 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector
Apr 04, 2025



3D object detection is crucial for autonomous driving, leveraging both LiDAR point clouds for precise depth information and camera images for rich semantic information. Therefore, the multi-modal methods that combine both modalities offer more robust detection results. However, efficiently fusing LiDAR points and images remains challenging due to the domain gaps. In addition, the performance of many models is limited by the amount of high quality labeled data, which is expensive to create. The recent advances in foundation models, which use large-scale pre-training on different modalities, enable better multi-modal fusion. Combining the prompt engineering techniques for efficient training, we propose the Prompted Foundational 3D Detector (PF3Det), which integrates foundation model encoders and soft prompts to enhance LiDAR-camera feature fusion. PF3Det achieves the state-of-the-art results under limited training data, improving NDS by 1.19% and mAP by 2.42% on the nuScenes dataset, demonstrating its efficiency in 3D detection.
Improving Vision Transformers by Overlapping Heads in Multi-Head Self-Attention
Oct 18, 2024



Vision Transformers have made remarkable progress in recent years, achieving state-of-the-art performance in most vision tasks. A key component of this success is due to the introduction of the Multi-Head Self-Attention (MHSA) module, which enables each head to learn different representations by applying the attention mechanism independently. In this paper, we empirically demonstrate that Vision Transformers can be further enhanced by overlapping the heads in MHSA. We introduce Multi-Overlapped-Head Self-Attention (MOHSA), where heads are overlapped with their two adjacent heads for queries, keys, and values, while zero-padding is employed for the first and last heads, which have only one neighboring head. Various paradigms for overlapping ratios are proposed to fully investigate the optimal performance of our approach. The proposed approach is evaluated using five Transformer models on four benchmark datasets and yields a significant performance boost. The source code will be made publicly available upon publication.
Robust 3D Point Clouds Classification based on Declarative Defenders
Oct 13, 2024



3D point cloud classification requires distinct models from 2D image classification due to the divergent characteristics of the respective input data. While 3D point clouds are unstructured and sparse, 2D images are structured and dense. Bridging the domain gap between these two data types is a non-trivial challenge to enable model interchangeability. Recent research using Lattice Point Classifier (LPC) highlights the feasibility of cross-domain applicability. However, the lattice projection operation in LPC generates 2D images with disconnected projected pixels. In this paper, we explore three distinct algorithms for mapping 3D point clouds into 2D images. Through extensive experiments, we thoroughly examine and analyze their performance and defense mechanisms. Leveraging current large foundation models, we scrutinize the feature disparities between regular 2D images and projected 2D images. The proposed approaches demonstrate superior accuracy and robustness against adversarial attacks. The generative model-based mapping algorithms yield regular 2D images, further minimizing the domain gap from regular 2D classification tasks. The source code is available at https://github.com/KaidongLi/pytorch-LatticePointClassifier.git.
Depth-Wise Convolutions in Vision Transformers for Efficient Training on Small Datasets
Jul 28, 2024



