 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quilt-1M: One Million Image-Text Pairs for Histopathology
Jun 22, 2023
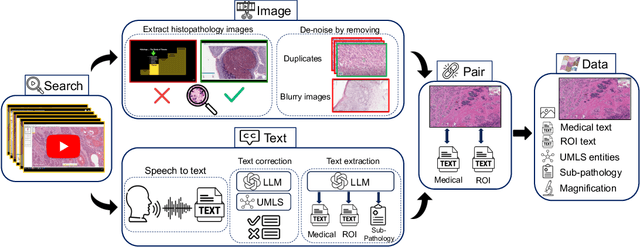
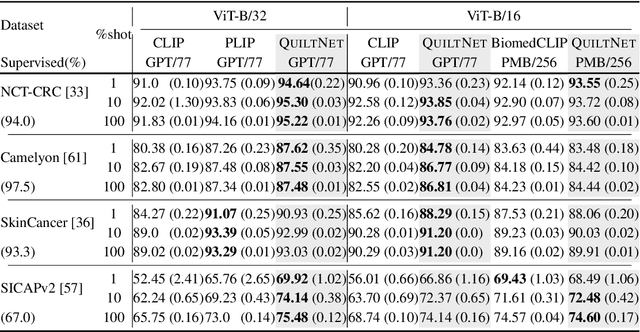
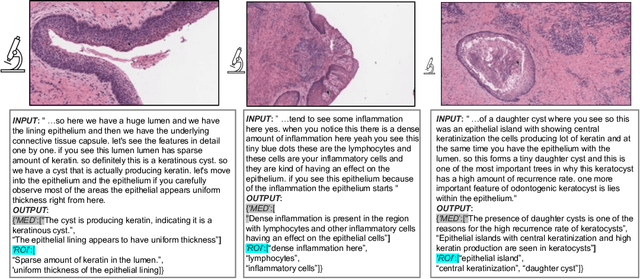
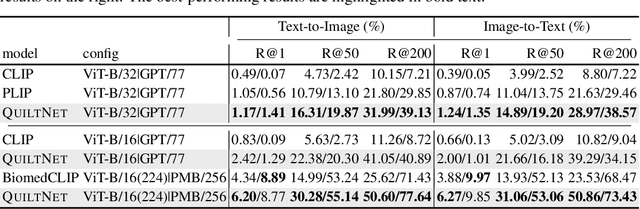
Recent accelerations in multi-modal applications have been made possible with the plethora of image and text data available online. However, the scarcity of analogous data in the medical field, specifically in histopathology, has halted comparable progress. To enable similar representation learning for histopathology, we turn to YouTube, an untapped resource of videos, offering $1,087$ hours of valuable educational histopathology videos from expert clinicians. From YouTube, we curate Quilt: a large-scale vision-language dataset consisting of $768,826$ image and text pairs. Quilt was automatically curated using a mixture of models, including large language models, handcrafted algorithms, human knowledge databases, and automatic speech recognition. In comparison, the most comprehensive datasets curated for histopathology amass only around $200$K samples. We combine Quilt with datasets from other sources, including Twitter, research papers, and the internet in general, to create an even larger dataset: Quilt-1M, with $1$M paired image-text samples, marking it as the largest vision-language histopathology dataset to date. We demonstrate the value of Quilt-1M by fine-tuning a pre-trained CLIP model. Our model outperforms state-of-the-art models on both zero-shot and linear probing tasks for classifying new histopathology images across $13$ diverse patch-level datasets of $8$ different sub-pathologies and cross-modal retrieval tasks.
