 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
Sep 15, 2017
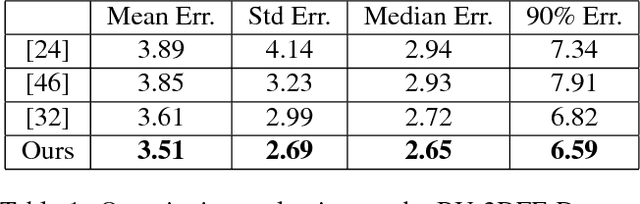

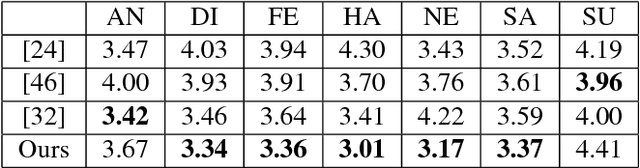
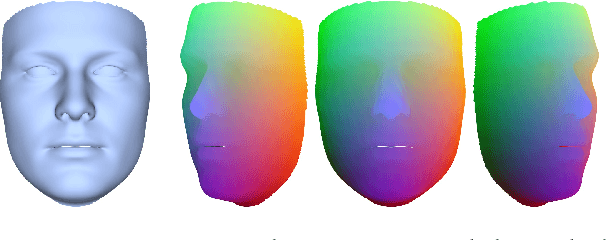
It has been recently shown that neural networks can recover the geometric structure of a face from a single given image. A common denominator of most existing face geometry reconstruction methods is the restriction of the solution space to some low-dimensional subspace. While such a model significantly simplifies the reconstruction problem, it is inherently limited in its expressiveness. As an alternative, we propose an Image-to-Image translation network that jointly maps the input image to a depth image and a facial correspondence map. This explicit pixel-based mapping can then be utilized to provide high quality reconstructions of diverse faces under extreme expressions, using a purely geometric refinement process. In the spirit of recent approaches, the network is trained only with synthetic data, and is then evaluated on in-the-wild facial images. Both qualitative and quantitative analyses demonstrate the accuracy and the robustness of our approach.
CDPMSR: Conditional Diffusion Probabilistic Models for Single Image Super-Resolution
Feb 14, 2023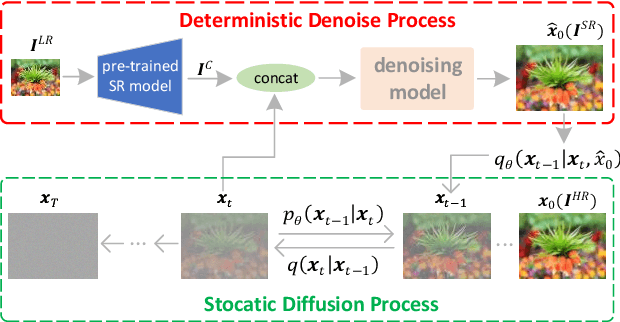
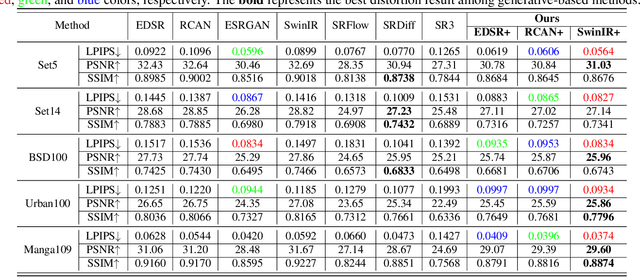

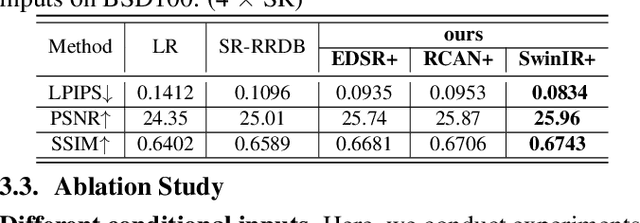
Diffusion probabilistic models (DPM) have been widely adopted in image-to-image translation to generate high-quality images. Prior attempts at applying the DPM to image super-resolution (SR) have shown that iteratively refining a pure Gaussian noise with a conditional image using a U-Net trained on denoising at various-level noises can help obtain a satisfied high-resolution image for the low-resolution one. To further improve the performance and simplify current DPM-based super-resolution methods, we propose a simple but non-trivial DPM-based super-resolution post-process framework,i.e., cDPMSR. After applying a pre-trained SR model on the to-be-test LR image to provide the conditional input, we adapt the standard DPM to conduct conditional image generation and perform super-resolution through a deterministic iterative denoising process. Our method surpasses prior attempts on both qualitative and quantitative results and can generate more photo-realistic counterparts for the low-resolution images with various benchmark datasets including Set5, Set14, Urban100, BSD100, and Manga109. Code will be published after accepted.
