 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discovering Image Usage Online: A Case Study With "Flatten the Curve''
Jul 12, 2023
Understanding the spread of images across the web helps us understand the reuse of scientific visualizations and their relationship with the public. The "Flatten the Curve" graphic was heavily used during the COVID-19 pandemic to convey a complex concept in a simple form. It displays two curves comparing the impact on case loads for medical facilities if the populace either adopts or fails to adopt protective measures during a pandemic. We use five variants of the "Flatten the Curve" image as a case study for viewing the spread of an image online. To evaluate its spread, we leverage three information channels: reverse image search engines, social media, and web archives. Reverse image searches give us a current view into image reuse. Social media helps us understand a variant's popularity over time. Web archives help us see when it was preserved, highlighting a view of popularity for future researchers. Our case study leverages document URLs can be used as a proxy for images when studying the spread of images online.
Latency-aware Unified Dynamic Networks for Efficient Image Recognition
Aug 30, 2023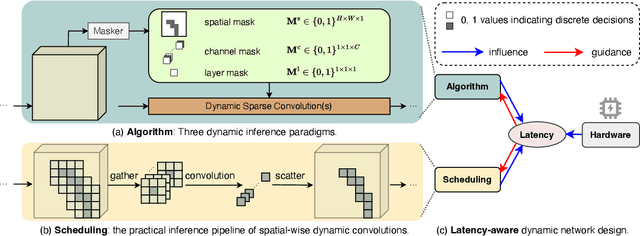

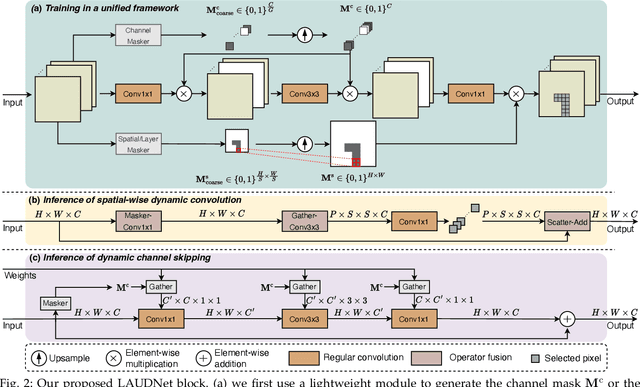
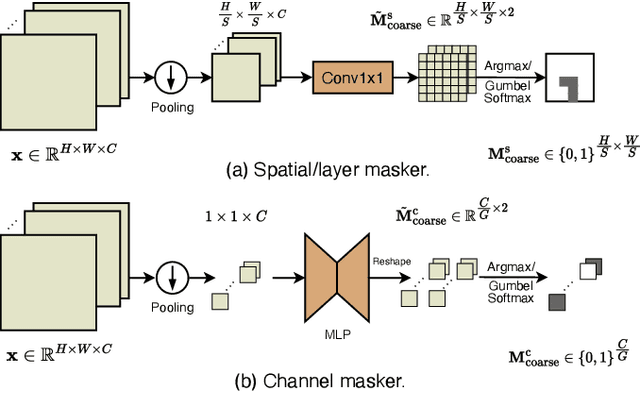
Dynamic computation has emerged as a promising avenue to enhance the inference efficiency of deep networks. It allows selective activation of computational units, leading to a reduction in unnecessary computations for each input sample. However, the actual efficiency of these dynamic models can deviate from theoretical predictions. This mismatch arises from: 1) the lack of a unified approach due to fragmented research; 2) the focus on algorithm design over critical scheduling strategies, especially in CUDA-enabled GPU contexts; and 3) challenges in measuring practical latency, given that most libraries cater to static operations. Addressing these issues, we unveil the Latency-Aware Unified Dynamic Networks (LAUDNet), a framework that integrates three primary dynamic paradigms-spatially adaptive computation, dynamic layer skipping, and dynamic channel skipping. To bridge the theoretical and practical efficiency gap, LAUDNet merges algorithmic design with scheduling optimization, guided by a latency predictor that accurately gauges dynamic operator latency. We've tested LAUDNet across multiple vision tasks, demonstrating its capacity to notably reduce the latency of models like ResNet-101 by over 50% on platforms such as V100, RTX3090, and TX2 GPUs. Notably, LAUDNet stands out in balancing accuracy and efficiency. Code is available at: https://www.github.com/LeapLabTHU/LAUDNet.