Zero shot framework for satellite image restoration
Jun 05, 2023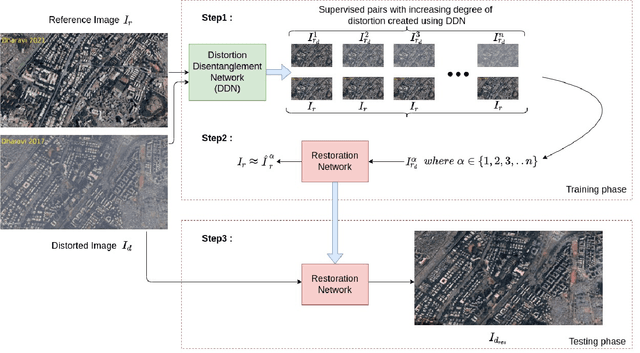


Satellite images are typically subject to multiple distortions. Different factors affect the quality of satellite images, including changes in atmosphere, surface reflectance, sun illumination, viewing geometries etc., limiting its application to downstream tasks. In supervised networks, the availability of paired datasets is a strong assumption. Consequently, many unsupervised algorithms have been proposed to address this problem. These methods synthetically generate a large dataset of degraded images using image formation models. A neural network is then trained with an adversarial loss to discriminate between images from distorted and clean domains. However, these methods yield suboptimal performance when tested on real images that do not necessarily conform to the generation mechanism. Also, they require a large amount of training data and are rendered unsuitable when only a few images are available. We propose a distortion disentanglement and knowledge distillation framework for satellite image restoration to address these important issues. Our algorithm requires only two images: the distorted satellite image to be restored and a reference image with similar semantics. Specifically, we first propose a mechanism to disentangle distortion. This enables us to generate images with varying degrees of distortion using the disentangled distortion and the reference image. We then propose the use of knowledge distillation to train a restoration network using the generated image pairs. As a final step, the distorted image is passed through the restoration network to get the final output. Ablation studies show that our proposed mechanism successfully disentangles distortion.
OpenIns3D: Snap and Lookup for 3D Open-vocabulary Instance Segmentation
Sep 04, 2023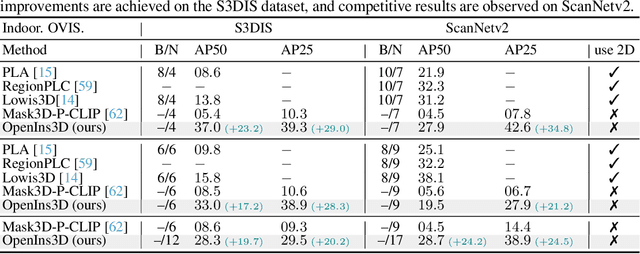
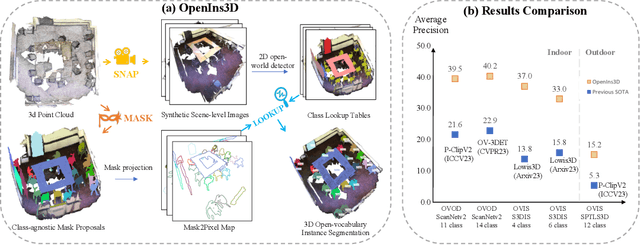
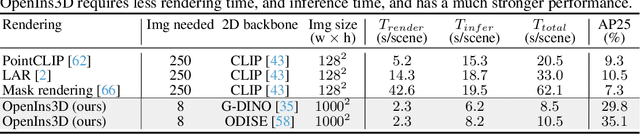
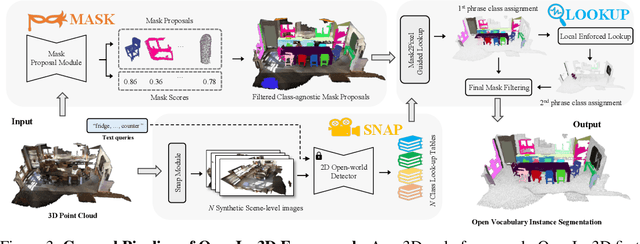
Current 3D open-vocabulary scene understanding methods mostly utilize well-aligned 2D images as the bridge to learn 3D features with language. However, applying these approaches becomes challenging in scenarios where 2D images are absent. In this work, we introduce a completely new pipeline, namely, OpenIns3D, which requires no 2D image inputs, for 3D open-vocabulary scene understanding at the instance level. The OpenIns3D framework employs a "Mask-Snap-Lookup" scheme. The "Mask" module learns class-agnostic mask proposals in 