Image-to-Image Translation with Conditional Adversarial Networks
Nov 22, 2017
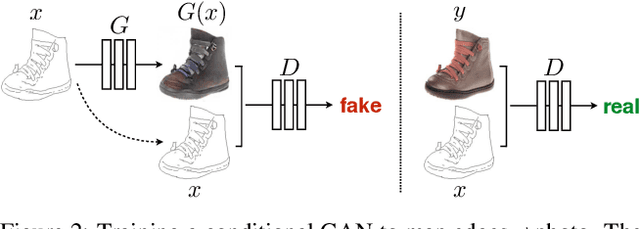

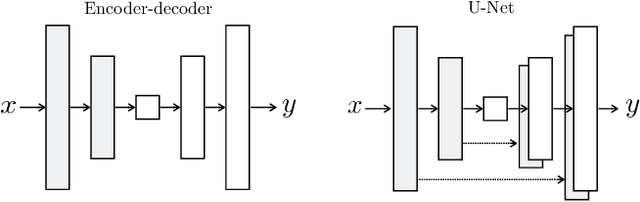
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
* Website: https://phillipi.github.io/pix2pix/
Probabilistic Plant Modeling via Multi-View Image-to-Image Translation
Apr 25, 2018
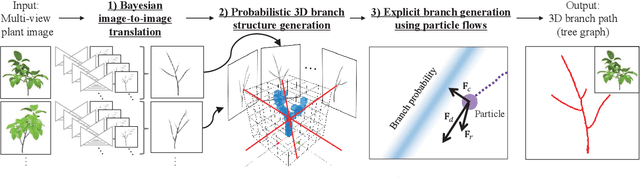
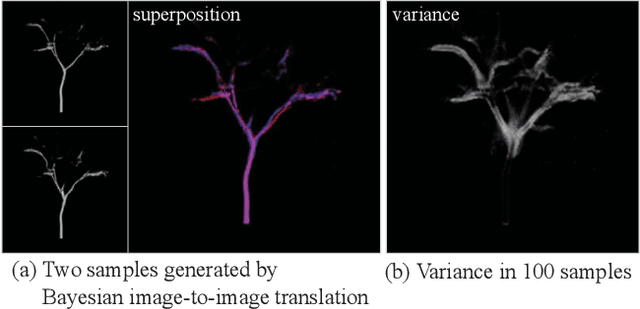
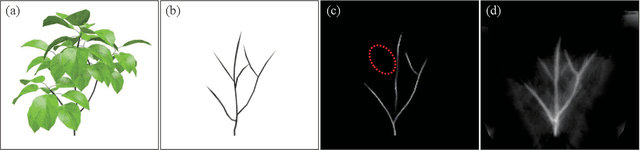
This paper describes a method for inferring three-dimensional (3D) plant branch structures that are hidden under leaves from multi-view observations. Unlike previous geometric approaches that heavily rely on the visibility of the branches or use parametric branching models, our method makes statistical inferences of branch structures in a probabilistic framework. By inferring the probability of branch existence using a Bayesian extension of image-to-image translation applied to each of multi-view images, our method generates a probabilistic plant 3D model, which represents the 3D branching pattern that cannot be directly observed. Experiments demonstrate the usefulness of the proposed approach in generating convincing branch structures in comparison to prior approaches.
