 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Motion Anchors: Bridging Motion and Meaning in Co-Speech Gestures
Jun 01, 2026Learning a shared representation between spoken text and gesture is central to co-speech gesture retrieval, synthesis, and understanding, but remains challenging for semantically meaningful gestures whose communicative intent is not captured by motion alone. Direct contrastive alignment between transcripts and continuous motion embeddings often overemphasizes low-level kinematics and misses the symbolic content of semantic gestures. We propose semantic motion anchors, natural-language abstractions of gesture motion capturing physical form and communicative intent. Our method discretizes 3D gestures into body-hand motion primitives, verbalizes them into structured descriptions, and grounds them in the transcript to provide auxiliary contrastive supervision. On BEAT2, our method improves text-to-gesture R@1 by 8.2% over a direct text-motion baseline and outperforms prior retrieval approaches on text to gesture and gesture to text retrieval directions. Beyond aggregate retrieval metrics, semantic motion anchor supervision helps retrieve gestures that are semantically meaningful for the spoken query, rather than defaulting to generic motion patterns. A downstream retrieval-augmented gesture generation study showed that users significantly preferred gestures retrieved by our approach over a retrieval-augmented generation baseline, demonstrating that semantically grounded retrieval translates to gestures that better convey communicative intent in downstream generation.
MuPHI: Learning Implicit Multimodal Harm Reasoning via Semantically Grounded Reward Optimization
May 28, 2026Understanding how harm emerges from interaction between otherwise benign image-text pairs requires intent-aware cross-modal reasoning beyond surface-level features. Existing vision-language models (VLMs) excel at literal reasoning over perceptual cues but often fail to derive harmful semantics that rely on implicit, context-dependent reasoning. To evaluate VLMs on compositional harm detection and reasoning, we introduce Multimodal Pragmatic Harm Interpretation (MuPHI), a dataset containing image-text pairs where harm is encoded in subtle multimodal cues. MuPHI spans diverse harm categories and includes annotated harm rationales for assessing VLM reasoning chains. To improve both detection and reasoning in VLMs, we propose MuPHIRM, a reasoning-augmented training framework which learns joint semantics by optimizing multi-perspective rewards. MuPHIRM improves both harm detection and reasoning quality of VLMs while demonstrating superior out-of-distribution robustness compared to both trained and inference-time baselines. Our findings suggest that reasoning-oriented reward optimization offers a promising direction towards building multimodal systems that generalize beyond benchmark-specific shortcuts.
Revisiting Modality Invariance in a Multilingual Speech-Text Model via Neuron-Level Analysis
Jan 24, 2026Multilingual speech-text foundation models aim to process language uniformly across both modality and language, yet it remains unclear whether they internally represent the same language consistently when it is spoken versus written. We investigate this question in SeamlessM4T v2 through three complementary analyses that probe where language and modality information is encoded, how selective neurons causally influence decoding, and how concentrated this influence is across the network. We identify language- and modality-selective neurons using average-precision ranking, investigate their functional role via median-replacement interventions at inference time, and analyze activation-magnitude inequality across languages and modalities. Across experiments, we find evidence of incomplete modality invariance. Although encoder representations become increasingly language-agnostic, this compression makes it more difficult for the shared decoder to recover the language of origin when constructing modality-agnostic representations, particularly when adapting from speech to text. We further observe sharply localized modality-selective structure in cross-attention key and value projections. Finally, speech-conditioned decoding and non-dominant scripts exhibit higher activation concentration, indicating heavier reliance on a small subset of neurons, which may underlie increased brittleness across modalities and languages.
System-Mediated Attention Imbalances Make Vision-Language Models Say Yes
Jan 18, 2026Vision-language model (VLM) hallucination is commonly linked to imbalanced allocation of attention across input modalities: system, image and text. However, existing mitigation strategies tend towards an image-centric interpretation of these imbalances, often prioritising increased image attention while giving less consideration to the roles of the other modalities. In this study, we evaluate a more holistic, system-mediated account, which attributes these imbalances to functionally redundant system weights that reduce attention to image and textual inputs. We show that this framework offers a useful empirical perspective on the yes-bias, a common form of hallucination in which VLMs indiscriminately respond 'yes'. Causally redistributing attention from the system modality to image and textual inputs substantially suppresses this bias, often outperforming existing approaches. We further present evidence suggesting that system-mediated attention imbalances contribute to the yes-bias by encouraging a default reliance on coarse input representations, which are effective for some tasks but ill-suited to others. Taken together, these findings firmly establish system attention as a key factor in VLM hallucination and highlight its potential as a lever for mitigation.
Synthetic Data Augmentation for Cross-domain Implicit Discourse Relation Recognition
Mar 26, 2025



Implicit discourse relation recognition (IDRR) -- the task of identifying the implicit coherence relation between two text spans -- requires deep semantic understanding. Recent studies have shown that zero- or few-shot approaches significantly lag behind supervised models, but LLMs may be useful for synthetic data augmentation, where LLMs generate a second argument following a specified coherence relation. We applied this approach in a cross-domain setting, generating discourse continuations using unlabelled target-domain data to adapt a base model which was trained on source-domain labelled data. Evaluations conducted on a large-scale test set revealed that different variations of the approach did not result in any significant improvements. We conclude that LLMs often fail to generate useful samples for IDRR, and emphasize the importance of considering both statistical significance and comparability when evaluating IDRR models.
Enhancing Spoken Discourse Modeling in Language Models Using Gestural Cues
Mar 05, 2025