The Vision Transformer (ViT) leverages the Transformer's encoder to capture global information by dividing images into patches and achieves superior performance across various computer vision tasks. However, the self-attention mechanism of ViT captures the global context from the outset, overlooking the inherent relationships between neighboring pixels in images or videos. Transformers mainly focus on global information while ignoring the fine-grained local details. Consequently, ViT lacks inductive bias during image or video dataset training. In contrast, convolutional neural networks (CNNs), with their reliance on local filters, possess an inherent inductive bias, making them more efficient and quicker to converge than ViT with less data. In this paper, we present a lightweight Depth-Wise Convolution module as a shortcut in ViT models, bypassing entire Transformer blocks to ensure the models capture both local and global information with minimal overhead. Additionally, we introduce two architecture variants, allowing the Depth-Wise Convolution modules to be applied to multiple Transformer blocks for parameter savings, and incorporating independent parallel Depth-Wise Convolution modules with different kernels to enhance the acquisition of local information. The proposed approach significantly boosts the performance of ViT models on image classification, object detection and instance segmentation by a large margin, especially on small datasets, as evaluated on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet for image classification, and COCO for object detection and instance segmentation. The source code can be accessed at https://github.com/ZTX-100/Efficient_ViT_with_DW.
Aphid Cluster Recognition and Detection in the Wild Using Deep Learning Models
Aug 10, 2023Aphid infestation poses a significant threat to crop production, rural communities, and global food security. While chemical pest control is crucial for maximizing yields, applying chemicals across entire fields is both environmentally unsustainable and costly. Hence, precise localization and management of aphids are essential for targeted pesticide application. The paper primarily focuses on using deep learning models for detecting aphid clusters. We propose a novel approach for estimating infection levels by detecting aphid clusters. To facilitate this research, we have captured a large-scale dataset from sorghum fields, manually selected 5,447 images containing aphids, and annotated each individual aphid cluster within these images. To facilitate the use of machine learning models, we further process the images by cropping them into patches, resulting in a labeled dataset comprising 151,380 image patches. Then, we implemented and compared the performance of four state-of-the-art object detection models (VFNet, GFLV2, PAA, and ATSS) on the aphid dataset. Extensive experimental results show that all models yield stable similar performance in terms of average precision and recall. We then propose to merge close neighboring clusters and remove tiny clusters caused by cropping, and the performance is further boosted by around 17%. The study demonstrates the feasibility of automatically detecting and managing insects using machine learning models. The labeled dataset will be made openly available to the research community.
On the Real-Time Semantic Segmentation of Aphid Clusters in the Wild
Jul 17, 2023



Aphid infestations can cause extensive damage to wheat and sorghum fields and spread plant viruses, resulting in significant yield losses in agriculture. To address this issue, farmers often rely on chemical pesticides, which are inefficiently applied over large areas of fields. As a result, a considerable amount of pesticide is wasted on areas without pests, while inadequate amounts are applied to areas with severe infestations. The paper focuses on the urgent need for an intelligent autonomous system that can locate and spray infestations within complex crop canopies, reducing pesticide use and environmental impact. We have collected and labeled a large aphid image dataset in the field, and propose the use of real-time semantic segmentation models to segment clusters of aphids. A multiscale dataset is generated to allow for learning the clusters at different scales. We compare the segmentation speeds and accuracy of four state-of-the-art real-time semantic segmentation models on the aphid cluster dataset, benchmarking them against nonreal-time models. The study results show the effectiveness of a real-time solution, which can reduce inefficient pesticide use and increase crop yields, paving the way towards an autonomous pest detection system.
A New Dataset and Comparative Study for Aphid Cluster Detection
Jul 12, 2023



Aphids are one of the main threats to crops, rural families, and global food security. Chemical pest control is a necessary component of crop production for maximizing yields, however, it is unnecessary to apply the chemical approaches to the entire fields in consideration of the environmental pollution and the cost. Thus, accurately localizing the aphid and estimating the infestation level is crucial to the precise local application of pesticides. Aphid detection is very challenging as each individual aphid is really small and all aphids are crowded together as clusters. In this paper, we propose to estimate the infection level by detecting aphid clusters. We have taken millions of images in the sorghum fields, manually selected 5,447 images that contain aphids, and annotated each aphid cluster in the image. To use these images for machine learning models, we crop the images into patches and created a labeled dataset with over 151,000 image patches. Then, we implement and compare the performance of four state-of-the-art object detection models.
Gender, Smoking History and Age Prediction from Laryngeal Images
May 26, 2023