TransferI2I: Transfer Learning for Image-to-Image Translation from Small Datasets
May 14, 2021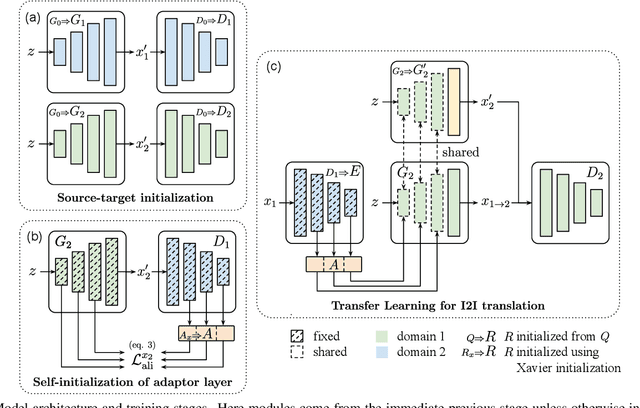
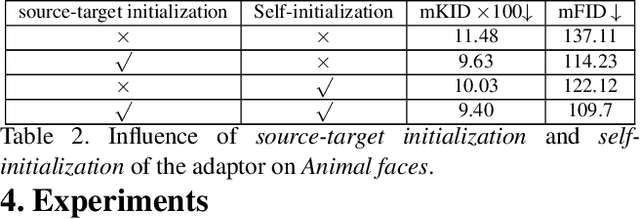
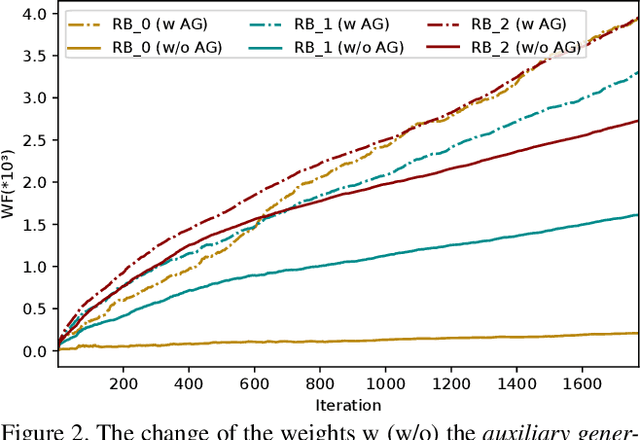
Image-to-image (I2I) translation has matured in recent years and is able to generate high-quality realistic images. However, despite current success, it still faces important challenges when applied to small domains. Existing methods use transfer learning for I2I translation, but they still require the learning of millions of parameters from scratch. This drawback severely limits its application on small domains. In this paper, we propose a new transfer learning for I2I translation (TransferI2I). We decouple our learning process into the image generation step and the I2I translation step. In the first step we propose two novel techniques: source-target initialization and self-initialization of the adaptor layer. The former finetunes the pretrained generative model (e.g., StyleGAN) on source and target data. The latter allows to initialize all non-pretrained network parameters without the need of any data. These techniques provide a better initialization for the I2I translation step. In addition, we introduce an auxiliary GAN that further facilitates the training of deep I2I systems even from small datasets. In extensive experiments on three datasets, (Animal faces, Birds, and Foods), we show that we outperform existing methods and that mFID improves on several datasets with over 25 points.
Diverse Image-to-Image Translation via Disentangled Representations
Aug 02, 2018
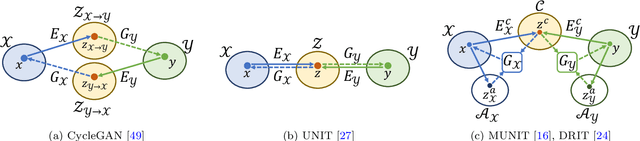
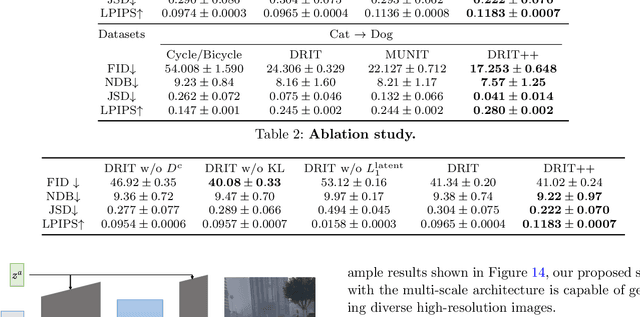
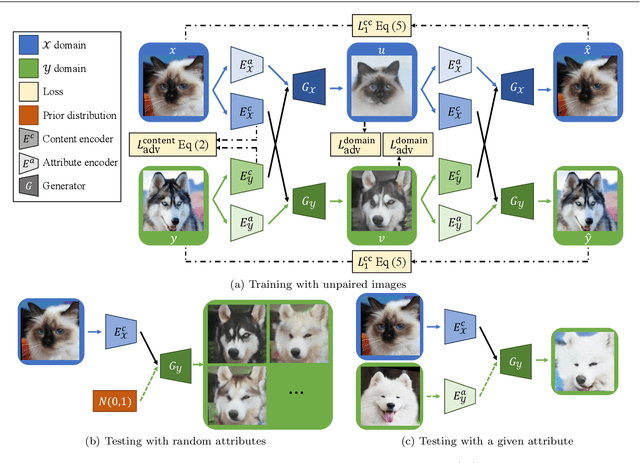
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for many applications: 1) the lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for producing diverse outputs without paired training images. To achieve diversity, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and the attribute vectors sampled from the attribute space to produce diverse outputs at test time. To handle unpaired training data, we introduce a novel cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative comparisons, we measure realism with user study and diversity with a perceptual distance metric. We apply the proposed model to domain adaptation and show competitive performance when compared to the state-of-the-art on the MNIST-M and the LineMod datasets.
