 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model for All: Multi-Objective Controllable Language Models
Apr 06, 2026Aligning large language models (LLMs) with human preferences is critical for enhancing LLMs' safety, helpfulness, humor, faithfulness, etc. Current reinforcement learning from human feedback (RLHF) mainly focuses on a fixed reward learned from average human ratings, which may weaken the adaptability and controllability of varying preferences. However, creating personalized LLMs requires aligning LLMs with individual human preferences, which is non-trivial due to the scarce data per user and the diversity of user preferences in multi-objective trade-offs, varying from emphasizing empathy in certain contexts to demanding efficiency and precision in others. Can we train one LLM to produce personalized outputs across different user preferences on the Pareto front? In this paper, we introduce Multi-Objective Control (MOC), which trains a single LLM to directly generate responses in the preference-defined regions of the Pareto front. Our approach introduces multi-objective optimization (MOO) principles into RLHF to train an LLM as a preference-conditioned policy network. We improve the computational efficiency of MOC by applying MOO at the policy level, enabling us to fine-tune a 7B-parameter model on a single A6000 GPU. Extensive experiments demonstrate the advantages of MOC over baselines in three aspects: (i) controllability of LLM outputs w.r.t. user preferences on the trade-off among multiple rewards; (ii) quality and diversity of LLM outputs, measured by the hyper-volume of multiple solutions achieved; and (iii) generalization to unseen preferences. These results highlight MOC's potential for real-world applications requiring scalable and customizable LLMs.
Recurrent Structural Policy Gradient for Partially Observable Mean Field Games
Feb 23, 2026Mean Field Games (MFGs) provide a principled framework for modeling interactions in large population models: at scale, population dynamics become deterministic, with uncertainty entering only through aggregate shocks, or common noise. However, algorithmic progress has been limited since model-free methods are too high variance and exact methods scale poorly. Recent Hybrid Structural Methods (HSMs) use Monte Carlo rollouts for the common noise in combination with exact estimation of the expected return, conditioned on those samples. However, HSMs have not been scaled to Partially Observable settings. We propose Recurrent Structural Policy Gradient (RSPG), the first history-aware HSM for settings involving public information. We also introduce MFAX, our JAX-based framework for MFGs. By leveraging known transition dynamics, RSPG achieves state-of-the-art performance as well as an order-of-magnitude faster convergence and solves, for the first time, a macroeconomics MFG with heterogeneous agents, common noise and history-aware policies. MFAX is publicly available at: https://github.com/CWibault/mfax.
Deep Learning for Art Market Valuation
Dec 28, 2025We study how deep learning can improve valuation in the art market by incorporating the visual content of artworks into predictive models. Using a large repeated-sales dataset from major auction houses, we benchmark classical hedonic regressions and tree-based methods against modern deep architectures, including multi-modal models that fuse tabular and image data. We find that while artist identity and prior transaction history dominate overall predictive power, visual embeddings provide a distinct and economically meaningful contribution for fresh-to-market works where historical anchors are absent. Interpretability analyses using Grad-CAM and embedding visualizations show that models attend to compositional and stylistic cues. Our findings demonstrate that multi-modal deep learning delivers significant value precisely when valuation is hardest, namely first-time sales, and thus offers new insights for both academic research and practice in art market valuation.
Enabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Structural Reinforcement Learning for Heterogeneous Agent Macroeconomics
Dec 21, 2025We present a new approach to formulating and solving heterogeneous agent models with aggregate risk. We replace the cross-sectional distribution with low-dimensional prices as state variables and let agents learn equilibrium price dynamics directly from simulated paths. To do so, we introduce a structural reinforcement learning (SRL) method which treats prices via simulation while exploiting agents' structural knowledge of their own individual dynamics. Our SRL method yields a general and highly efficient global solution method for heterogeneous agent models that sidesteps the Master equation and handles problems traditional methods struggle with, in particular nontrivial market-clearing conditions. We illustrate the approach in the Krusell-Smith model, the Huggett model with aggregate shocks, and a HANK model with a forward-looking Phillips curve, all of which we solve globally within minutes.
Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement Learning
Jun 12, 2025Unsupervised reinforcement learning (URL) aims to learn general skills for unseen downstream tasks. Mutual Information Skill Learning (MISL) addresses URL by maximizing the mutual information between states and skills but lacks sufficient theoretical analysis, e.g., how well its learned skills can initialize a downstream task's policy. Our new theoretical analysis in this paper shows that the diversity and separability of learned skills are fundamentally critical to downstream task adaptation but MISL does not necessarily guarantee these properties. To complement MISL, we propose a novel disentanglement metric LSEPIN. Moreover, we build an information-geometric connection between LSEPIN and downstream task adaptation cost. For better geometric properties, we investigate a new strategy that replaces the KL divergence in information geometry with Wasserstein distance. We extend the geometric analysis to it, which leads to a novel skill-learning objective WSEP. It is theoretically justified to be helpful to downstream task adaptation and it is capable of discovering more initial policies for downstream tasks than MISL. We finally propose another Wasserstein distance-based algorithm PWSEP that can theoretically discover all optimal initial policies.