Flexible laryngoscopy is commonly performed by otolaryngologists to detect laryngeal diseases and to recognize potentially malignant lesions. Recently, researchers have introduced machine learning techniques to facilitate automated diagnosis using laryngeal images and achieved promising results. Diagnostic performance can be improved when patients' demographic information is incorporated into models. However, manual entry of patient data is time consuming for clinicians. In this study, we made the first endeavor to employ deep learning models to predict patient demographic information to improve detector model performance. The overall accuracy for gender, smoking history, and age was 85.5%, 65.2%, and 75.9%, respectively. We also created a new laryngoscopic image set for machine learning study and benchmarked the performance of 8 classical deep learning models based on CNNs and Transformers. The results can be integrated into current learning models to improve their performance by incorporating the patient's demographic information.
Dynamic Label Assignment for Object Detection by Combining Predicted and Anchor IoUs
Jan 23, 2022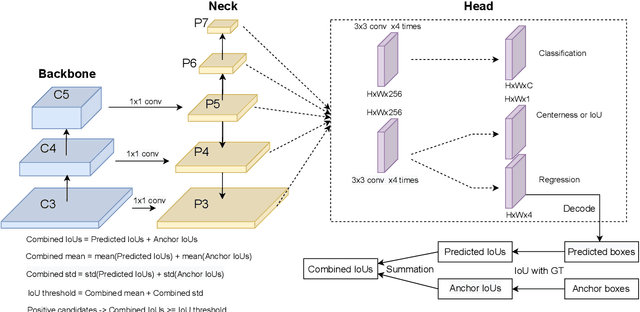
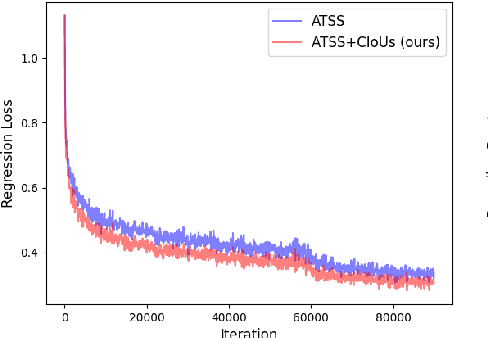
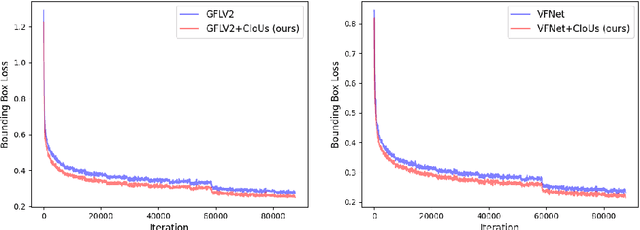
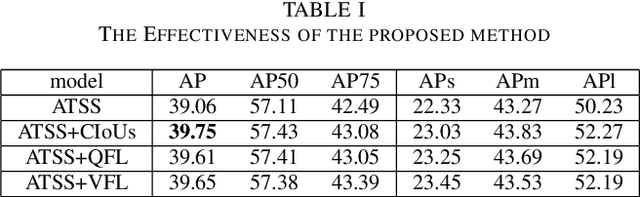
Label assignment plays a significant role in modern object detection models. Detection models may yield totally different performances with different label assignment strategies. For anchor-based detection models, the IoU threshold between the anchors and their corresponding ground truth bounding boxes is the key element since the positive samples and negative samples are divided by the IoU threshold. Early object detectors simply utilize a fixed threshold for all training samples, while recent detection algorithms focus on adaptive thresholds based on the distribution of the IoUs to the ground truth boxes. In this paper, we introduce a simple and effective approach to perform label assignment dynamically based on the training status with predictions. By introducing the