 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DTurboQuant: Training-Free Near-Optimal Quantization for 3D Reconstruction Models
Apr 07, 2026Every existing method for compressing 3D Gaussian Splatting, NeRF, or transformer-based 3D reconstructors requires learning a data-dependent codebook through per-scene fine-tuning. We show this is unnecessary. The parameter vectors that dominate storage in these models, 45-dimensional spherical harmonics in 3DGS and 1024-dimensional key-value vectors in DUSt3R, fall in a dimension range where a single random rotation transforms any input into coordinates with a known Beta distribution. This makes precomputed, data-independent Lloyd-Max quantization near-optimal, within a factor of 2.7 of the information-theoretic lower bound. We develop 3D, deriving (1) a dimension-dependent criterion that predicts which parameters can be quantized and at what bit-width before running any experiment, (2) norm-separation bounds connecting quantization MSE to rendering PSNR per scene, (3) an entry-grouping strategy extending rotation-based quantization to 2-dimensional hash grid features, and (4) a composable pruning-quantization pipeline with a closed-form compression ratio. On NeRF Synthetic, 3DTurboQuant compresses 3DGS by 3.5x with 0.02dB PSNR loss and DUSt3R KV caches by 7.9x with 39.7dB pointmap fidelity. No training, no codebook learning, no calibration data. Compression takes seconds. The code will be released (https://github.com/JaeLee18/3DTurboQuant)
Language-Guided Invariance Probing of Vision-Language Models
Nov 17, 2025Recent vision-language models (VLMs) such as CLIP, OpenCLIP, EVA02-CLIP and SigLIP achieve strong zero-shot performance, but it is unclear how reliably they respond to controlled linguistic perturbations. We introduce Language-Guided Invariance Probing (LGIP), a benchmark that measures (i) invariance to meaning-preserving paraphrases and (ii) sensitivity to meaning-changing semantic flips in image-text matching. Using 40k MS COCO images with five human captions each, we automatically generate paraphrases and rule-based flips that alter object category, color or count, and summarize model behavior with an invariance error, a semantic sensitivity gap and a positive-rate statistic. Across nine VLMs, EVA02-CLIP and large OpenCLIP variants lie on a favorable invariance-sensitivity frontier, combining low paraphrase-induced variance with consistently higher scores for original captions than for their flipped counterparts. In contrast, SigLIP and SigLIP2 show much larger invariance error and often prefer flipped captions to the human descriptions, especially for object and color edits. These failures are largely invisible to standard retrieval metrics, indicating that LGIP provides a model-agnostic diagnostic for the linguistic robustness of VLMs beyond conventional accuracy scores.
Top2Ground: A Height-Aware Dual Conditioning Diffusion Model for Robust Aerial-to-Ground View Generation
Nov 11, 2025Generating ground-level images from aerial views is a challenging task due to extreme viewpoint disparity, occlusions, and a limited field of view. We introduce Top2Ground, a novel diffusion-based method that directly generates photorealistic ground-view images from aerial input images without relying on intermediate representations such as depth maps or 3D voxels. Specifically, we condition the denoising process on a joint representation of VAE-encoded spatial features (derived from aerial RGB images and an estimated height map) and CLIP-based semantic embeddings. This design ensures the generation is both geometrically constrained by the scene's 3D structure and semantically consistent with its content. We evaluate Top2Ground on three diverse datasets: CVUSA, CVACT, and the Auto Arborist. Our approach shows 7.3% average improvement in SSIM across three benchmark datasets, showing Top2Ground can robustly handle both wide and narrow fields of view, highlighting its strong generalization capabilities.
Tuning-Free Amodal Segmentation via the Occlusion-Free Bias of Inpainting Models
Mar 24, 2025Amodal segmentation aims to predict segmentation masks for both the visible and occluded regions of an object. Most existing works formulate this as a supervised learning problem, requiring manually annotated amodal masks or synthetic training data. Consequently, their performance depends on the quality of the datasets, which often lack diversity and scale. This work introduces a tuning-free approach that repurposes pretrained diffusion-based inpainting models for amodal segmentation. Our approach is motivated by the "occlusion-free bias" of inpainting models, i.e., the inpainted objects tend to be complete objects without occlusions. Specifically, we reconstruct the occluded regions of an object via inpainting and then apply segmentation, all without additional training or fine-tuning. Experiments on five datasets demonstrate the generalizability and robustness of our approach. On average, our approach achieves 5.3% more accurate masks over the state-of-the-art.
