 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIN: Fast Inference Network for Map Segmentation
Oct 01, 2025



Multi-sensor fusion in autonomous vehicles is becoming more common to offer a more robust alternative for several perception tasks. This need arises from the unique contribution of each sensor in collecting data: camera-radar fusion offers a cost-effective solution by combining rich semantic information from cameras with accurate distance measurements from radar, without incurring excessive financial costs or overwhelming data processing requirements. Map segmentation is a critical task for enabling effective vehicle behaviour in its environment, yet it continues to face significant challenges in achieving high accuracy and meeting real-time performance requirements. Therefore, this work presents a novel and efficient map segmentation architecture, using cameras and radars, in the \acrfull{bev} space. Our model introduces a real-time map segmentation architecture considering aspects such as high accuracy, per-class balancing, and inference time. To accomplish this, we use an advanced loss set together with a new lightweight head to improve the perception results. Our results show that, with these modifications, our approach achieves results comparable to large models, reaching 53.5 mIoU, while also setting a new benchmark for inference time, improving it by 260\% over the strongest baseline models.
PAN: Pillars-Attention-Based Network for 3D Object Detection
Sep 19, 2025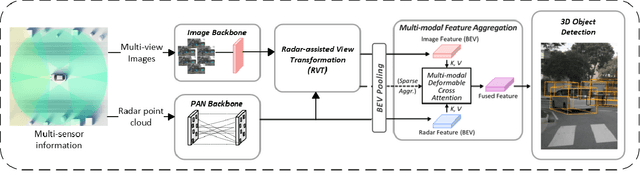
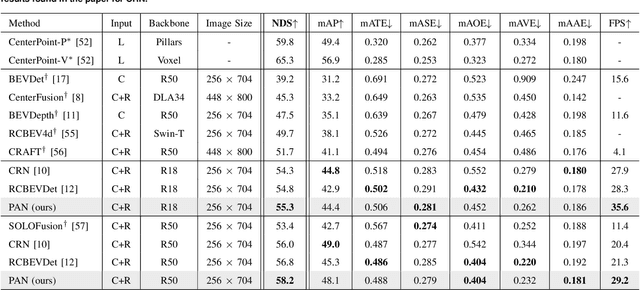
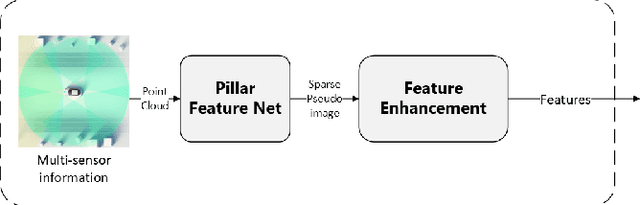
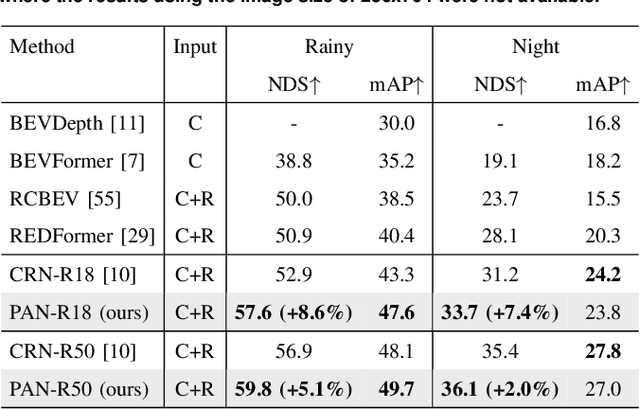
Camera-radar fusion offers a robust and low-cost alternative to Camera-lidar fusion for the 3D object detection task in real-time under adverse weather and lighting conditions. However, currently, in the literature, it is possible to find few works focusing on this modality and, most importantly, developing new architectures to explore the advantages of the radar point cloud, such as accurate distance estimation and speed information. Therefore, this work presents a novel and efficient 3D object detection algorithm using cameras and radars in the bird's-eye-view (BEV). Our algorithm exploits the advantages of radar before fusing the features into a detection head. A new backbone is introduced, which maps the radar pillar features into an embedded dimension. A self-attention mechanism allows the backbone to model the dependencies between the radar points. We are using a simplified convolutional layer to replace the FPN-based convolutional layers used in the PointPillars-based architectures with the main goal of reducing inference time. Our results show that with this modification, our approach achieves the new state-of-the-art in the 3D object detection problem, reaching 58.2 of the NDS metric for the use of ResNet-50, while also setting a new benchmark for inference time on the nuScenes dataset for the same category.
Revisiting Birds Eye View Perception Models with Frozen Foundation Models: DINOv2 and Metric3Dv2
Jan 14, 2025