Keypoint-Guided Optimal Transport
Mar 23, 2023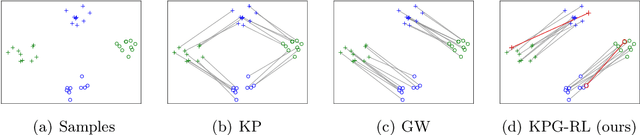
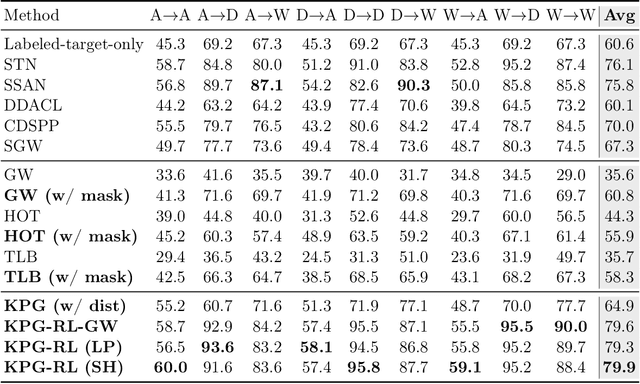
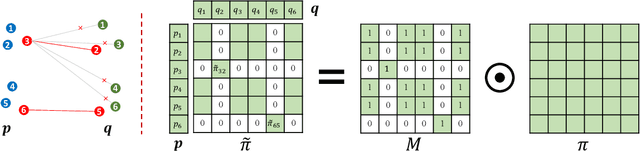

Existing Optimal Transport (OT) methods mainly derive the optimal transport plan/matching under the criterion of transport cost/distance minimization, which may cause incorrect matching in some cases. In many applications, annotating a few matched keypoints across domains is reasonable or even effortless in annotation burden. It is valuable to investigate how to leverage the annotated keypoints to guide the correct matching in OT. In this paper, we propose a novel KeyPoint-Guided model by ReLation preservation (KPG-RL) that searches for the optimal matching (i.e., transport plan) guided by the keypoints in OT. To impose the keypoints in OT, first, we propose a mask-based constraint of the transport plan that preserves the matching of keypoint pairs. Second, we propose to preserve the relation of each data point to the keypoints to guide the matching. The proposed KPG-RL model can be solved by Sinkhorn's algorithm and is applicable even when distributions are supported in different spaces. We further utilize the relation preservation constraint in the Kantorovich Problem and Gromov-Wasserstein model to impose the guidance of keypoints in them. Meanwhile, the proposed KPG-RL model is extended to the partial OT setting. Moreover, we deduce the dual formulation of the KPG-RL model, which is solved using deep learning techniques. Based on the learned transport plan from dual KPG-RL, we propose a novel manifold barycentric projection to transport source data to the target domain. As applications, we apply the proposed KPG-RL model to the heterogeneous domain adaptation and image-to-image translation. Experiments verified the effectiveness of the proposed approach.
