 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Infilling
Text Infilling is the task of predicting missing spans of text which are consistent with the preceding and subsequent text. Text Infilling is a generalization of the cloze task—cloze historically refers to infilling individual words.
Papers and Code
Unlocking Prompt Infilling Capability for Diffusion Language Models
Apr 04, 2026Masked diffusion language models (dLMs) generate text through bidirectional denoising, yet this capability remains locked for infilling prompts. This limitation is an artifact of the current supervised finetuning (SFT) convention of applying response-only masking. To unlock this capability, we extend full-sequence masking during SFT, where both prompts and responses are masked jointly. Once unlocked, the model infills masked portions of a prompt template conditioned on few-shot examples. We show that such model-infilled prompts match or surpass manually designed templates, transfer effectively across models, and are complementary to existing prompt optimization methods. Our results suggest that training practices, not architectural limitations, are the primary bottleneck preventing masked diffusion language models from infilling effective prompts
Diffusion LMs Can Approximate Optimal Infilling Lengths Implicitly
Jan 31, 2026Diffusion language models (DLMs) provide a bidirectional generation framework naturally suited for infilling, yet their performance is constrained by the pre-specified infilling length. In this paper, we reveal that DLMs possess an inherent ability to discover the correct infilling length. We identify two key statistical phenomena in the first-step denoising confidence: a local \textit{Oracle Peak} that emerges near the ground-truth length and a systematic \textit{Length Bias} that often obscures this signal. By leveraging this signal and calibrating the bias, our training-free method \textbf{CAL} (\textbf{C}alibrated \textbf{A}daptive \textbf{L}ength) enables DLMs to approximate the optimal length through an efficient search before formal decoding. Empirical evaluations demonstrate that CAL improves Pass@1 by up to 47.7\% over fixed-length baselines and 40.5\% over chat-based adaptive methods in code infilling, while boosting BLEU-2 and ROUGE-L by up to 8.5\% and 9.9\% in text infilling. These results demonstrate that CAL paves the way for robust DLM infilling without requiring any specialized training. Code is available at https://github.com/NiuHechang/Calibrated_Adaptive_Length.
LIME-LLM: Probing Models with Fluent Counterfactuals, Not Broken Text
Jan 16, 2026Local explanation methods such as LIME (Ribeiro et al., 2016) remain fundamental to trustworthy AI, yet their application to NLP is limited by a reliance on random token masking. These heuristic perturbations frequently generate semantically invalid, out-of-distribution inputs that weaken the fidelity of local surrogate models. While recent generative approaches such as LLiMe (Angiulli et al., 2025b) attempt to mitigate this by employing Large Language Models for neighborhood generation, they rely on unconstrained paraphrasing that introduces confounding variables, making it difficult to isolate specific feature contributions. We introduce LIME-LLM, a framework that replaces random noise with hypothesis-driven, controlled perturbations. By enforcing a strict "Single Mask-Single Sample" protocol and employing distinct neutral infill and boundary infill strategies, LIME-LLM constructs fluent, on-manifold neighborhoods that rigorously isolate feature effects. We evaluate our method against established baselines (LIME, SHAP, Integrated Gradients) and the generative LLiMe baseline across three diverse benchmarks: CoLA, SST-2, and HateXplain using human-annotated rationales as ground truth. Empirical results demonstrate that LIME-LLM establishes a new benchmark for black-box NLP explainability, achieving significant improvements in local explanation fidelity compared to both traditional perturbation-based methods and recent generative alternatives.
SyMuPe: Affective and Controllable Symbolic Music Performance
Nov 05, 2025Emotions are fundamental to the creation and perception of music performances. However, achieving human-like expression and emotion through machine learning models for performance rendering remains a challenging task. In this work, we present SyMuPe, a novel framework for developing and training affective and controllable symbolic piano performance models. Our flagship model, PianoFlow, uses conditional flow matching trained to solve diverse multi-mask performance inpainting tasks. By design, it supports both unconditional generation and infilling of music performance features. For training, we use a curated, cleaned dataset of 2,968 hours of aligned musical scores and expressive MIDI performances. For text and emotion control, we integrate a piano performance emotion classifier and tune PianoFlow with the emotion-weighted Flan-T5 text embeddings provided as conditional inputs. Objective and subjective evaluations against transformer-based baselines and existing models show that PianoFlow not only outperforms other approaches, but also achieves performance quality comparable to that of human-recorded and transcribed MIDI samples. For emotion control, we present and analyze samples generated under different text conditioning scenarios. The developed model can be integrated into interactive applications, contributing to the creation of more accessible and engaging music performance systems.
* ACM Multimedia 2025. Extended version with supplementary material
UniVoice: Unifying Autoregressive ASR and Flow-Matching based TTS with Large Language Models
Oct 06, 2025