RGB2Point: 3D Point Cloud Generation from Single RGB Images
Jul 20, 2024



We introduce RGB2Point, an unposed single-view RGB image to a 3D point cloud generation based on Transformer. RGB2Point takes an input image of an object and generates a dense 3D point cloud. Contrary to prior works based on CNN layers and diffusion denoising approaches, we use pre-trained Transformer layers that are fast and generate high-quality point clouds with consistent quality over available categories. Our generated point clouds demonstrate high quality on a real-world dataset, as evidenced by improved Chamfer distance (51.15%) and Earth Mover's distance (45.96%) metrics compared to the current state-of-the-art. Additionally, our approach shows a better quality on a synthetic dataset, achieving better Chamfer distance (39.26%), Earth Mover's distance (26.95%), and F-score (47.16%). Moreover, our method produces 63.1% more consistent high-quality results across various object categories compared to prior works. Furthermore, RGB2Point is computationally efficient, requiring only 2.3GB of VRAM to reconstruct a 3D point cloud from a single RGB image, and our implementation generates the results 15,133x faster than a SOTA diffusion-based model.
Tree-D Fusion: Simulation-Ready Tree Dataset from Single Images with Diffusion Priors
Jul 14, 2024We introduce Tree D-fusion, featuring the first collection of 600,000 environmentally aware, 3D simulation-ready tree models generated through Diffusion priors. Each reconstructed 3D tree model corresponds to an image from Google's Auto Arborist Dataset, comprising street view images and associated genus labels of trees across North America. Our method distills the scores of two tree-adapted diffusion models by utilizing text prompts to specify a tree genus, thus facilitating shape reconstruction. This process involves reconstructing a 3D tree envelope filled with point markers, which are subsequently utilized to estimate the tree's branching structure using the space colonization algorithm conditioned on a specified genus.
Hands-Free VR
Feb 23, 2024
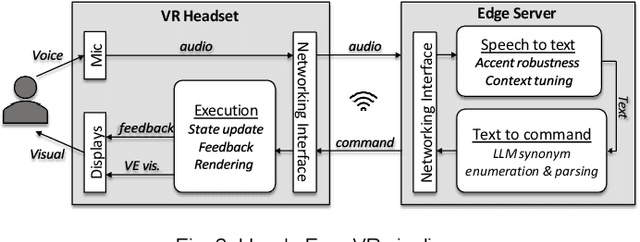
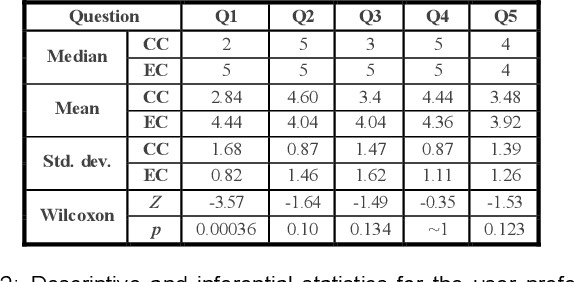
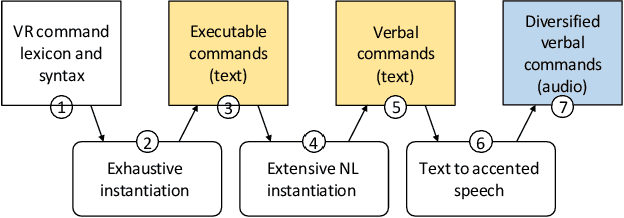
The paper introduces Hands-Free VR, a voice-based natural-language interface for VR. The user gives a command using their voice, the speech audio data is converted to text using a speech-to-text deep learning model that is fine-tuned for robustness to word phonetic similarity and to spoken English accents, and the text is mapped to an executable VR command using a large language model that is robust to natural language diversity. Hands-Free VR was evaluated in a controlled within-subjects study (N = 22) that asked participants to find specific objects and to place them in various configurations. In the control condition participants used a conventional VR user interface to grab, carry, and position the objects using the handheld controllers. In the experimental condition participants used Hands-Free VR. The results confirm that: (1) Hands-Free VR is robust to spoken English accents, as for 20 of our participants English was not their first language, and to word phonetic similarity, correctly transcribing the voice command 96.71% of the time; (2) Hands-Free VR is robust to natural language diversity, correctly mapping the transcribed command to an executable command in 97.83% of the time; (3) Hands-Free VR had a significant efficiency advantage over the conventional VR interface in terms of task completion time, total viewpoint translation, total view direction rotation, and total left and right hand translations; (4) Hands-Free VR received high user preference ratings in terms of ease of use, intuitiveness, ergonomics, reliability, and desirability.