Birds Eye View perception models require extensive data to perform and generalize effectively. While traditional datasets often provide abundant driving scenes from diverse locations, this is not always the case. It is crucial to maximize the utility of the available training data. With the advent of large foundation models such as DINOv2 and Metric3Dv2, a pertinent question arises: can these models be integrated into existing model architectures to not only reduce the required training data but surpass the performance of current models? We choose two model architectures in the vehicle segmentation domain to alter: Lift-Splat-Shoot, and Simple-BEV. For Lift-Splat-Shoot, we explore the implementation of frozen DINOv2 for feature extraction and Metric3Dv2 for depth estimation, where we greatly exceed the baseline results by 7.4 IoU while utilizing only half the training data and iterations. Furthermore, we introduce an innovative application of Metric3Dv2's depth information as a PseudoLiDAR point cloud incorporated into the Simple-BEV architecture, replacing traditional LiDAR. This integration results in a +3 IoU improvement compared to the Camera-only model.
Minimizing Occlusion Effect on Multi-View Camera Perception in BEV with Multi-Sensor Fusion
Jan 10, 2025Autonomous driving technology is rapidly evolving, offering the potential for safer and more efficient transportation. However, the performance of these systems can be significantly compromised by the occlusion on sensors due to environmental factors like dirt, dust, rain, and fog. These occlusions severely affect vision-based tasks such as object detection, vehicle segmentation, and lane recognition. In this paper, we investigate the impact of various kinds of occlusions on camera sensor by projecting their effects from multi-view camera images of the nuScenes dataset into the Bird's-Eye View (BEV) domain. This approach allows us to analyze how occlusions spatially distribute and influence vehicle segmentation accuracy within the BEV domain. Despite significant advances in sensor technology and multi-sensor fusion, a gap remains in the existing literature regarding the specific effects of camera occlusions on BEV-based perception systems. To address this gap, we use a multi-sensor fusion technique that integrates LiDAR and radar sensor data to mitigate the performance degradation caused by occluded cameras. Our findings demonstrate that this approach significantly enhances the accuracy and robustness of vehicle segmentation tasks, leading to more reliable autonomous driving systems.
Image Segmentation: Inducing graph-based learning
Jan 07, 2025This study explores the potential of graph neural networks (GNNs) to enhance semantic segmentation across diverse image modalities. We evaluate the effectiveness of a novel GNN-based U-Net architecture on three distinct datasets: PascalVOC, a standard benchmark for natural image segmentation, WoodScape, a challenging dataset of fisheye images commonly used in autonomous driving, introducing significant geometric distortions; and ISIC2016, a dataset of dermoscopic images for skin lesion segmentation. We compare our proposed UNet-GNN model against established convolutional neural networks (CNNs) based segmentation models, including U-Net and U-Net++, as well as the transformer-based SwinUNet. Unlike these methods, which primarily rely on local convolutional operations or global self-attention, GNNs explicitly model relationships between image regions by constructing and operating on a graph representation of the image features. This approach allows the model to capture long-range dependencies and complex spatial relationships, which we hypothesize will be particularly beneficial for handling geometric distortions present in fisheye imagery and capturing intricate boundaries in medical images. Our analysis demonstrates the versatility of GNNs in addressing diverse segmentation challenges and highlights their potential to improve segmentation accuracy in various applications, including autonomous driving and medical image analysis.
Time Series Anomaly Detection with CNN for Environmental Sensors in Healthcare-IoT
Jul 30, 2024

This research develops a new method to detect anomalies in time series data using Convolutional Neural Networks (CNNs) in healthcare-IoT. The proposed method creates a Distributed Denial of Service (DDoS) attack using an IoT network simulator, Cooja, which emulates environmental sensors such as temperature and humidity. CNNs detect anomalies in time series data, resulting in a 92\% accuracy in identifying possible attacks.
Velocity Driven Vision: Asynchronous Sensor Fusion Birds Eye View Models for Autonomous Vehicles
Jul 24, 2024