Background Activation Suppression for Weakly Supervised Object Localization and Semantic Segmentation
Sep 22, 2023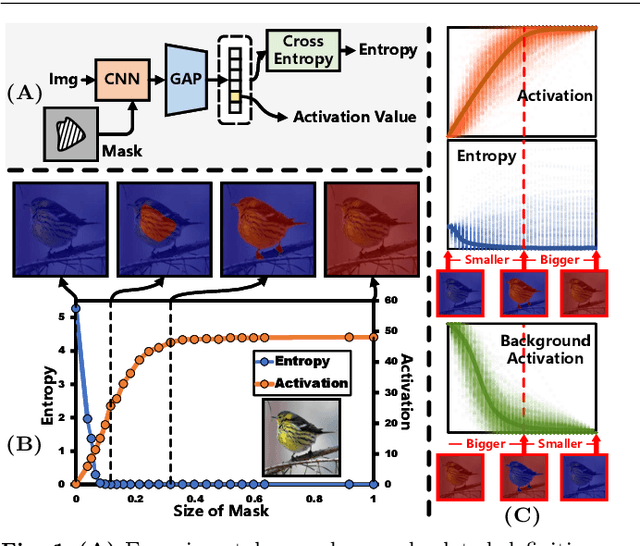
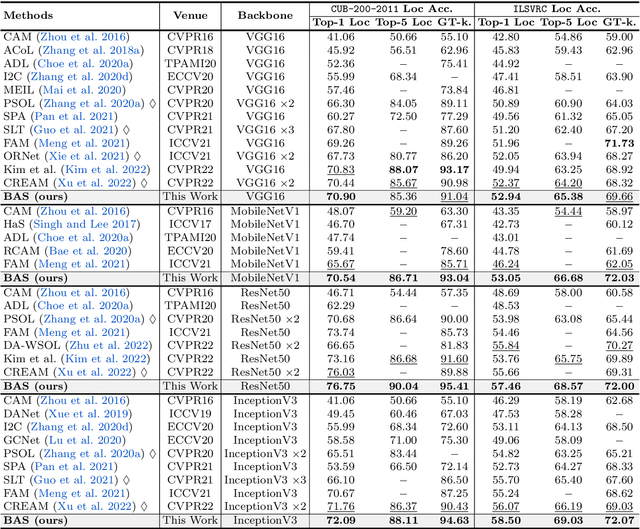
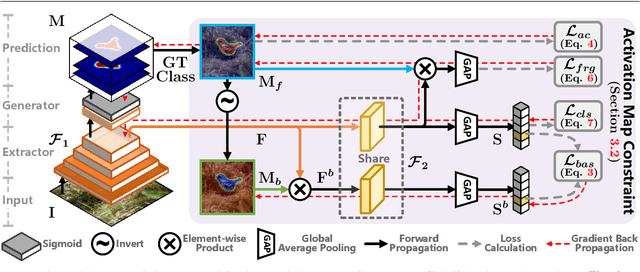
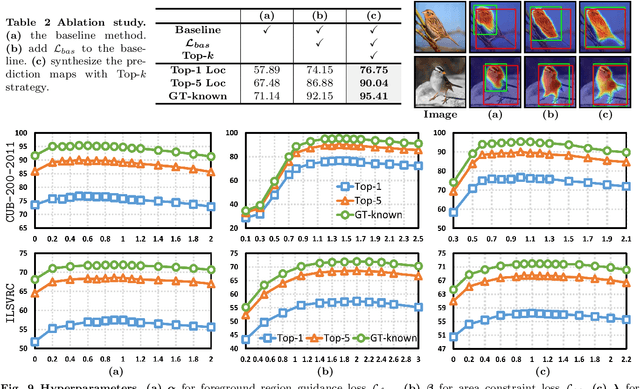
Weakly supervised object localization and semantic segmentation aim to localize objects using only image-level labels. Recently, a new paradigm has emerged by generating a foreground prediction map (FPM) to achieve pixel-level localization. While existing FPM-based methods use cross-entropy to evaluate the foreground prediction map and to guide the learning of the generator, this paper presents two astonishing experimental observations on the object localization learning process: For a trained network, as the foreground mask expands, 1) the cross-entropy converges to zero when the foreground mask covers only part of the object region. 2) The activation value continuously increases until the foreground mask expands to the object boundary. Therefore, to achieve a more effective localization performance, we argue for the usage of activation value to learn more object regions. In this paper, we propose a Background Activation Suppression (BAS) method. Specifically, an Activation Map Constraint (AMC) module is designed to facilitate the learning of generator by suppressing the background activation value. Meanwhile, by using foreground region guidance and area constraint, BAS can learn the whole region of the object. In the inference phase, we consider the prediction maps of different categories together to obtain the final localization results. Extensive experiments show that BAS achieves significant and consistent improvement over the baseline methods on the CUB-200-2011 and ILSVRC datasets. In addition, our method also achieves state-of-the-art weakly supervised semantic segmentation performance on the PASCAL VOC 2012 and MS COCO 2014 datasets. Code and models are available at https://github.com/wpy1999/BAS-Extension.