predictions in label assignment, more high-quality samples with higher IoUs to the ground truth objects are selected as the positive samples, which could reduce the discrepancy between the classification scores and the IoU scores, and generate more high-quality boundary boxes. Our approach shows improvements in the performance of the detection models with the adaptive label assignment algorithm and lower bounding box losses for those positive samples, indicating more samples with higher quality predicted boxes are selected as positives. The source code will be available at https://github.com/ZTX-100/DLA-Combined-IoUs.
An Unsupervised Domain Adaptation Model based on Dual-module Adversarial Training
Dec 31, 2021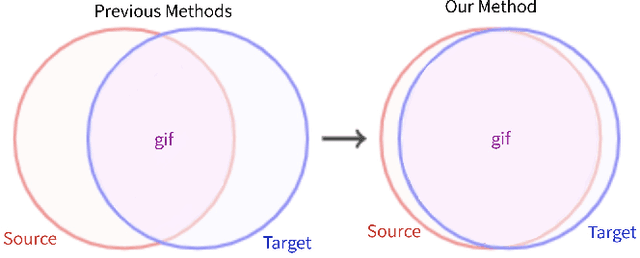
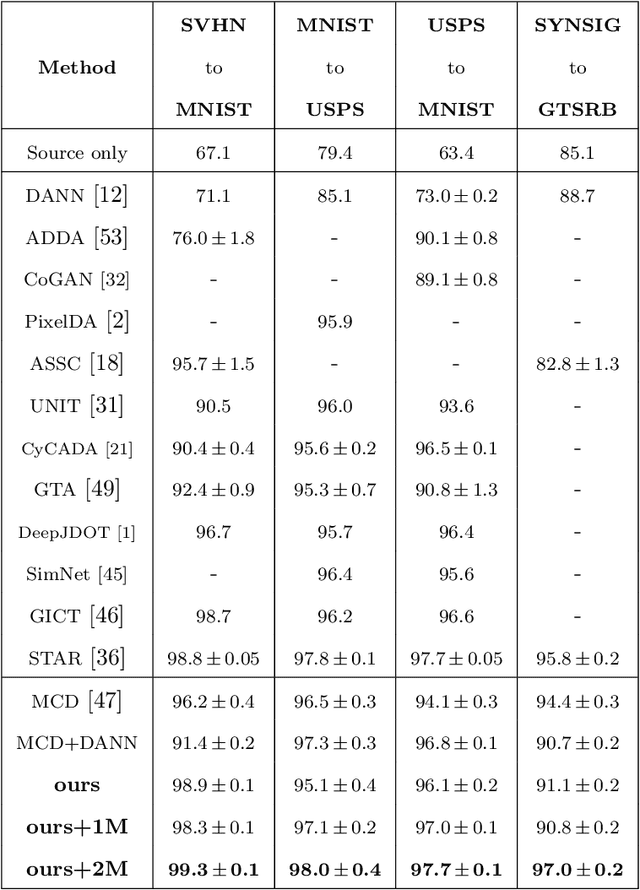
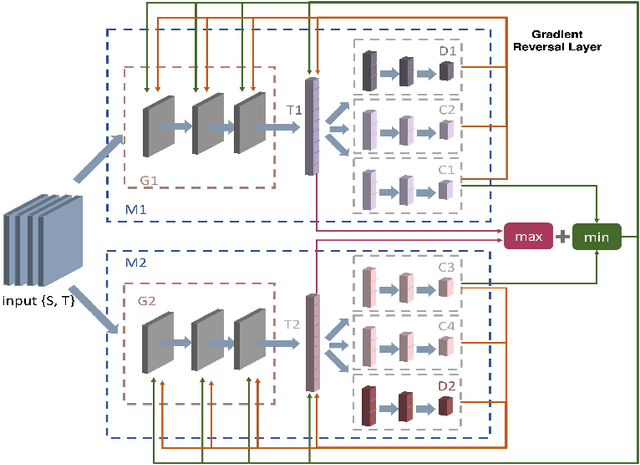
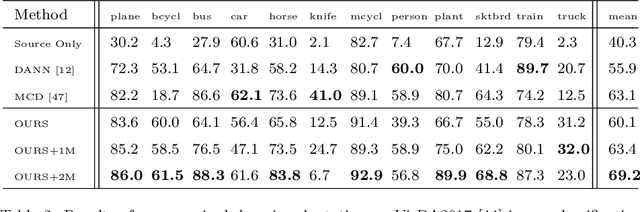
In this paper, we propose a dual-module network architecture that employs a domain discriminative feature module to encourage the domain invariant feature module to learn more domain invariant features. The proposed architecture can be applied to any model that utilizes domain invariant features for unsupervised domain adaptation to improve its ability to extract domain invariant features. We conduct experiments with the Domain-Adversarial Training of Neural Networks (DANN) model as a representative algorithm. In the training process, we supply the same input to the two modules and then extract their feature distribution and prediction results respectively. We propose a discrepancy loss to find the discrepancy of the prediction results and the feature distribution between the two modules. Through the adversarial training by maximizing the loss of their feature distribution and minimizing the discrepancy of their prediction results, the two modules are encouraged to learn more domain discriminative and domain invariant features respectively. Extensive comparative evaluations are conducted and the proposed approach outperforms the state-of-the-art in most unsupervised domain adaptation tasks.