 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Image Technical Report
May 25, 2026We introduce ERNIE-Image, an open-source text-to-image generation model built upon an 8B single-stream DiT architecture. ERNIE-Image aims to bridge the gap between current open-source models and leading closed-source systems through more effective mining of large-scale pre-training data and improved supervision quality throughout training. During pre-training, we adopt a bottom-up data construction pipeline that combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling. This strategy reduces data noise while preserving long-tail concepts and detailed real-world knowledge, providing a stronger foundation for complex generation tasks. In the post-training stage, we use a top-down data construction pipeline for high-demand scenarios, diversify prompt annotations to better match real user inputs, and apply a stabilized DPO strategy to align the model with human aesthetic preferences. We further train ERNIE-Image-Turbo for efficient 8-NFE generation and propose MT-DMD to mitigate capability drift during distillation. To make the model easier to use in practical scenarios, we equip it with a lightweight Prompt Enhancer that expands concise user intents into structured visual descriptions. In addition, we develop ERNIE-Image-Aes, an industrial-grade aesthetic model, together with ERNIE-Image-Aes-1K, a human-annotated benchmark for realistic aesthetic evaluation. Extensive qualitative and quantitative experiments show that ERNIE-Image achieves leading performance among open-source models and approaches top-tier commercial models in instruction following, text rendering, and aesthetic quality. We release the trained models and aesthetic resources to facilitate further academic research and technical progress in the AIGC community.
Annotation-Free Visual Reasoning for High-Resolution Large Multimodal Models via Reinforcement Learning
Feb 27, 2026Current Large Multimodal Models (LMMs) struggle with high-resolution visual inputs during the reasoning process, as the number of image tokens increases quadratically with resolution, introducing substantial redundancy and irrelevant information. A common practice is to identify key image regions and refer to their high-resolution counterparts during reasoning, typically trained with external visual supervision. However, such visual supervision cues require costly grounding labels from human annotators. Meanwhile, it remains an open question how to enhance a model's grounding abilities to support reasoning without relying on additional annotations. In this paper, we propose High-resolution Annotation-free Reasoning Technique (HART), a closed-loop framework that enables LMMs to focus on and self-verify key regions of high-resolution visual inputs. HART incorporates a post-training paradigm in which we design Advantage Preference Group Relative Policy Optimization (AP-GRPO) to encourage accurate localization of key regions. Notably, HART provides explainable reasoning pathways and enables efficient optimization of localization. Extensive experiments demonstrate that HART improves performance across a wide range of high-resolution visual tasks, consistently outperforming strong baselines. When applied to post-train Qwen2.5-VL-7B, HART even surpasses larger-scale models such as Qwen2.5-VL-72B and LLaVA-OneVision-72B on high-resolution, vision-centric benchmarks.
Cross-subject Brain Functional Connectivity Analysis for Multi-task Cognitive State Evaluation
Aug 27, 2024



Cognition refers to the function of information perception and processing, which is the fundamental psychological essence of human beings. It is responsible for reasoning and decision-making, while its evaluation is significant for the aviation domain in mitigating potential safety risks. Existing studies tend to use varied methods for cognitive state evaluation yet have limitations in timeliness, generalisation, and interpretability. Accordingly, this study adopts brain functional connectivity with electroencephalography signals to capture associations in brain regions across multiple subjects for evaluating real-time cognitive states. Specifically, a virtual reality-based flight platform is constructed with multi-screen embedded. Three distinctive cognitive tasks are designed and each has three degrees of difficulty. Thirty subjects are acquired for analysis and evaluation. The results are interpreted through different perspectives, including inner-subject and cross-subject for task-wise and gender-wise underlying brain functional connectivity. Additionally, this study incorporates questionnaire-based, task performance-based, and physiological measure-based approaches to fairly label the trials. A multi-class cognitive state evaluation is further conducted with the active brain connections. Benchmarking results demonstrate that the identified brain regions have considerable influences in cognition, with a multi-class accuracy rate of 95.83% surpassing existing studies. The derived findings bring significance to understanding the dynamic relationships among human brain functional regions, cross-subject cognitive behaviours, and decision-making, which have promising practical application values.
Experimental Security Analysis of DNN-based Adaptive Cruise Control under Context-Aware Perception Attacks
Jul 18, 2023



