 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEST: Narrative Event Structures in Time for Long Video Understanding
Jun 18, 2026Recent progress in vision-language models has enabled the processing of increasingly long video sequences, but the ability to handle extended token streams does not translate to understanding of narrative structure in long videos. Existing long video benchmarks focus on needle-in-a-haystack retrieval rather than evaluating how low-level actions form events, how events interact across time, and how narratives progress, for example, whether a model can connect an early setback, such as a job loss to a later relationship breakup, despite long gaps, intervening scenes, or flashbacks that reframe what occurred. We introduce NEST (Narrative Event Structures in Time for Long Video Understanding), a dataset of 1005 full-length movies (avg. 98 minutes), each annotated with 102 multimodal narrative events grounded in visual content, dialogue, and audio. NEST captures multimodal narrative events with structured annotations grounded in visual content, dialogue, and audio, and links them through relations that reflect narrative structure, including temporal ordering, hierarchical composition, and long-range dependencies. We introduce baselines for event trigger detection (ETD), event localization (EL), event argument extraction (EAE), and event relation extraction (ERE). The benchmark is highly challenging for grounded event discovery, with ETD below 8%, EL under 6%, and EAE below 11%. In contrast, ERE is more tractable once events are given, reaching 35.45% F1 zero-shot and 44.42% F1 after fine-tuning.
SteerVLM: Robust Model Control through Lightweight Activation Steering for Vision Language Models
Oct 30, 2025This work introduces SteerVLM, a lightweight steering module designed to guide Vision-Language Models (VLMs) towards outputs that better adhere to desired instructions. Our approach learns from the latent embeddings of paired prompts encoding target and converse behaviors to dynamically adjust activations connecting the language modality with image context. This allows for fine-grained, inference-time control over complex output semantics without modifying model weights while preserving performance on off-target tasks. Our steering module requires learning parameters equal to 0.14% of the original VLM's size. Our steering module gains model control through dimension-wise activation modulation and adaptive steering across layers without requiring pre-extracted static vectors or manual tuning of intervention points. Furthermore, we introduce VNIA (Visual Narrative Intent Alignment), a multimodal dataset specifically created to facilitate the development and evaluation of VLM steering techniques. Our method outperforms existing intervention techniques on steering and hallucination mitigation benchmarks for VLMs and proposes a robust solution for multimodal model control through activation engineering.
Maximal Matching Matters: Preventing Representation Collapse for Robust Cross-Modal Retrieval
Jun 26, 2025



Cross-modal image-text retrieval is challenging because of the diverse possible associations between content from different modalities. Traditional methods learn a single-vector embedding to represent semantics of each sample, but struggle to capture nuanced and diverse relationships that can exist across modalities. Set-based approaches, which represent each sample with multiple embeddings, offer a promising alternative, as they can capture richer and more diverse relationships. In this paper, we show that, despite their promise, these set-based representations continue to face issues including sparse supervision and set collapse, which limits their effectiveness. To address these challenges, we propose Maximal Pair Assignment Similarity to optimize one-to-one matching between embedding sets which preserve semantic diversity within the set. We also introduce two loss functions to further enhance the representations: Global Discriminative Loss to enhance distinction among embeddings, and Intra-Set Divergence Loss to prevent collapse within each set. Our method achieves state-of-the-art performance on MS-COCO and Flickr30k without relying on external data.
Flexible-length Text Infilling for Discrete Diffusion Models
Jun 16, 2025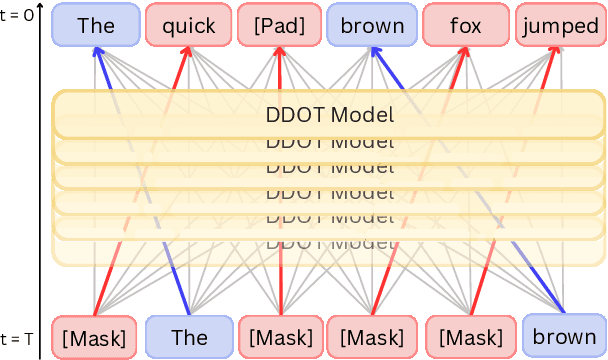

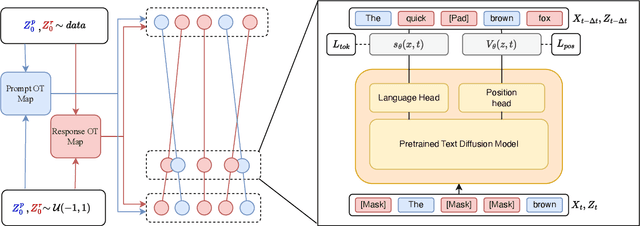

Discrete diffusion models are a new class of text generators that offer advantages such as bidirectional context use, parallelizable generation, and flexible prompting compared to autoregressive models. However, a critical limitation of discrete diffusion models is their inability to perform flexible-length or flexible-position text infilling without access to ground-truth positional data. We introduce \textbf{DDOT} (\textbf{D}iscrete \textbf{D}iffusion with \textbf{O}ptimal \textbf{T}ransport Position Coupling), the first discrete diffusion model to overcome this challenge. DDOT jointly denoises token values and token positions, employing a novel sample-level Optimal Transport (OT) coupling. This coupling preserves relative token ordering while dynamically adjusting the positions and length of infilled segments, a capability previously missing in text diffusion. Our method is orthogonal to existing discrete text diffusion methods and is compatible with various pretrained text denoisers. Extensive experiments on text infilling benchmarks such as One-Billion-Word and Yelp demonstrate that DDOT outperforms naive diffusion baselines. Furthermore, DDOT achieves performance on par with state-of-the-art non-autoregressive models and enables significant improvements in training efficiency and flexibility.