Large language models (LLMs) have demonstrated promising performance in both automatic speech recognition (ASR) and text-to-speech (TTS) systems, gradually becoming the mainstream approach. However, most current approaches address these tasks separately rather than through a unified framework. This work aims to integrate these two tasks into one unified model. Although discrete speech tokenization enables joint modeling, its inherent information loss limits performance in both recognition and generation. In this work, we present UniVoice, a unified LLM framework through continuous representations that seamlessly integrates speech recognition and synthesis within a single model. Our approach combines the strengths of autoregressive modeling for speech recognition with flow matching for high-quality generation. To mitigate the inherent divergence between autoregressive and flow-matching models, we further design a dual attention mechanism, which switches between a causal mask for recognition and a bidirectional attention mask for synthesis. Furthermore, the proposed text-prefix-conditioned speech infilling method enables high-fidelity zero-shot voice cloning. Experimental results demonstrate that our method can achieve or exceed current single-task modeling methods in both ASR and zero-shot TTS tasks. This work explores new possibilities for end-to-end speech understanding and generation.
DAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
Sep 18, 2025


This paper presents DAIEN-TTS, a zero-shot text-to-speech (TTS) framework that enables ENvironment-aware synthesis through Disentangled Audio Infilling. By leveraging separate speaker and environment prompts, DAIEN-TTS allows independent control over the timbre and the background environment of the synthesized speech. Built upon F5-TTS, the proposed DAIEN-TTS first incorporates a pretrained speech-environment separation (SES) module to disentangle the environmental speech into mel-spectrograms of clean speech and environment audio. Two random span masks of varying lengths are then applied to both mel-spectrograms, which, together with the text embedding, serve as conditions for infilling the masked environmental mel-spectrogram, enabling the simultaneous continuation of personalized speech and time-varying environmental audio. To further enhance controllability during inference, we adopt dual class-free guidance (DCFG) for the speech and environment components and introduce a signal-to-noise ratio (SNR) adaptation strategy to align the synthesized speech with the environment prompt. Experimental results demonstrate that DAIEN-TTS generates environmental personalized speech with high naturalness, strong speaker similarity, and high environmental fidelity.
Flexible-length Text Infilling for Discrete Diffusion Models
Jun 16, 2025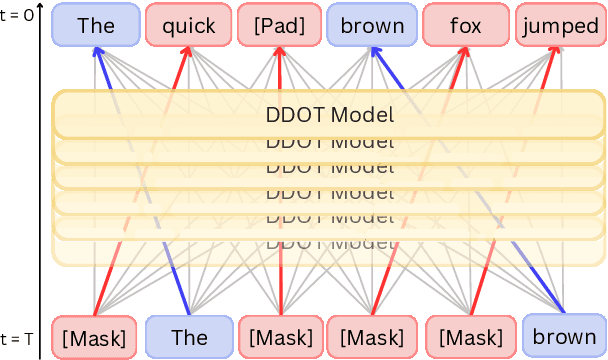

