 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Data Asymmetry: Manifold Learning in the Finsler World
Mar 12, 2026Manifold learning is a fundamental task at the core of data analysis and visualisation. It aims to capture the simple underlying structure of complex high-dimensional data by preserving pairwise dissimilarities in low-dimensional embeddings. Traditional methods rely on symmetric Riemannian geometry, thus forcing symmetric dissimilarities and embedding spaces, e.g. Euclidean. However, this discards in practice valuable asymmetric information inherent to the non-uniformity of data samples. We suggest to harness this asymmetry by switching to Finsler geometry, an asymmetric generalisation of Riemannian geometry, and propose a Finsler manifold learning pipeline that constructs asymmetric dissimilarities and embeds in a Finsler space. This greatly broadens the applicability of existing asymmetric embedders beyond traditionally directed data to any data. We also modernise asymmetric embedders by generalising current reference methods to asymmetry, like Finsler t-SNE and Finsler Umap. On controlled synthetic and large real datasets, we show that our asymmetric pipeline reveals valuable information lost in the traditional pipeline, e.g. density hierarchies, and consistently provides superior quality embeddings than their Euclidean counterparts.
Deep Accurate Solver for the Geodesic Problem
Feb 25, 2026A common approach to compute distances on continuous surfaces is by considering a discretized polygonal mesh approximating the surface and estimating distances on the polygon. We show that exact geodesic distances restricted to the polygon are at most second-order accurate with respect to the distances on the corresponding continuous surface. By order of accuracy we refer to the convergence rate as a function of the average distance between sampled points. Next, a higher-order accurate deep learning method for computing geodesic distances on surfaces is introduced. Traditionally, one considers two main components when computing distances on surfaces: a numerical solver that locally approximates the distance function, and an efficient causal ordering scheme by which surface points are updated. Classical minimal path methods often exploit a dynamic programming principle with quasi-linear computational complexity in the number of sampled points. The quality of the distance approximation is determined by the local solver that is revisited in this paper. To improve state of the art accuracy, we consider a neural network-based local solver which implicitly approximates the structure of the continuous surface. We supply numerical evidence that the proposed learned update scheme provides better accuracy compared to the best possible polyhedral approximations and previous learning-based methods. The result is a third-order accurate solver with a bootstrapping-recipe for further improvement.
* Extended version of Deep Accurate Solver for the Geodesic Problem originally published in Scale Space and Variational Methods in Computer Vision (SSVM 2023), Lecture Notes in Computer Science, Springer. This version includes additional experiments and detailed analysis
CaricatureGS: Exaggerating 3D Gaussian Splatting Faces With Gaussian Curvature
Jan 06, 2026A photorealistic and controllable 3D caricaturization framework for faces is introduced. We start with an intrinsic Gaussian curvature-based surface exaggeration technique, which, when coupled with texture, tends to produce over-smoothed renders. To address this, we resort to 3D Gaussian Splatting (3DGS), which has recently been shown to produce realistic free-viewpoint avatars. Given a multiview sequence, we extract a FLAME mesh, solve a curvature-weighted Poisson equation, and obtain its exaggerated form. However, directly deforming the Gaussians yields poor results, necessitating