Diffusion Augmentation for Sequential Recommendation
Sep 22, 2023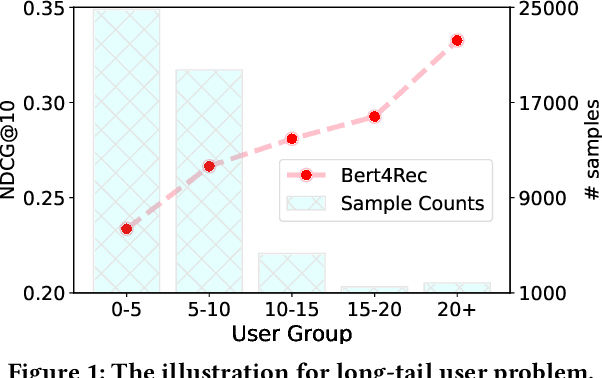
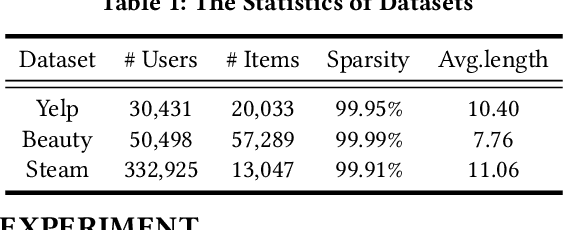
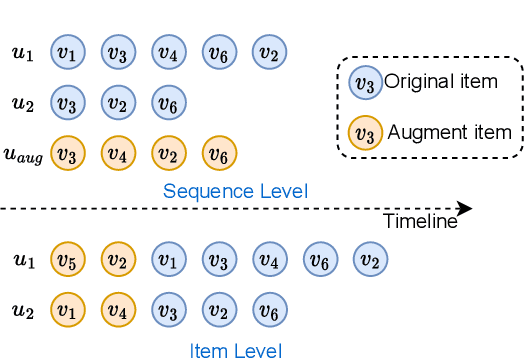
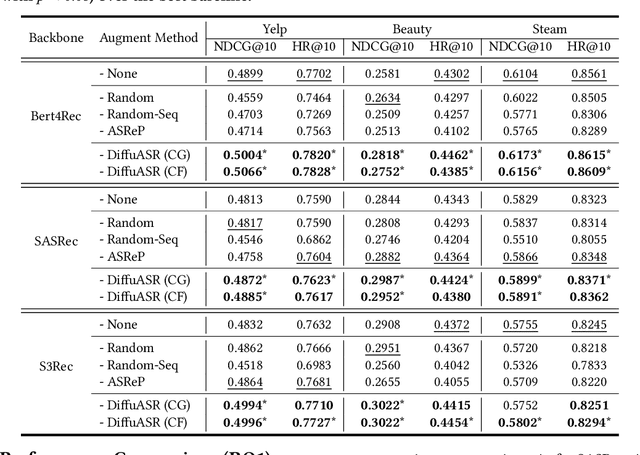
Sequential recommendation (SRS) has become the technical foundation in many applications recently, which aims to recommend the next item based on the user's historical interactions. However, sequential recommendation often faces the problem of data sparsity, which widely exists in recommender systems. Besides, most users only interact with a few items, but existing SRS models often underperform these users. Such a problem, named the long-tail user problem, is still to be resolved. Data augmentation is a distinct way to alleviate these two problems, but they often need fabricated training strategies or are hindered by poor-quality generated interactions. To address these problems, we propose a Diffusion Augmentation for Sequential Recommendation (DiffuASR) for a higher quality generation. The augmented dataset by DiffuASR can be used to train the sequential recommendation models directly, free from complex training procedures. To make the best of the generation ability of the diffusion model, we first propose a diffusion-based pseudo sequence generation framework to fill the gap between image and sequence generation. Then, a sequential U-Net is designed to adapt the diffusion noise prediction model U-Net to the discrete sequence generation task. At last, we develop two guide strategies to assimilate the preference between generated and origin sequences. To validate the proposed DiffuASR, we conduct extensive experiments on three real-world datasets with three sequential recommendation models. The experimental results illustrate the effectiveness of DiffuASR. As far as we know, DiffuASR is one pioneer that introduce the diffusion model to the recommendation.