3D point clouds. The "Snap" module generates synthetic scene-level images at multiple scales and leverages 2D vision language models to extract interesting objects. The "Lookup" module searches through the outcomes of "Snap" with the help of Mask2Pixel maps, which contain the precise correspondence between 3D masks and synthetic images, to assign category names to the proposed masks. This 2D input-free, easy-to-train, and flexible approach achieved state-of-the-art results on a wide range of indoor and outdoor datasets with a large margin. Furthermore, OpenIns3D allows for effortless switching of 2D detectors without re-training. When integrated with state-of-the-art 2D open-world models such as ODISE and GroundingDINO, superb results are observed on open-vocabulary instance segmentation. When integrated with LLM-powered 2D models like LISA, it demonstrates a remarkable capacity to process highly complex text queries, including those that require intricate reasoning and world knowledge. Project page: https://zheninghuang.github.io/OpenIns3D/
Accurate 2D Reconstruction for PET Scanners based on the Analytical White Image Model
Jun 30, 2023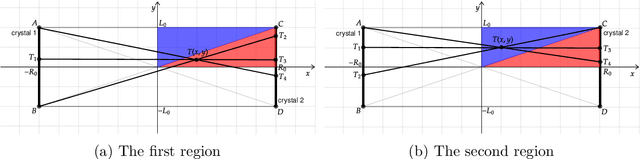

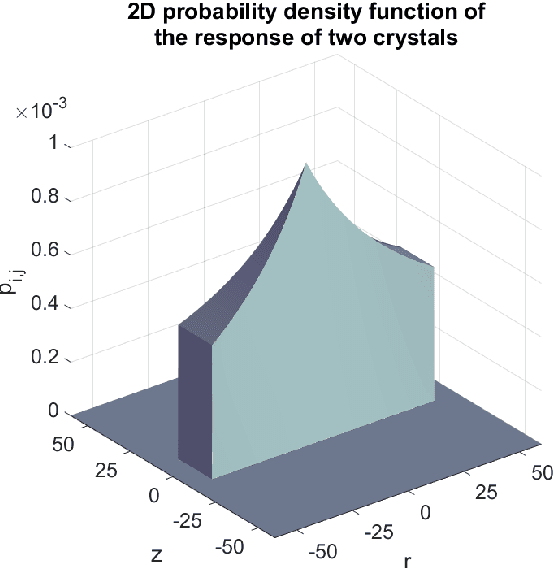
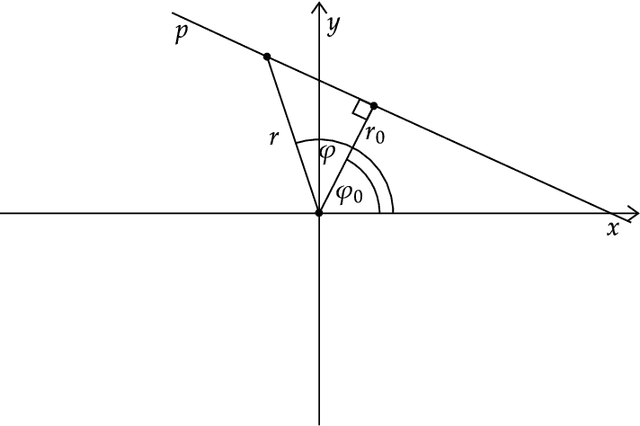
In this paper, we provide a precise mathematical model of crystal-to-crystal response which is used to generate the white image - a necessary compensation model needed to overcome the physical limitations of the PET scanner. We present a closed-form solution, as well as several accurate approximations, due to the complexity of the exact mathematical expressions. We prove, experimentally and analytically, that the difference between the best approximations and real crystal-to-crystal response is insignificant. The obtained responses are used to generate the white image compensation model. It can be written as a single closed-form expression making it easy to implement in known reconstruction methods. The maximum likelihood expectation maximization (MLEM) algorithm is modified and our white image model is integrated into it. The modified MLEM algorithm is not based on the system matrix, rather it is based on ray-driven projections and back-projections. The compensation model provides all necessary information about the system. Finally, we check our approach on synthetic and real data. For the real-world acquisition, we use the Raytest ClearPET camera for small animals and the NEMA NU 4-2008 phantom. The proposed approach overperforms competitive, non-compensated reconstruction methods.