the synthesis of pseudo-ground-truth caricature images by warping each frame to its exaggerated 2D representation using local affine transformations. We then devise a training scheme that alternates real and synthesized supervision, enabling a single Gaussian collection to represent both natural and exaggerated avatars. This scheme improves fidelity, supports local edits, and allows continuous control over the intensity of the caricature. In order to achieve real-time deformations, an efficient interpolation between the original and exaggerated surfaces is introduced. We further analyze and show that it has a bounded deviation from closed-form solutions. In both quantitative and qualitative evaluations, our results outperform prior work, delivering photorealistic, geometry-controlled caricature avatars.
Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising
Nov 09, 2025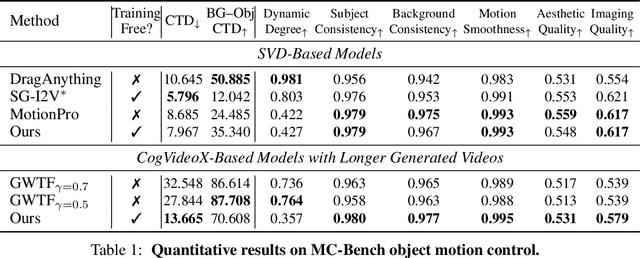
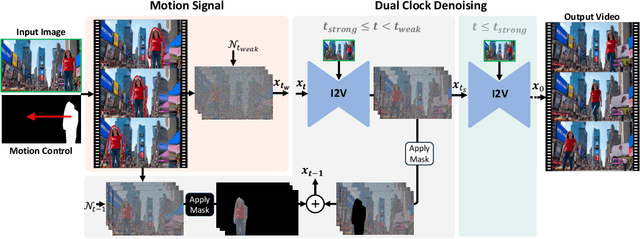
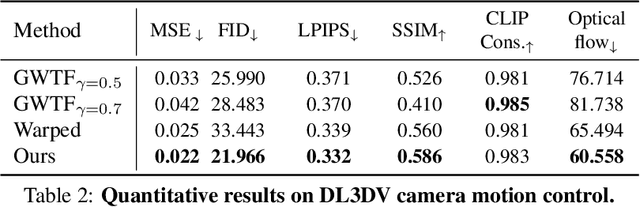
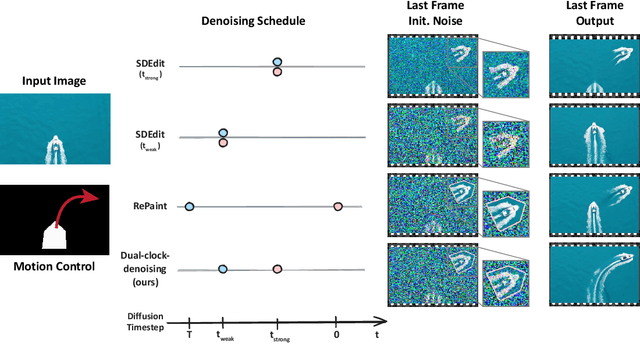
Diffusion-based video generation can create realistic videos, yet existing image- and text-based conditioning fails to offer precise motion control. Prior methods for motion-conditioned synthesis typically require model-specific fine-tuning, which is computationally expensive and restrictive. We introduce Time-to-Move (TTM), a training-free, plug-and-play framework for motion- and appearance-controlled video generation with image-to-video (I2V) diffusion models. Our key insight is to use crude reference animations obtained through user-friendly manipulations such as cut-and-drag or depth-based reprojection. Motivated by SDEdit's use of coarse layout cues for image editing, we treat the crude animations as coarse motion cues and adapt the mechanism to the video domain. We preserve appearance with image conditioning and introduce dual-clock denoising, a region-dependent strategy that enforces strong alignment in motion-specified regions while allowing flexibility elsewhere, balancing fidelity to user intent with natural dynamics. This lightweight modification of the sampling process incurs no additional training or runtime cost and is compatible with any backbone. Extensive experiments on object and camera motion benchmarks show that TTM matches or exceeds existing training-based baselines in realism and motion control. Beyond this, TTM introduces a unique capability: precise appearance control through pixel-level conditioning, exceeding the limits of text-only prompting. Visit our project page for video examples and code: https://time-to-move.github.io/.
Neural Descriptors: Self-Supervised Learning of Robust Local Surface Descriptors Using Polynomial Patches
Mar 05, 2025Classical shape descriptors such as Heat Kernel Signature (HKS), Wave Kernel Signature (WKS), and Signature of Histograms of OrienTations (SHOT), while widely used in shape analysis, exhibit sensitivity to mesh connectivity, sampling patterns, and topological noise. While differential geometry offers a promising alternative through its theory of differential invariants, which are theoretically guaranteed to be robust shape descriptors, the computation of these invariants on discrete meshes often leads to unstable numerical approximations, limiting their practical utility. We present a self-supervised learning approach for extracting geometric features from 3D surfaces. Our method combines synthetic data generation with a neural architecture designed to learn sampling-invariant features. By integrating our features into existing shape correspondence frameworks, we demonstrate improved performance on standard benchmarks including FAUST, SCAPE, TOPKIDS, and SHREC'16, showing particular robustness to topological noise and partial shapes.
CoordFlow: Coordinate Flow for Pixel-wise Neural Video Representation
Jan 01, 2025



