate the effectiveness of the proposed attack using an actual driving dataset and a realistic simulation platform with the control software from a production ACC system and a physical-world driving simulator while considering interventions by the driver and safety features such as Automatic Emergency Braking (AEB) and Forward Collision Warning (FCW). Experimental results show that the proposed attack achieves 142.9x higher success rate in causing accidents than random attacks and is mitigated 89.6% less by the safety features while being stealthy and robust to real-world factors and dynamic changes in the environment. This study provides insights into the role of human operators and basic safety interventions in preventing attacks.