SnakeVoxFormer: Transformer-based Single Image\\Voxel Reconstruction with Run Length Encoding
Mar 28, 2023



Deep learning-based 3D object reconstruction has achieved unprecedented results. Among those, the transformer deep neural model showed outstanding performance in many applications of computer vision. We introduce SnakeVoxFormer, a novel, 3D object reconstruction in voxel space from a single image using the transformer. The input to SnakeVoxFormer is a 2D image, and the result is a 3D voxel model. The key novelty of our approach is in using the run-length encoding that traverses (like a snake) the voxel space and encodes wide spatial differences into a 1D structure that is suitable for transformer encoding. We then use dictionary encoding to convert the discovered RLE blocks into tokens that are used for the transformer. The 1D representation is a lossless 3D shape data compression method that converts to 1D data that use only about 1% of the original data size. We show how different voxel traversing strategies affect the effect of encoding and reconstruction. We compare our method with the state-of-the-art for 3D voxel reconstruction from images and our method improves the state-of-the-art methods by at least 2.8% and up to 19.8%.
Covfefe: A Computer Vision Approach For Estimating Force Exertion
Sep 25, 2018
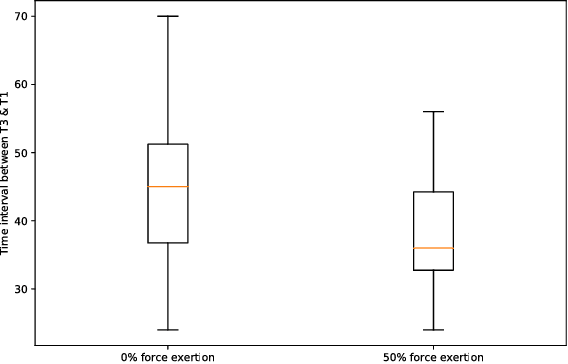


Cumulative exposure to repetitive and forceful activities may lead to musculoskeletal injuries which not only reduce workers' efficiency and productivity, but also affect their quality of life. Thus, widely accessible techniques for reliable detection of unsafe muscle force exertion levels for human activity is necessary for their well-being. However, measurement of force exertion levels is challenging and the existing techniques pose a great challenge as they are either intrusive, interfere with human-machine interface, and/or subjective in the nature, thus are not scalable for all workers. In this work, we use face videos and the photoplethysmography (PPG) signals to classify force exertion levels of 0\%, 50\%, and 100\% (representing rest, moderate effort, and high effort), thus providing a non-intrusive and scalable approach. Efficient feature extraction approaches have been investigated, including standard deviation of the movement of different landmarks of the face, distances between peaks and troughs in the PPG signals. We note that the PPG signals can be obtained from the face videos, thus giving an efficient classification algorithm for the force exertion levels using face videos. Based on the data collected from 20 subjects, features extracted from the face videos give 90\% accuracy in classification among the 100\% and the combination of 0\% and 50\% datasets. Further combining the PPG signals provide 81.7\% accuracy. The approach is also shown to be robust to the correctly identify force level when the person is talking, even though such datasets are not included in the training.