In the field of video compression, the pursuit for better quality at lower bit rates remains a long-lasting goal. Recent developments have demonstrated the potential of Implicit Neural Representation (INR) as a promising alternative to traditional transform-based methodologies. Video INRs can be roughly divided into frame-wise and pixel-wise methods according to the structure the network outputs. While the pixel-based methods are better for upsampling and parallelization, frame-wise methods demonstrated better performance. We introduce CoordFlow, a novel pixel-wise INR for video compression. It yields state-of-the-art results compared to other pixel-wise INRs and on-par performance compared to leading frame-wise techniques. The method is based on the separation of the visual information into visually consistent layers, each represented by a dedicated network that compensates for the layer's motion. When integrated, a byproduct is an unsupervised segmentation of video sequence. Objects motion trajectories are implicitly utilized to compensate for visual-temporal redundancies. Additionally, the proposed method provides inherent video upsampling, stabilization, inpainting, and denoising capabilities.
Pathways on the Image Manifold: Image Editing via Video Generation
Nov 25, 2024



Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image. Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing. We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit. This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image's key aspects. Our approach achieves state-of-the-art results on text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation.
Wormhole Loss for Partial Shape Matching
Oct 30, 2024



When matching parts of a surface to its whole, a fundamental question arises: Which points should be included in the matching process? The issue is intensified when using isometry to measure similarity, as it requires the validation of whether distances measured between pairs of surface points should influence the matching process. The approach we propose treats surfaces as manifolds equipped with geodesic distances, and addresses the partial shape matching challenge by introducing a novel criterion to meticulously search for consistent distances between pairs of points. The new criterion explores the relation between intrinsic geodesic distances between the points, geodesic distances between the points and surface boundaries, and extrinsic distances between boundary points measured in the embedding space. It is shown to be less restrictive compared to previous measures and achieves state-of-the-art results when used as a loss function in training networks for partial shape matching.
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Apr 28, 2024



Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to the utilization of segmentation mask datasets alongside inpainting models that inpaint within these masks. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones; moreover, it maintains consistency between source and target by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. We show that the trained model surpasses existing ones both qualitatively and quantitatively, and release the large-scale dataset alongside the trained models for the community.
Surface Reconstruction from Gaussian Splatting via Novel Stereo Views
Apr 02, 2024



The Gaussian splatting for radiance field rendering method has recently emerged as an efficient approach for accurate scene representation. It optimizes the location, size, color, and shape of a cloud of 3D Gaussian elements to visually match, after projection, or splatting, a set of given images taken from various viewing directions. And yet, despite the proximity of Gaussian elements to the shape boundaries, direct surface reconstruction of objects in the scene is a challenge. We propose a novel approach for surface reconstruction from Gaussian splatting models. Rather than relying on the Gaussian elements' locations as a prior for surface reconstruction, we leverage the superior novel-view synthesis capabilities of 3DGS. To that end, we use the Gaussian splatting model to render pairs of stereo-calibrated novel views from which we extract depth profiles using a stereo matching method. We then combine the extracted RGB-D images into a geometrically consistent surface. The resulting reconstruction is more accurate and shows finer details when compared to other methods for surface reconstruction from Gaussian splatting models, while requiring significantly less compute time compared to other surface reconstruction methods. We performed extensive testing of the proposed method on in-the-wild scenes, taken by a smartphone, showcasing its superior reconstruction abilities. Additionally, we tested the proposed method on the Tanks and Temples benchmark, and it has surpassed the current leading method for surface reconstruction from Gaussian splatting models. Project page: https://gs2mesh.github.io/.