 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3d Object Reconstruction From A Single Image
3D object reconstruction from a single image is the process of estimating the 3D shape of an object from a 2D image.
Papers and Code
E-3DGS: Gaussian Splatting with Exposure and Motion Events
Oct 22, 2024



Estimating Neural Radiance Fields (NeRFs) from images captured under optimal conditions has been extensively explored in the vision community. However, robotic applications often face challenges such as motion blur, insufficient illumination, and high computational overhead, which adversely affect downstream tasks like navigation, inspection, and scene visualization. To address these challenges, we propose E-3DGS, a novel event-based approach that partitions events into motion (from camera or object movement) and exposure (from camera exposure), using the former to handle fast-motion scenes and using the latter to reconstruct grayscale images for high-quality training and optimization of event-based 3D Gaussian Splatting (3DGS). We introduce a novel integration of 3DGS with exposure events for high-quality reconstruction of explicit scene representations. Our versatile framework can operate on motion events alone for 3D reconstruction, enhance quality using exposure events, or adopt a hybrid mode that balances quality and effectiveness by optimizing with initial exposure events followed by high-speed motion events. We also introduce EME-3D, a real-world 3D dataset with exposure events, motion events, camera calibration parameters, and sparse point clouds. Our method is faster and delivers better reconstruction quality than event-based NeRF while being more cost-effective than NeRF methods that combine event and RGB data by using a single event sensor. By combining motion and exposure events, E-3DGS sets a new benchmark for event-based 3D reconstruction with robust performance in challenging conditions and lower hardware demands. The source code and dataset will be available at https://github.com/MasterHow/E-3DGS.
Hamba: Single-view 3D Hand Reconstruction with Graph-guided Bi-Scanning Mamba
Jul 12, 2024
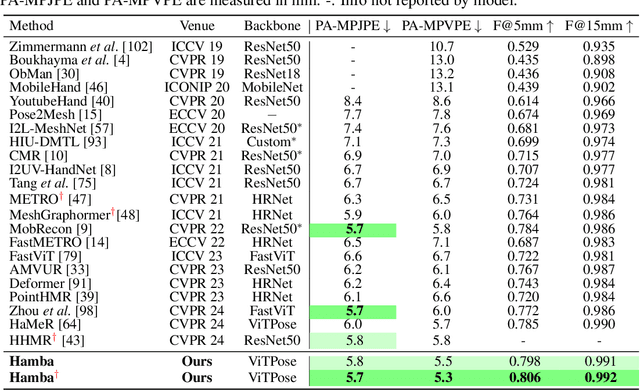
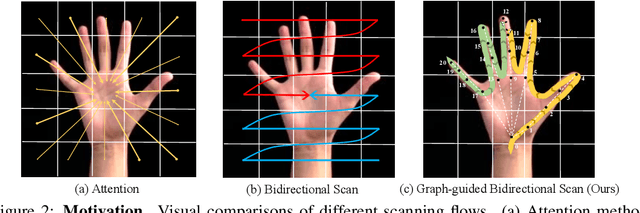
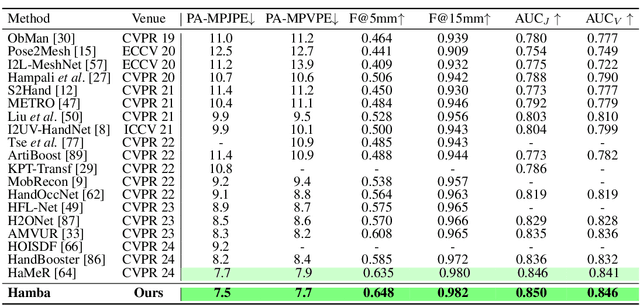
3D Hand reconstruction from a single RGB image is challenging due to the articulated motion, self-occlusion, and interaction with objects. Existing SOTA methods employ attention-based transformers to learn the 3D hand pose and shape, but they fail to achieve robust and accurate performance due to insufficient modeling of joint spatial relations. To address this problem, we propose a novel graph-guided Mamba framework, named Hamba, which bridges graph learning and state space modeling. Our core idea is to reformulate Mamba's scanning into graph-guided bidirectional scanning for 3D reconstruction using a few effective tokens. This enables us to learn the joint relations and spatial sequences for enhancing the reconstruction performance. Specifically, we design a novel Graph-guided State Space (GSS) block that learns the graph-structured relations and spatial sequences of joints and uses 88.5% fewer tokens than attention-based methods. Additionally, we integrate the state space features and the global features using a fusion module. By utilizing the GSS block and the fusion module, Hamba effectively leverages the graph-guided state space modeling features and jointly considers global and local features to improve performance. Extensive experiments on several benchmarks and in-the-wild tests demonstrate that Hamba significantly outperforms existing SOTAs, achieving the PA-MPVPE of 5.3mm and F@15mm of 0.992 on FreiHAND. Hamba is currently Rank 1 in two challenging competition leaderboards on 3D hand reconstruction. The code will be available upon acceptance. [Website](https://humansensinglab.github.io/Hamba/).
ObjectCarver: Semi-automatic segmentation, reconstruction and separation of 3D objects
Jul 26, 2024Implicit neural fields have made remarkable progress in reconstructing 3D surfaces from multiple images; however, they encounter challenges when it comes to separating individual objects within a scene. Previous work has attempted to tackle this problem by introducing a framework to train separate signed distance fields (SDFs) simultaneously for each of N objects and using a regularization term to prevent objects from overlapping. However, all of these methods require segmentation masks to be provided, which are not always readily available. We introduce our method, ObjectCarver, to tackle the problem of object separation from just click input in a single view. Given posed multi-view images and a set of user-input clicks to prompt segmentation of the individual objects, our method decomposes the scene into separate objects and reconstructs a high-quality 3D surface for each one. We introduce a loss function that prevents floaters and avoids inappropriate carving-out due to occlusion. In addition, we introduce a novel scene initialization method that significantly speeds up the process while preserving geometric details compared to previous approaches. Despite requiring neither ground truth masks nor monocular cues, our method outperforms baselines both qualitatively and quantitatively. In addition, we introduce a new benchmark dataset for evaluation.
RGB2Point: 3D Point Cloud Generation from Single RGB Images
Jul 20, 2024