Demographic Disparities in 1-to-Many Facial Identification
Sep 08, 2023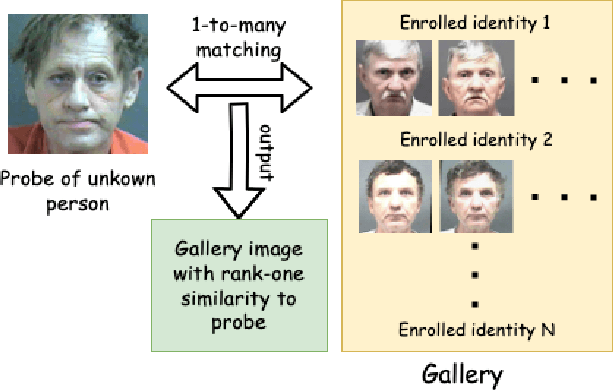

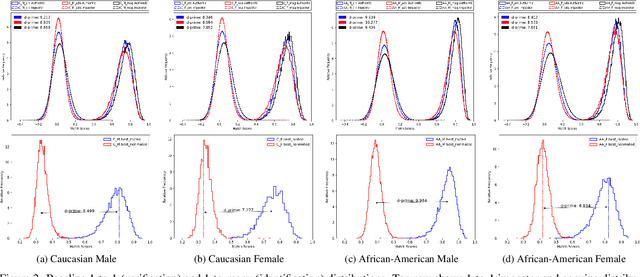
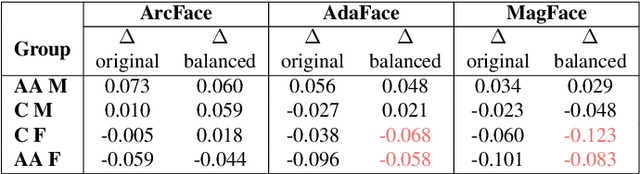
Most studies to date that have examined demographic variations in face recognition accuracy have analyzed 1-to-1 matching accuracy, using images that could be described as "government ID quality". This paper analyzes the accuracy of 1-to-many facial identification across demographic groups, and in the presence of blur and reduced resolution in the probe image as might occur in "surveillance camera quality" images. Cumulative match characteristic curves(CMC) are not appropriate for comparing propensity for rank-one recognition errors across demographics, and so we introduce three metrics for this: (1) d' metric between mated and non-mated score distributions, (2) absolute score difference between thresholds in the high-similarity tail of the non-mated and the low-similarity tail of the mated distribution, and (3) distribution of (mated - non-mated rank one scores) across the set of probe images. We find that demographic variation in 1-to-many accuracy does not entirely follow what has been observed in 1-to-1 matching accuracy. Also, different from 1-to-1 accuracy, demographic comparison of 1-to-many accuracy can be affected by different numbers of identities and images across demographics. Finally, we show that increased blur in the probe image, or reduced resolution of the face in the probe image, can significantly increase the false positive identification rate. And we show that the demographic variation in these high blur or low resolution conditions is much larger for male/ female than for African-American / Caucasian. The point that 1-to-many accuracy can potentially collapse in the context of processing "surveillance camera quality" probe images against a "government ID quality" gallery is an important one.