* Spotlight paper at ICLR 2024. This version includes acknowledgments omitted from the ICLR version and indicates the corresponding authors primarily responsible for the work
Reliable Heading Tracking for Pedestrian Road Crossing Prediction Using Commodity Devices
Oct 08, 2024



Pedestrian heading tracking enables applications in pedestrian navigation, traffic safety, and accessibility. Previous works, using inertial sensor fusion or machine learning, are limited in that they assume the phone is fixed in specific orientations, hindering their generalizability. We propose a new heading tracking algorithm, the Orientation-Heading Alignment (OHA), which leverages a key insight: people tend to carry smartphones in certain ways due to habits, such as swinging them while walking. For each smartphone attitude during this motion, OHA maps the smartphone orientation to the pedestrian heading and learns such mappings efficiently from coarse headings and smartphone orientations. To anchor our algorithm in a practical scenario, we apply OHA to a challenging task: predicting when pedestrians are about to cross the road to improve road user safety. In particular, using 755 hours of walking data collected since 2020 from 60 individuals, we develop a lightweight model that operates in real-time on commodity devices to predict road crossings. Our evaluation shows that OHA achieves 3.4 times smaller heading errors across nine scenarios than existing methods. Furthermore, OHA enables the early and accurate detection of pedestrian crossing behavior, issuing crossing alerts 0.35 seconds, on average, before pedestrians enter the road range.
Prototypical Partial Optimal Transport for Universal Domain Adaptation
Aug 02, 2024Universal domain adaptation (UniDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain without requiring the same label sets of both domains. The existence of domain and category shift makes the task challenging and requires us to distinguish "known" samples (i.e., samples whose labels exist in both domains) and "unknown" samples (i.e., samples whose labels exist in only one domain) in both domains before reducing the domain gap. In this paper, we consider the problem from the point of view of distribution matching which we only need to align two distributions partially. A novel approach, dubbed mini-batch Prototypical Partial Optimal Transport (m-PPOT), is proposed to conduct partial distribution alignment for UniDA. In training phase, besides minimizing m-PPOT, we also leverage the transport plan of m-PPOT to reweight source prototypes and target samples, and design reweighted entropy loss and reweighted cross-entropy loss to distinguish "known" and "unknown" samples. Experiments on four benchmarks show that our method outperforms the previous state-of-the-art UniDA methods.
Keypoint-Guided Optimal Transport
Mar 23, 2023Existing Optimal Transport (OT) methods mainly derive the optimal transport plan/matching under the criterion of transport cost/distance minimization, which may cause incorrect matching in some cases. In many applications, annotating a few matched keypoints across domains is reasonable or even effortless in annotation burden. It is valuable to investigate how to leverage the annotated keypoints to guide the correct matching in OT. In this paper, we propose a novel KeyPoint-Guided model by ReLation preservation (KPG-RL) that searches for the optimal matching (i.e., transport plan) guided by the keypoints in OT. To impose the keypoints in OT, first, we propose a mask-based constraint of the transport plan that preserves the matching of keypoint pairs. Second, we propose to preserve the relation of each data point to the keypoints to guide the matching. The proposed KPG-RL model can be solved by Sinkhorn's algorithm and is applicable even when distributions are supported in different spaces. We further utilize the relation preservation constraint in the Kantorovich Problem and Gromov-Wasserstein model to impose the guidance of keypoints in them. Meanwhile, the proposed KPG-RL model is extended to the partial OT setting. Moreover, we deduce the dual formulation of the KPG-RL model, which is solved using deep learning techniques. Based on the learned transport plan from dual KPG-RL, we propose a novel manifold barycentric projection to transport source data to the target domain. As applications, we apply the proposed KPG-RL model to the heterogeneous domain adaptation and image-to-image translation. Experiments verified the effectiveness of the proposed approach.
DeepHAM: A Global Solution Method for Heterogeneous Agent Models with Aggregate Shocks
Dec 29, 2021
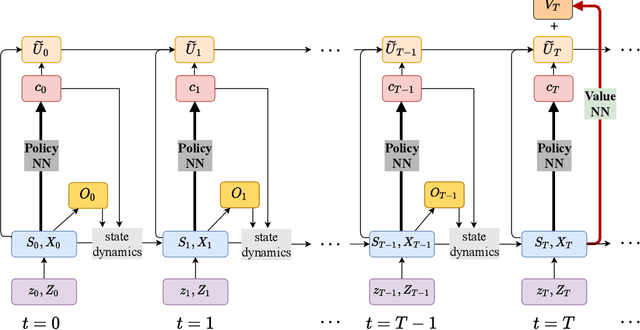
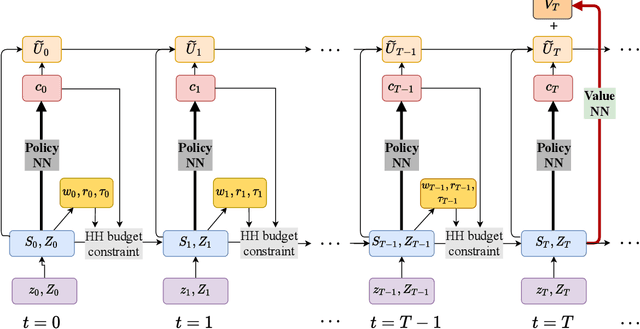

We propose an efficient, reliable, and interpretable global solution method, $\textit{Deep learning-based algorithm for Heterogeneous Agent Models, DeepHAM}$, for solving high dimensional heterogeneous agent models with aggregate shocks. The state distribution is approximately represented by a set of optimal generalized moments. Deep neural networks are used to approximate the value and policy functions, and the objective is optimized over directly simulated paths. Besides being an accurate global solver, this method has three additional features. First, it is computationally efficient for solving complex heterogeneous agent models, and it does not suffer from the curse of dimensionality. Second, it provides a general and interpretable representation of the distribution over individual states; and this is important for addressing the classical question of whether and how heterogeneity matters in macroeconomics. Third, it solves the constrained efficiency problem as easily as the competitive equilibrium, and this opens up new possibilities for studying optimal monetary and fiscal policies in heterogeneous agent models with aggregate shocks.