We introduce RGB2Point, an unposed single-view RGB image to a 3D point cloud generation based on Transformer. RGB2Point takes an input image of an object and generates a dense 3D point cloud. Contrary to prior works based on CNN layers and diffusion denoising approaches, we use pre-trained Transformer layers that are fast and generate high-quality point clouds with consistent quality over available categories. Our generated point clouds demonstrate high quality on a real-world dataset, as evidenced by improved Chamfer distance (51.15%) and Earth Mover's distance (45.96%) metrics compared to the current state-of-the-art. Additionally, our approach shows a better quality on a synthetic dataset, achieving better Chamfer distance (39.26%), Earth Mover's distance (26.95%), and F-score (47.16%). Moreover, our method produces 63.1% more consistent high-quality results across various object categories compared to prior works. Furthermore, RGB2Point is computationally efficient, requiring only 2.3GB of VRAM to reconstruct a 3D point cloud from a single RGB image, and our implementation generates the results 15,133x faster than a SOTA diffusion-based model.
Diffusion Time-step Curriculum for One Image to 3D Generation
Apr 11, 2024



Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a \textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
Depth Estimation From Monocular Images With Enhanced Encoder-Decoder Architecture
Oct 15, 2024



Estimating depth from a single 2D image is a challenging task because of the need for stereo or multi-view data, which normally provides depth information. This paper deals with this challenge by introducing a novel deep learning-based approach using an encoder-decoder architecture, where the Inception-ResNet-v2 model is utilized as the encoder. According to the available literature, this is the first instance of using Inception-ResNet-v2 as an encoder for monocular depth estimation, illustrating better performance than previous models. The use of Inception-ResNet-v2 enables our model to capture complex objects and fine-grained details effectively that are generally difficult to predict. Besides, our model incorporates multi-scale feature extraction to enhance depth prediction accuracy across different kinds of object sizes and distances. We propose a composite loss function consisting of depth loss, gradient edge loss, and SSIM loss, where the weights are fine-tuned to optimize the weighted sum, ensuring better balance across different aspects of depth estimation. Experimental results on the NYU Depth V2 dataset show that our model achieves state-of-the-art performance, with an ARE of 0.064, RMSE of 0.228, and accuracy ($\delta$ $<1.25$) of 89.3%. These metrics demonstrate that our model effectively predicts depth, even in challenging circumstances, providing a scalable solution for real-world applications in robotics, 3D reconstruction, and augmented reality.
REPARO: Compositional 3D Assets Generation with Differentiable 3D Layout Alignment
May 28, 2024