Feature Activation Map: Visual Explanation of Deep Learning Models for Image Classification
Jul 11, 2023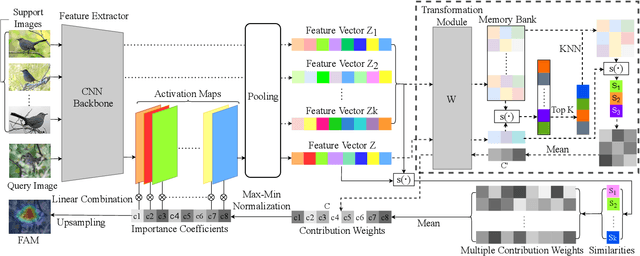
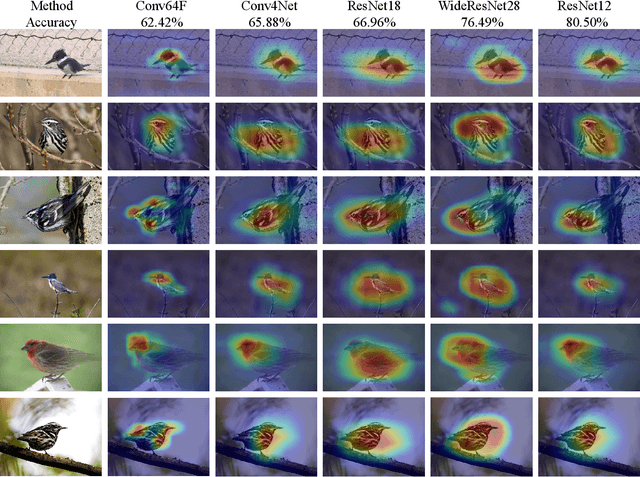
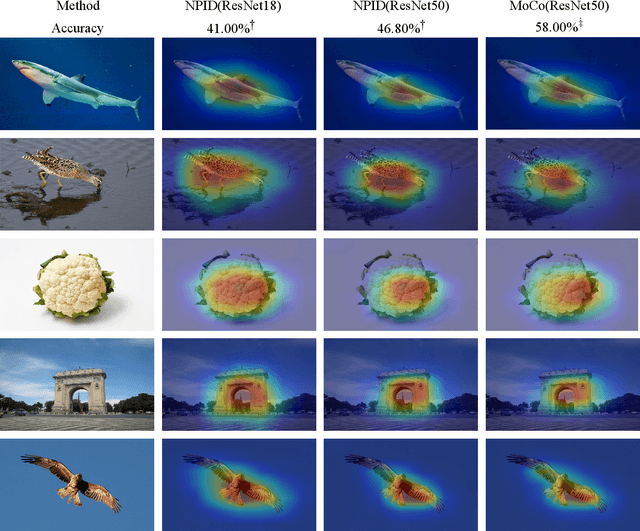

Decisions made by convolutional neural networks(CNN) can be understood and explained by visualizing discriminative regions on images. To this end, Class Activation Map (CAM) based methods were proposed as powerful interpretation tools, making the prediction of deep learning models more explainable, transparent, and trustworthy. However, all the CAM-based methods (e.g., CAM, Grad-CAM, and Relevance-CAM) can only be used for interpreting CNN models with fully-connected (FC) layers as a classifier. It is worth noting that many deep learning models classify images without FC layers, e.g., few-shot learning image classification, contrastive learning image classification, and image retrieval tasks. In this work, a post-hoc interpretation tool named feature activation map (FAM) is proposed, which can interpret deep learning models without FC layers as a classifier. In the proposed FAM algorithm, the channel-wise contribution weights are derived from the similarity scores between two image embeddings. The activation maps are linearly combined with the corresponding normalized contribution weights, forming the explanation map for visualization. The quantitative and qualitative experiments conducted on ten deep learning models for few-shot image classification, contrastive learning image classification and image retrieval tasks demonstrate the effectiveness of the proposed FAM algorithm.