Fusing different sensor modalities can be a difficult task, particularly if they are asynchronous. Asynchronisation may arise due to long processing times or improper synchronisation during calibration, and there must exist a way to still utilise this previous information for the purpose of safe driving, and object detection in ego vehicle/ multi-agent trajectory prediction. Difficulties arise in the fact that the sensor modalities have captured information at different times and also at different positions in space. Therefore, they are not spatially nor temporally aligned. This paper will investigate the challenge of radar and LiDAR sensors being asynchronous relative to the camera sensors, for various time latencies. The spatial alignment will be resolved before lifting into BEV space via the transformation of the radar/LiDAR point clouds into the new ego frame coordinate system. Only after this can we concatenate the radar/LiDAR point cloud and lifted camera features. Temporal alignment will be remedied for radar data only, we will implement a novel method of inferring the future radar point positions using the velocity information. Our approach to resolving the issue of sensor asynchrony yields promising results. We demonstrate velocity information can drastically improve IoU for asynchronous datasets, as for a time latency of 360 milliseconds (ms), IoU improves from 49.54 to 53.63. Additionally, for a time latency of 550ms, the camera+radar (C+R) model outperforms the camera+LiDAR (C+L) model by 0.18 IoU. This is an advancement in utilising the often-neglected radar sensor modality, which is less favoured than LiDAR for autonomous driving purposes.
Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
Jul 23, 2024



This study investigates the effectiveness of modern Deformable Convolutional Neural Networks (DCNNs) for semantic segmentation tasks, particularly in autonomous driving scenarios with fisheye images. These images, providing a wide field of view, pose unique challenges for extracting spatial and geometric information due to dynamic changes in object attributes. Our experiments focus on segmenting the WoodScape fisheye image dataset into ten distinct classes, assessing the Deformable Networks' ability to capture intricate spatial relationships and improve segmentation accuracy. Additionally, we explore different loss functions to address class imbalance issues and compare the performance of conventional CNN architectures with Deformable Convolution-based CNNs, including Vanilla U-Net and Residual U-Net architectures. The significant improvement in mIoU score resulting from integrating Deformable CNNs demonstrates their effectiveness in handling the geometric distortions present in fisheye imagery, exceeding the performance of traditional CNN architectures. This underscores the significant role of Deformable convolution in enhancing semantic segmentation performance for fisheye imagery.
SS-SFR: Synthetic Scenes Spatial Frequency Response on Virtual KITTI and Degraded Automotive Simulations for Object Detection
Jul 22, 2024



Automotive simulation can potentially compensate for a lack of training data in computer vision applications. However, there has been little to no image quality evaluation of automotive simulation and the impact of optical degradations on simulation is little explored. In this work, we investigate Virtual KITTI and the impact of applying variations of Gaussian blur on image sharpness. Furthermore, we consider object detection, a common computer vision application on three different state-of-the-art models, thus allowing us to characterize the relationship between object detection and sharpness. It was found that while image sharpness (MTF50) degrades from an average of 0.245cy/px to approximately 0.119cy/px; object detection performance stays largely robust within 0.58\%(Faster RCNN), 1.45\%(YOLOF) and 1.93\%(DETR) across all respective held-out test sets.
* 8 pages, 2 figures, 2 tables
Subgraph Clustering and Atom Learning for Improved Image Classification
Jul 20, 2024In this study, we present the Graph Sub-Graph Network (GSN), a novel hybrid image classification model merging the strengths of Convolutional Neural Networks (CNNs) for feature extraction and Graph Neural Networks (GNNs) for structural modeling. GSN employs k-means clustering to group graph nodes into clusters, facilitating the creation of subgraphs. These subgraphs are then utilized to learn representative `atoms` for dictionary learning, enabling the identification of sparse, class-distinguishable features. This integrated approach is particularly relevant in domains like medical imaging, where discerning subtle feature differences is crucial for accurate classification. To evaluate the performance of our proposed GSN, we conducted experiments on benchmark datasets, including PascalVOC and HAM10000. Our results demonstrate the efficacy of our model in optimizing dictionary configurations across varied classes, which contributes to its effectiveness in medical classification tasks. This performance enhancement is primarily attributed to the integration of CNNs, GNNs, and graph learning techniques, which collectively improve the handling of datasets with limited labeled examples. Specifically, our experiments show that the model achieves a higher accuracy on benchmark datasets such as Pascal VOC and HAM10000 compared to conventional CNN approaches.