Adaptive Cruise Control (ACC) is a widely used driver assistance feature for maintaining desired speed and safe distance to the leading vehicles. This paper evaluates the security of the deep neural network (DNN) based ACC systems under stealthy perception attacks that strategically inject perturbations into camera data to cause forward collisions. We present a combined knowledge-and-data-driven approach to design a context-aware strategy for the selection of the most critical times for triggering the attacks and a novel optimization-based method for the adaptive generation of image perturbations at run-time. We evaluate the effectiveness of the proposed attack using an actual driving dataset and a realistic simulation platform with the control software from a production ACC system and a physical-world driving simulator while considering interventions by the driver and safety features such as Automatic Emergency Braking (AEB) and Forward Collision Warning (FCW). Experimental results show that the proposed attack achieves 142.9x higher success rate in causing accidents than random attacks and is mitigated 89.6% less by the safety features while being stealthy and robust to real-world factors and dynamic changes in the environment. This study provides insights into the role of human operators and basic safety interventions in preventing attacks.
Communicating Inferred Goals with Passive Augmented Reality and Active Haptic Feedback
Sep 03, 2021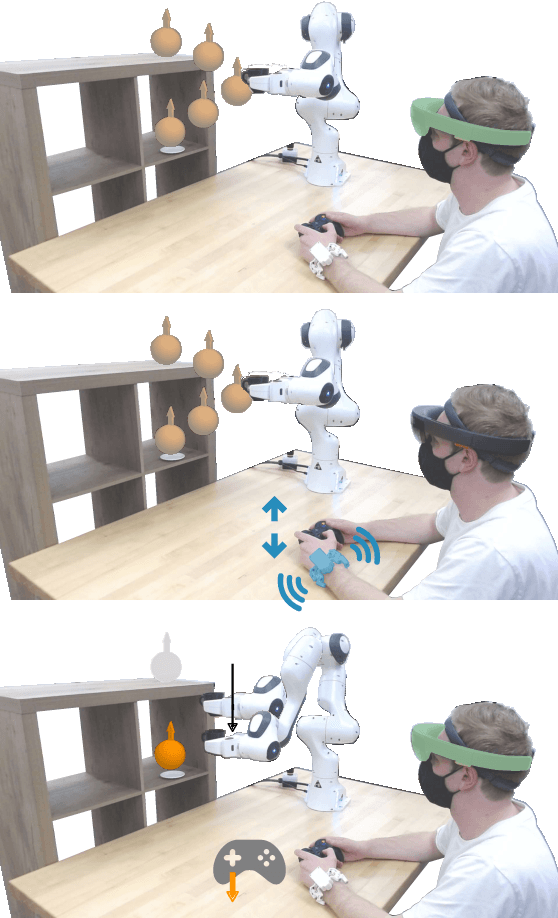
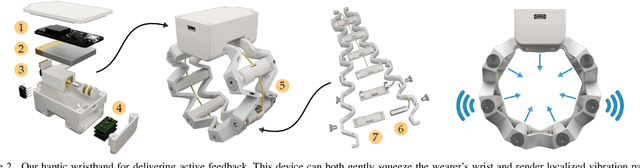

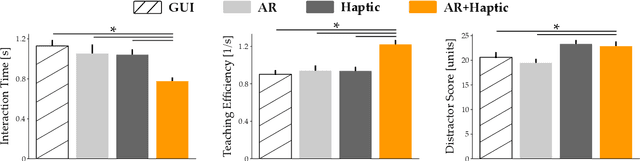
Robots learn as they interact with humans. Consider a human teleoperating an assistive robot arm: as the human guides and corrects the arm's motion, the robot gathers information about the human's desired task. But how does the human know what their robot has inferred? Today's approaches often focus on conveying intent: for instance, upon legible motions or gestures to indicate what the robot is planning. However, closing the loop on robot inference requires more than just revealing the robot's current policy: the robot should also display the alternatives it thinks are likely, and prompt the human teacher when additional guidance is necessary. In this paper we propose a multimodal approach for communicating robot inference that combines both passive and active feedback. Specifically, we leverage information-rich augmented reality to passively visualize what the robot has inferred, and attention-grabbing haptic wristbands to actively prompt and direct the human's teaching. We apply our system to shared autonomy tasks where the robot must infer the human's goal in real-time. Within this context, we integrate passive and active modalities into a single algorithmic framework that determines when and which type of feedback to provide. Combining both passive and active feedback experimentally outperforms single modality baselines; during an in-person user study, we demonstrate that our integrated approach increases how efficiently humans teach the robot while simultaneously decreasing the amount of time humans spend interacting with the robot. Videos here: https://youtu.be/swq_u4iIP-g