Traditional image-to-3D models often struggle with scenes containing multiple objects due to biases and occlusion complexities. To address this challenge, we present REPARO, a novel approach for compositional 3D asset generation from single images. REPARO employs a two-step process: first, it extracts individual objects from the scene and reconstructs their 3D meshes using off-the-shelf image-to-3D models; then, it optimizes the layout of these meshes through differentiable rendering techniques, ensuring coherent scene composition. By integrating optimal transport-based long-range appearance loss term and high-level semantic loss term in the differentiable rendering, REPARO can effectively recover the layout of 3D assets. The proposed method can significantly enhance object independence, detail accuracy, and overall scene coherence. Extensive evaluation of multi-object scenes demonstrates that our REPARO offers a comprehensive approach to address the complexities of multi-object 3D scene generation from single images.
Physically Compatible 3D Object Modeling from a Single Image
Jun 03, 2024We present a computational framework that transforms single images into 3D physical objects. The visual geometry of a physical object in an image is determined by three orthogonal attributes: mechanical properties, external forces, and rest-shape geometry. Existing single-view 3D reconstruction methods often overlook this underlying composition, presuming rigidity or neglecting external forces. Consequently, the reconstructed objects fail to withstand real-world physical forces, resulting in instability or undesirable deformation -- diverging from their intended designs as depicted in the image. Our optimization framework addresses this by embedding physical compatibility into the reconstruction process. We explicitly decompose the three physical attributes and link them through static equilibrium, which serves as a hard constraint, ensuring that the optimized physical shapes exhibit desired physical behaviors. Evaluations on a dataset collected from Objaverse demonstrate that our framework consistently enhances the physical realism of 3D models over existing methods. The utility of our framework extends to practical applications in dynamic simulations and 3D printing, where adherence to physical compatibility is paramount.
Pano2Room: Novel View Synthesis from a Single Indoor Panorama
Aug 21, 2024



Recent single-view 3D generative methods have made significant advancements by leveraging knowledge distilled from extensive 3D object datasets. However, challenges persist in the synthesis of 3D scenes from a single view, primarily due to the complexity of real-world environments and the limited availability of high-quality prior resources. In this paper, we introduce a novel approach called Pano2Room, designed to automatically reconstruct high-quality 3D indoor scenes from a single panoramic image. These panoramic images can be easily generated using a panoramic RGBD inpainter from captures at a single location with any camera. The key idea is to initially construct a preliminary mesh from the input panorama, and iteratively refine this mesh using a panoramic RGBD inpainter while collecting photo-realistic 3D-consistent pseudo novel views. Finally, the refined mesh is converted into a 3D Gaussian Splatting field and trained with the collected pseudo novel views. This pipeline enables the reconstruction of real-world 3D scenes, even in the presence of large occlusions, and facilitates the synthesis of photo-realistic novel views with detailed geometry. Extensive qualitative and quantitative experiments have been conducted to validate the superiority of our method in single-panorama indoor novel synthesis compared to the state-of-the-art. Our code and data are available at \url{https://github.com/TrickyGo/Pano2Room}.
DiffSurf: A Transformer-based Diffusion Model for Generating and Reconstructing 3D Surfaces in Pose
Aug 27, 2024This paper presents DiffSurf, a transformer-based denoising diffusion model for generating and reconstructing 3D surfaces. Specifically, we design a diffusion transformer architecture that predicts noise from noisy 3D surface vertices and normals. With this architecture, DiffSurf is able to generate 3D surfaces in various poses and shapes, such as human bodies, hands, animals and man-made objects. Further, DiffSurf is versatile in that it can address various 3D downstream tasks including morphing, body shape variation and 3D human mesh fitting to 2D keypoints. Experimental results on 3D human model benchmarks demonstrate that DiffSurf can generate shapes with greater diversity and higher quality than previous generative models. Furthermore, when applied to the task of single-image 3D human mesh recovery, DiffSurf achieves accuracy comparable to prior techniques at a near real-time rate.