Stimulating the Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling
Jul 08, 2023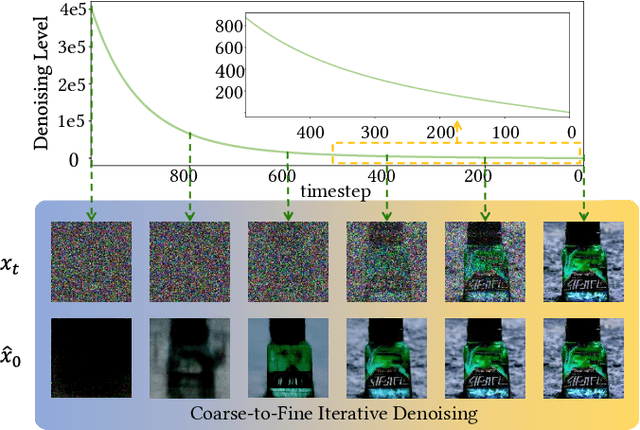
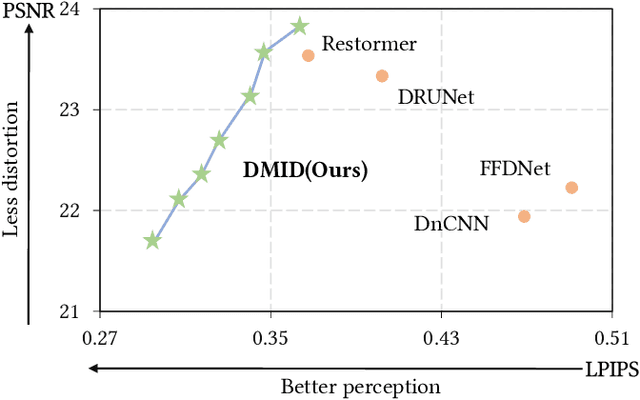
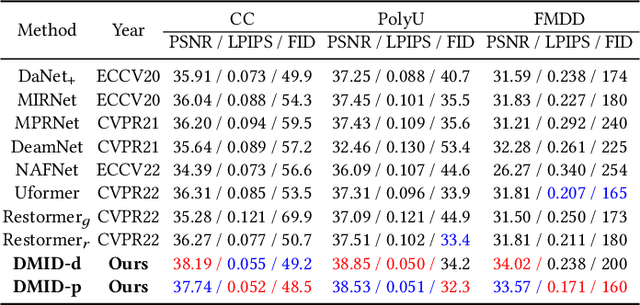
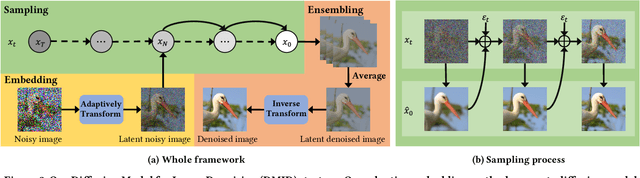
Image denoising is a fundamental problem in computational photography, where achieving high-quality perceptual performance with low distortion is highly demanding. Current methods either struggle with perceptual performance or suffer from significant distortion. Recently, the emerging diffusion model achieves state-of-the-art performance in various tasks, and its denoising mechanism demonstrates great potential for image denoising. However, stimulating diffusion models for image denoising is not straightforward and requires solving several critical problems. On the one hand, the input inconsistency hinders the connection of diffusion models and image denoising. On the other hand, the content inconsistency between the generated image and the desired denoised image introduces additional distortion. To tackle these problems, we present a novel strategy called Diffusion Model for Image Denoising (DMID) by understanding and rethinking the diffusion model from a denoising perspective. Our DMID strategy includes an adaptive embedding method that embeds the noisy image into a pre-trained diffusion model, and an adaptive ensembling method that reduces distortion in the denoised image. Our DMID strategy achieves state-of-the-art performance on all distortion-based and perceptual metrics, for both Gaussian and real-world image denoising.