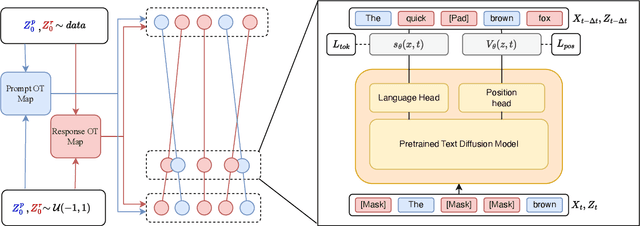

Discrete diffusion models are a new class of text generators that offer advantages such as bidirectional context use, parallelizable generation, and flexible prompting compared to autoregressive models. However, a critical limitation of discrete diffusion models is their inability to perform flexible-length or flexible-position text infilling without access to ground-truth positional data. We introduce \textbf{DDOT} (\textbf{D}iscrete \textbf{D}iffusion with \textbf{O}ptimal \textbf{T}ransport Position Coupling), the first discrete diffusion model to overcome this challenge. DDOT jointly denoises token values and token positions, employing a novel sample-level Optimal Transport (OT) coupling. This coupling preserves relative token ordering while dynamically adjusting the positions and length of infilled segments, a capability previously missing in text diffusion. Our method is orthogonal to existing discrete text diffusion methods and is compatible with various pretrained text denoisers. Extensive experiments on text infilling benchmarks such as One-Billion-Word and Yelp demonstrate that DDOT outperforms naive diffusion baselines. Furthermore, DDOT achieves performance on par with state-of-the-art non-autoregressive models and enables significant improvements in training efficiency and flexibility.
ClozeMath: Improving Mathematical Reasoning in Language Models by Learning to Fill Equations
Jun 04, 2025The capabilities of large language models (LLMs) have been enhanced by training on data that reflects human thought processes, such as the Chain-of-Thought format. However, evidence suggests that the conventional scheme of next-word prediction may not fully capture how humans learn to think. Inspired by how humans generalize mathematical reasoning, we propose a new approach named ClozeMath to fine-tune LLMs for mathematical reasoning. Our ClozeMath involves a text-infilling task that predicts masked equations from a given solution, analogous to cloze exercises used in human learning. Experiments on GSM8K, MATH, and GSM-Symbolic show that ClozeMath surpasses the strong baseline Masked Thought in performance and robustness, with two test-time scaling decoding algorithms, Beam Search and Chain-of-Thought decoding. Additionally, we conduct an ablation study to analyze the effects of various architectural and implementation choices on our approach.
LaViDa: A Large Diffusion Language Model for Multimodal Understanding
May 22, 2025Modern Vision-Language Models (VLMs) can solve a wide range of tasks requiring visual reasoning. In real-world scenarios, desirable properties for VLMs include fast inference and controllable generation (e.g., constraining outputs to adhere to a desired format). However, existing autoregressive (AR) VLMs like LLaVA struggle in these aspects. Discrete diffusion models (DMs) offer a promising alternative, enabling parallel decoding for faster inference and bidirectional context for controllable generation through text-infilling. While effective in language-only settings, DMs' potential for multimodal tasks is underexplored. We introduce LaViDa, a family of VLMs built on DMs. We build LaViDa by equipping DMs with a vision encoder and jointly fine-tune the combined parts for multimodal instruction following. To address challenges encountered, LaViDa incorporates novel techniques such as complementary masking for effective training, prefix KV cache for efficient inference, and timestep shifting for high-quality sampling. Experiments show that LaViDa achieves competitive or superior performance to AR VLMs on multi-modal benchmarks such as MMMU, while offering unique advantages of DMs, including flexible speed-quality tradeoff, controllability, and bidirectional reasoning. On COCO captioning, LaViDa surpasses Open-LLaVa-Next-8B by +4.1 CIDEr with 1.92x speedup. On bidirectional tasks, it achieves +59% improvement on Constrained Poem Completion. These results demonstrate LaViDa as a strong alternative to AR VLMs. Code and models will be released in the camera-ready version.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025



Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.