NeO 360: Neural Fields for Sparse View Synthesis of Outdoor Scenes
Aug 24, 2023

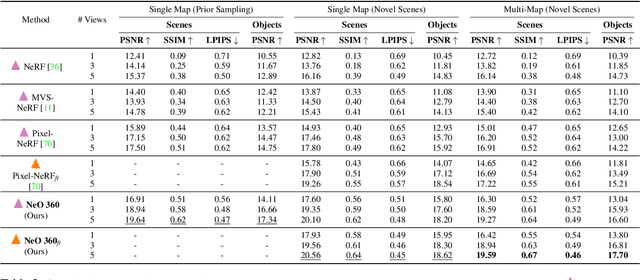
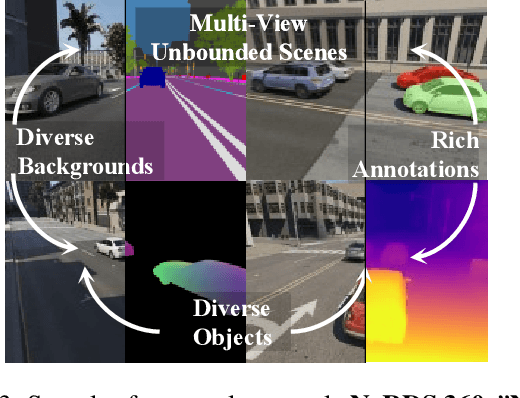
Recent implicit neural representations have shown great results for novel view synthesis. However, existing methods require expensive per-scene optimization from many views hence limiting their application to real-world unbounded urban settings where the objects of interest or backgrounds are observed from very few views. To mitigate this challenge, we introduce a new approach called NeO 360, Neural fields for sparse view synthesis of outdoor scenes. NeO 360 is a generalizable method that reconstructs 360{\deg} scenes from a single or a few posed RGB images. The essence of our approach is in capturing the distribution of complex real-world outdoor 3D scenes and using a hybrid image-conditional triplanar representation that can be queried from any world point. Our representation combines the best of both voxel-based and bird's-eye-view (BEV) representations and is more effective and expressive than each. NeO 360's representation allows us to learn from a large collection of unbounded 3D scenes while offering generalizability to new views and novel scenes from as few as a single image during inference. We demonstrate our approach on the proposed challenging 360{\deg} unbounded dataset, called NeRDS 360, and show that NeO 360 outperforms state-of-the-art generalizable methods for novel view synthesis while also offering editing and composition capabilities. Project page: https://zubair-irshad.github.io/projects/neo360.html
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Aug 19, 2023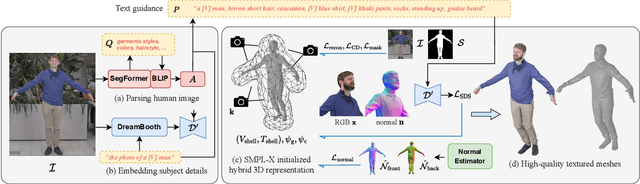

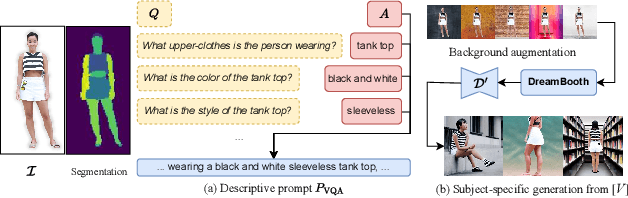
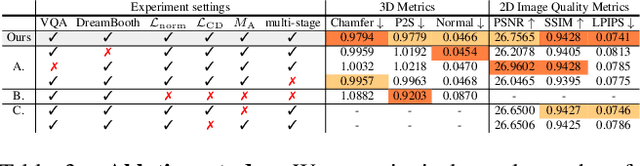
Despite recent research advancements in reconstructing clothed humans from a single image, accurately restoring the "unseen regions" with high-level details remains an unsolved challenge that lacks attention. Existing methods often generate overly smooth back-side surfaces with a blurry texture. But how to effectively capture all visual attributes of an individual from a single image, which are sufficient to reconstruct unseen areas (e.g., the back view)? Motivated by the power of foundation models, TeCH reconstructs the 3D human by leveraging 1) descriptive text prompts (e.g., garments, colors, hairstyles) which are automatically generated via a garment parsing model and Visual Question Answering (VQA), 2) a personalized fine-tuned Text-to-Image diffusion model (T2I) which learns the "indescribable" appearance. To represent high-resolution 3D clothed