DenseMP: Unsupervised Dense Pre-training for Few-shot Medical Image Segmentation
Jul 13, 2023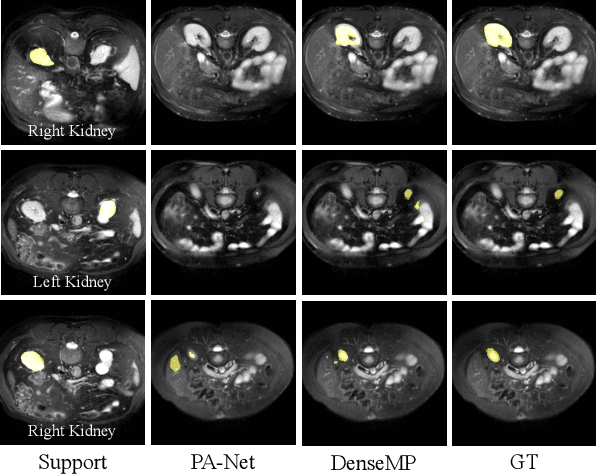


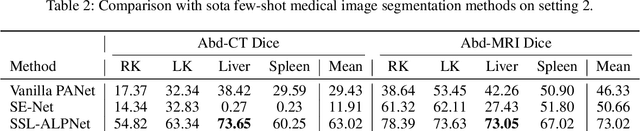
Few-shot medical image semantic segmentation is of paramount importance in the domain of medical image analysis. However, existing methodologies grapple with the challenge of data scarcity during the training phase, leading to over-fitting. To mitigate this issue, we introduce a novel Unsupervised Dense Few-shot Medical Image Segmentation Model Training Pipeline (DenseMP) that capitalizes on unsupervised dense pre-training. DenseMP is composed of two distinct stages: (1) segmentation-aware dense contrastive pre-training, and (2) few-shot-aware superpixel guided dense pre-training. These stages collaboratively yield a pre-trained initial model specifically designed for few-shot medical image segmentation, which can subsequently be fine-tuned on the target dataset. Our proposed pipeline significantly enhances the performance of the widely recognized few-shot segmentation model, PA-Net, achieving state-of-the-art results on the Abd-CT and Abd-MRI datasets. Code will be released after acceptance.
Compact & Capable: Harnessing Graph Neural Networks and Edge Convolution for Medical Image Classification
Jul 24, 2023
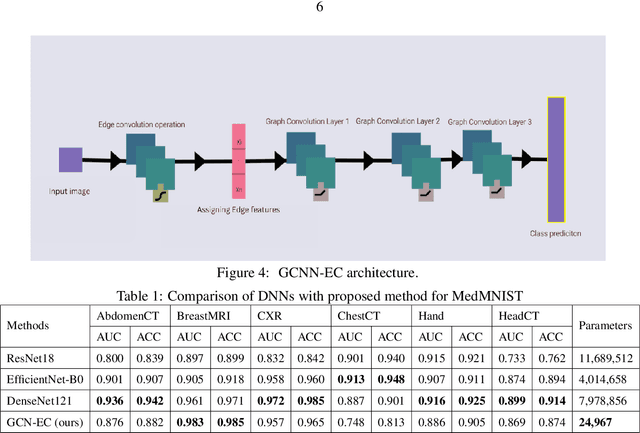
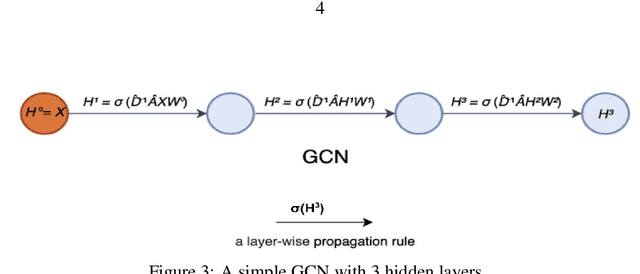
Graph-based neural network models are gaining traction in the field of representation learning due to their ability to uncover latent topological relationships between entities that are otherwise challenging to identify. These models have been employed across a diverse range of domains, encompassing drug discovery, protein interactions, semantic segmentation, and fluid dynamics research. In this study, we investigate the potential of Graph Neural Networks (GNNs) for medical