Unpaired Image Translation via Vector Symbolic Architectures
Sep 06, 2022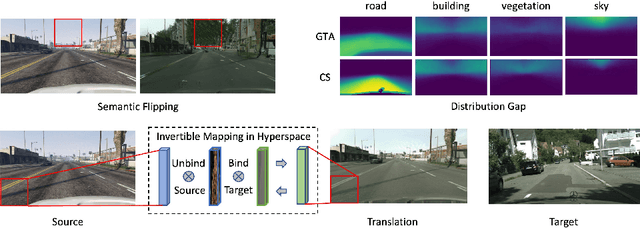
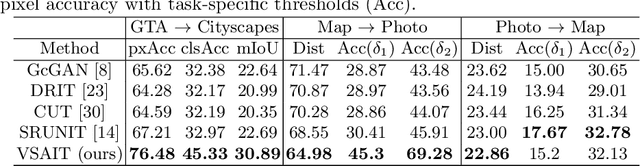


Image-to-image translation has played an important role in enabling synthetic data for computer vision. However, if the source and target domains have a large semantic mismatch, existing techniques often suffer from source content corruption aka semantic flipping. To address this problem, we propose a new paradigm for image-to-image translation using Vector Symbolic Architectures (VSA), a theoretical framework which defines algebraic operations in a high-dimensional vector (hypervector) space. We introduce VSA-based constraints on adversarial learning for source-to-target translations by learning a hypervector mapping that inverts the translation to ensure consistency with source content. We show both qualitatively and quantitatively that our method improves over other state-of-the-art techniques.
Exploring Explicit Domain Supervision for Latent Space Disentanglement in Unpaired Image-to-Image Translation
Mar 26, 2019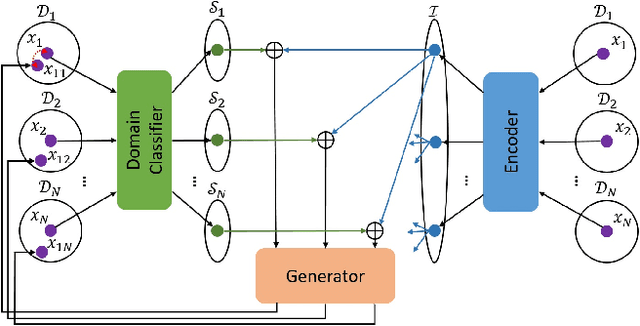
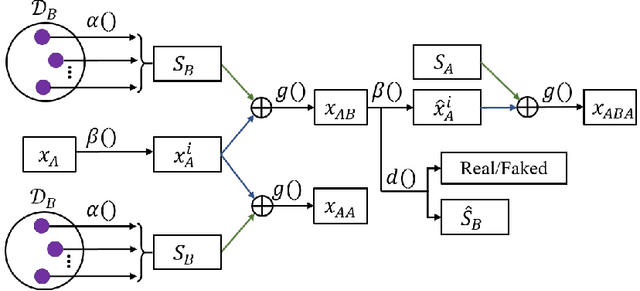

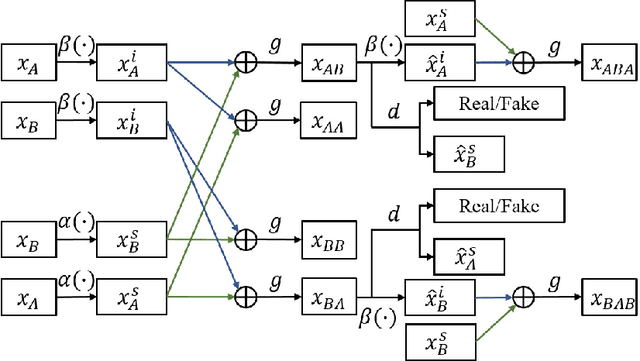
Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs). However, existing approaches are mostly designed in an unsupervised manner while little attention has been paid to domain information within unpaired data. In this paper, we treat domain information as explicit supervision and design an unpaired image-to-image translation framework, Domain-supervised GAN (DosGAN), which takes the first step towards the exploration of explicit domain supervision. In contrast to representing domain characteristics using different generators in CycleGAN or multiple domain codes in StarGAN, we pre-train a classification network to explicitly classify the domain of an image. After pre-training, this network is used to extract the domain-specific features of each image by using the output of its second-to-last layer. Such features, together with the domain-independent features extracted by another encoder (shared across different domains), are used to generate an image in the target domain. Extensive experiments on multiple hair color translation, multiple identity translation, multiple season translation and conditional edges-to-shoes/handbags demonstrate the effectiveness of our method. In addition, we can transfer the domain-specific feature extractor obtained on the Facescrub dataset with domain supervision information to unseen domains, such as faces in the CelebA dataset. We also succeed in achieving conditional translation with any two images in CelebA, while previous models like StarGAN cannot handle this task.