humans at an affordable cost, we propose a hybrid 3D representation based on DMTet, which consists of an explicit body shape grid and an implicit distance field. Guided by the descriptive prompts + personalized T2I diffusion model, the geometry and texture of the 3D humans are optimized through multi-view Score Distillation Sampling (SDS) and reconstruction losses based on the original observation. TeCH produces high-fidelity 3D clothed humans with consistent & delicate texture, and detailed full-body geometry. Quantitative and qualitative experiments demonstrate that TeCH outperforms the state-of-the-art methods in terms of reconstruction accuracy and rendering quality. The code will be publicly available for research purposes at https://huangyangyi.github.io/TeCH
Learning to Distill Global Representation for Sparse-View CT
Aug 19, 2023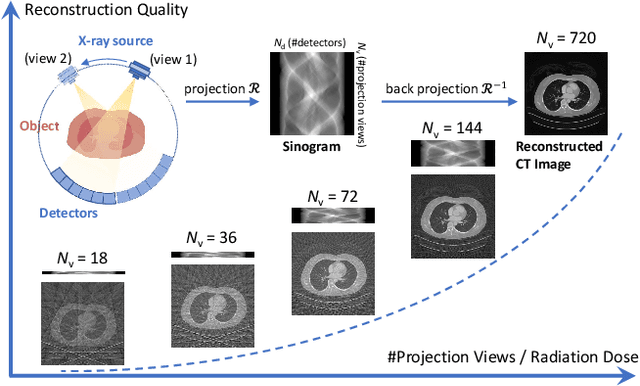
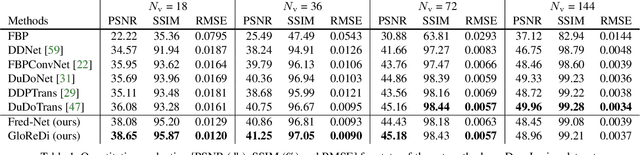
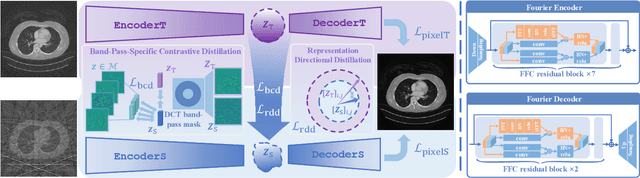
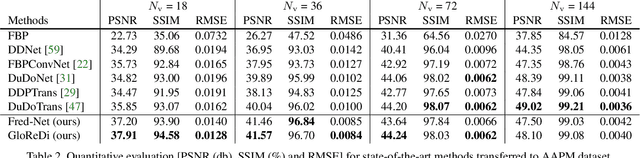
Sparse-view computed tomography (CT) -- using a small number of projections for tomographic reconstruction -- enables much lower radiation dose to patients and accelerated data acquisition. The reconstructed images, however, suffer from strong artifacts, greatly limiting their diagnostic value. Current trends for sparse-view CT turn to the raw data for better information recovery. The resultant dual-domain methods, nonetheless, suffer from secondary artifacts, especially in ultra-sparse view scenarios, and their generalization to other scanners/protocols is greatly limited. A crucial question arises: have the image post-processing methods reached the limit? Our answer is not yet. In this paper, we stick to image post-processing methods due to great flexibility and propose global representation (GloRe) distillation framework for sparse-view CT, termed GloReDi. First, we propose to learn GloRe with Fourier convolution, so each element in GloRe has an image-wide receptive field. Second, unlike methods that only use the full-view images for supervision, we propose to distill GloRe from intermediate-view reconstructed images that are readily available but not explored in previous literature. The success of GloRe distillation is attributed to two key components: representation directional distillation to align the GloRe directions, and band-pass-specific contrastive distillation to gain clinically important details. Extensive experiments demonstrate the superiority of the proposed GloReDi over the state-of-the-art methods, including dual-domain ones. The source code is available at https://github.com/longzilicart/GloReDi.