image classification. We introduce a novel model that combines GNNs and edge convolution, leveraging the interconnectedness of RGB channel feature values to strongly represent connections between crucial graph nodes. Our proposed model not only performs on par with state-of-the-art Deep Neural Networks (DNNs) but does so with 1000 times fewer parameters, resulting in reduced training time and data requirements. We compare our Graph Convolutional Neural Network (GCNN) to pre-trained DNNs for classifying MedMNIST dataset classes, revealing promising prospects for GNNs in medical image analysis. Our results also encourage further exploration of advanced graph-based models such as Graph Attention Networks (GAT) and Graph Auto-Encoders in the medical imaging domain. The proposed model yields more reliable, interpretable, and accurate outcomes for tasks like semantic segmentation and image classification compared to simpler GCNNs
An Improved Upper Bound on the Rate-Distortion Function of Images
Sep 05, 2023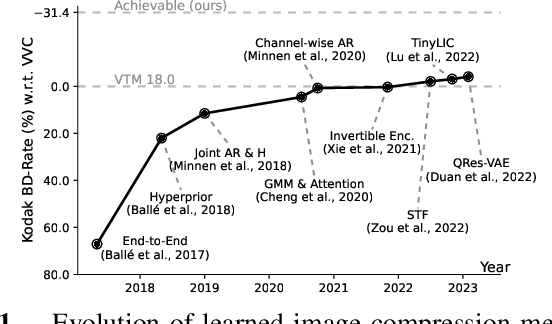

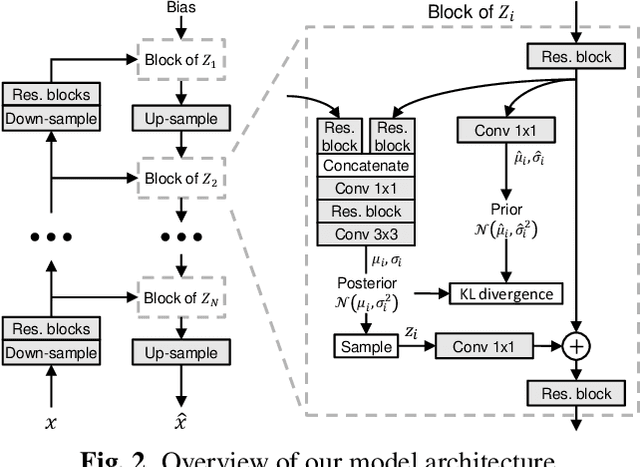
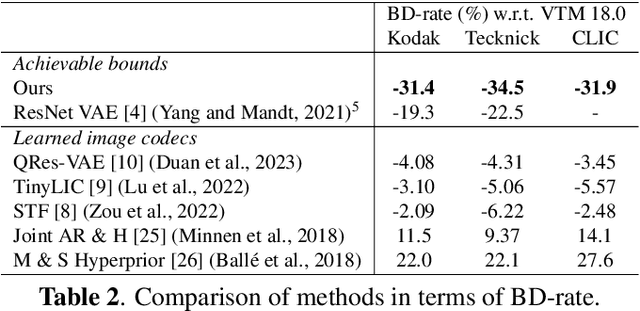
Recent work has shown that Variational Autoencoders (VAEs) can be used to upper-bound the information rate-distortion (R-D) function of images, i.e., the fundamental limit of lossy image compression. In this paper, we report an improved upper bound on the R-D function of images implemented by (1) introducing a new VAE model architecture, (2) applying variable-rate compression techniques, and (3) proposing a novel \ourfunction{} to stabilize training. We demonstrate that at least 30\% BD-rate reduction w.r.t. the intra prediction mode in VVC codec is achievable, suggesting that there is still great potential for improving lossy image compression. Code is made publicly available at https://github.com/duanzhiihao/lossy-vae.