CellGAN: Conditional Cervical Cell Synthesis for Augmenting Cytopathological Image Classification
Jul 12, 2023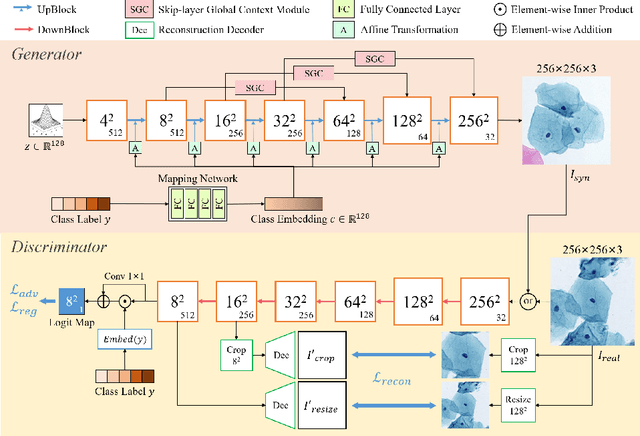

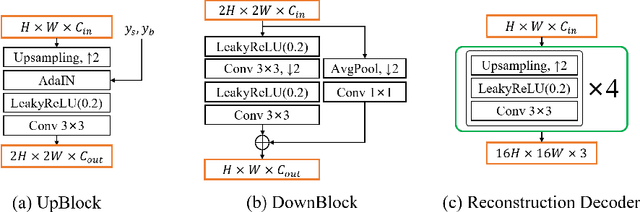
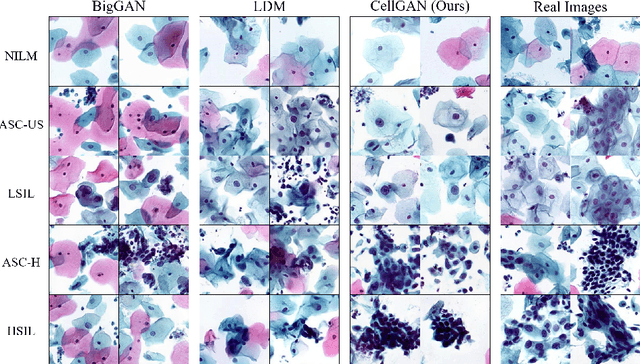
Automatic examination of thin-prep cytologic test (TCT) slides can assist pathologists in finding cervical abnormality for accurate and efficient cancer screening. Current solutions mostly need to localize suspicious cells and classify abnormality based on local patches, concerning the fact that whole slide images of TCT are extremely large. It thus requires many annotations of normal and abnormal cervical cells, to supervise the training of the patch-level classifier for promising performance. In this paper, we propose CellGAN to synthesize cytopathological images of various cervical cell types for augmenting patch-level cell classification. Built upon a lightweight backbone, CellGAN is equipped with a non-linear class mapping network to effectively incorporate cell type information into image generation. We also propose the Skip-layer Global Context module to model the complex spatial relationship of the cells, and attain high fidelity of the synthesized images through adversarial learning. Our experiments demonstrate that CellGAN can produce visually plausible TCT cytopathological images for different cell types. We also validate the effectiveness of using CellGAN to greatly augment patch-level cell classification performance.
Partition-and-Debias: Agnostic Biases Mitigation via A Mixture of Biases-Specific Experts
Aug 19, 2023Bias mitigation in image classification has been widely researched, and existing methods have yielded notable results. However, most of these methods implicitly assume that a given image contains only one type of known or unknown bias, failing to consider the complexities of real-world biases. We introduce a more challenging scenario, agnostic biases mitigation, aiming at bias removal regardless of whether the type of bias or the number of types is unknown in the datasets. To address this difficult task, we present the Partition-and-Debias (PnD) method that uses a mixture of biases-specific experts to implicitly divide the bias space into multiple subspaces and a gating module to find a consensus among experts to achieve debiased classification. Experiments on both public and constructed benchmarks demonstrated the efficacy of the PnD. Code is available at: https://github.com/Jiaxuan-Li/PnD.
Interferometric lensless imaging: rank-one projections of image frequencies with speckle illuminations
Jun 22, 2023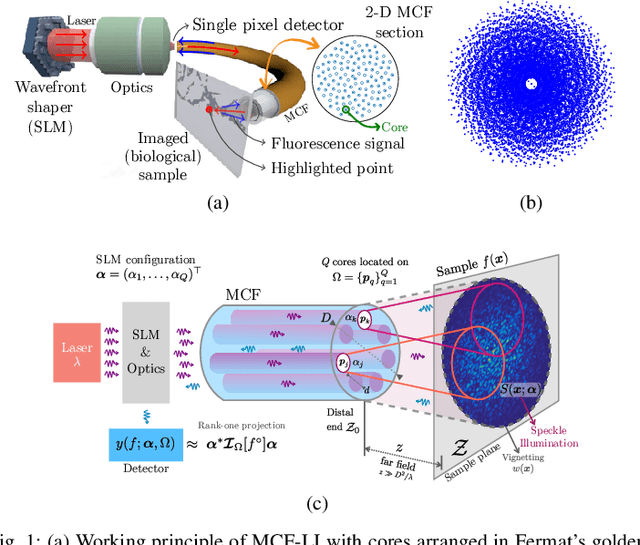
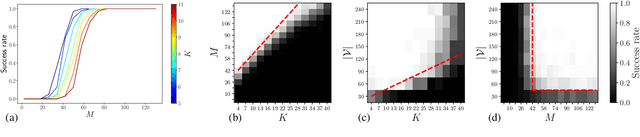

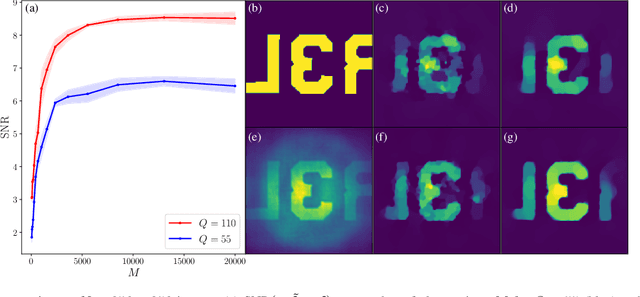
Lensless illumination single-pixel imaging with a multicore fiber (MCF) is a computational imaging technique that enables potential endoscopic observations of biological samples at cellular scale. In this work, we show that this technique is tantamount to collecting multiple symmetric rank-one projections (SROP) of an interferometric matrix--a matrix encoding the spectral content of the sample image. In this model, each SROP is induced by the complex sketching vector shaping the incident light wavefront with a spatial light modulator (SLM), while the projected interferometric matrix collects up to $O(Q^2)$ image frequencies for a $Q$-core MCF. While this scheme subsumes previous sensing modalities, such as raster scanning (RS) imaging with beamformed illumination, we demonstrate that collecting the measurements of $M$ random SLM configurations--and thus acquiring $M$ SROPs--allows us to estimate an image of interest if $M$ and $Q$ scale log-linearly with the image sparsity level This demonstration is achieved both theoretically, with a specific restricted isometry analysis of the sensing scheme, and with extensive Monte Carlo experiments. On a practical side, we perform a single calibration of the sensing system robust to certain deviations to the theoretical model and independent of the sketching vectors used during the imaging phase. Experimental results made on an actual MCF system demonstrate the effectiveness of this imaging procedure on a benchmark image.