Research in linguistics shows that non-verbal cues, such as gestures, play a crucial role in spoken discourse. For example, speakers perform hand gestures to indicate topic shifts, helping listeners identify transitions in discourse. In this work, we investigate whether the joint modeling of gestures using human motion sequences and language can improve spoken discourse modeling in language models. To integrate gestures into language models, we first encode 3D human motion sequences into discrete gesture tokens using a VQ-VAE. These gesture token embeddings are then aligned with text embeddings through feature alignment, mapping them into the text embedding space. To evaluate the gesture-aligned language model on spoken discourse, we construct text infilling tasks targeting three key discourse cues grounded in linguistic research: discourse connectives, stance markers, and quantifiers. Results show that incorporating gestures enhances marker prediction accuracy across the three tasks, highlighting the complementary information that gestures can offer in modeling spoken discourse. We view this work as an initial step toward leveraging non-verbal cues to advance spoken language modeling in language models.
An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
Jun 20, 2024Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
Using Positive Matching Contrastive Loss with Facial Action Units to mitigate bias in Facial Expression Recognition
Mar 08, 2023Machine learning models automatically learn discriminative features from the data, and are therefore susceptible to learn strongly-correlated biases, such as using protected attributes like gender and race. Most existing bias mitigation approaches aim to explicitly reduce the model's focus on these protected features. In this work, we propose to mitigate bias by explicitly guiding the model's focus towards task-relevant features using domain knowledge, and we hypothesize that this can indirectly reduce the dependence of the model on spurious correlations it learns from the data. We explore bias mitigation in facial expression recognition systems using facial Action Units (AUs) as the task-relevant feature. To this end, we introduce Feature-based Positive Matching Contrastive Loss which learns the distances between the positives of a sample based on the similarity between their corresponding AU embeddings. We compare our approach with representative baselines and show that incorporating task-relevant features via our method can improve model fairness at minimal cost to classification performance.
Not All Negatives are Equal: Label-Aware Contrastive Loss for Fine-grained Text Classification
Sep 12, 2021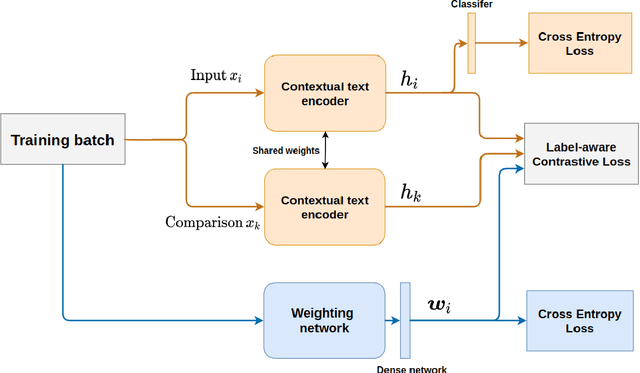

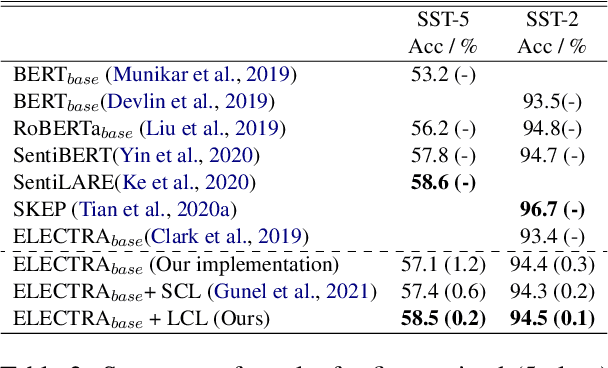
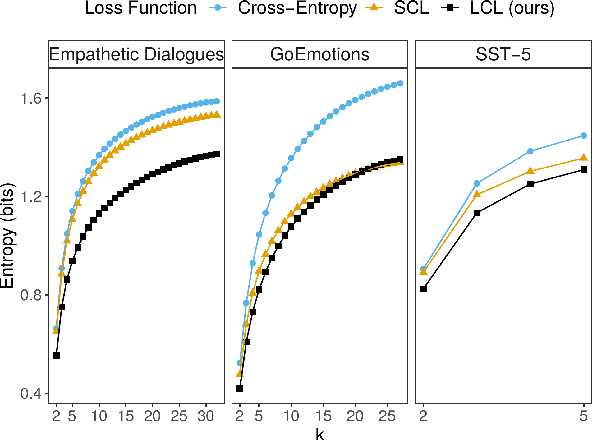
Fine-grained classification involves dealing with datasets with larger number of classes with subtle differences between them. Guiding the model to focus on differentiating dimensions between these commonly confusable classes is key to improving performance on fine-grained tasks. In this work, we analyse the contrastive fine-tuning of pre-trained language models on two fine-grained text classification tasks, emotion classification and sentiment analysis. We adaptively embed class relationships into a contrastive objective function to help differently weigh the positives and negatives, and in particular, weighting closely confusable negatives more than less similar negative examples. We find that Label-aware Contrastive Loss outperforms previous contrastive methods, in the presence of larger number and/or more confusable classes, and helps models to produce output distributions that are more differentiated.
Using Knowledge-Embedded Attention to Augment Pre-trained Language Models for Fine-Grained Emotion Recognition
Jul 31, 2021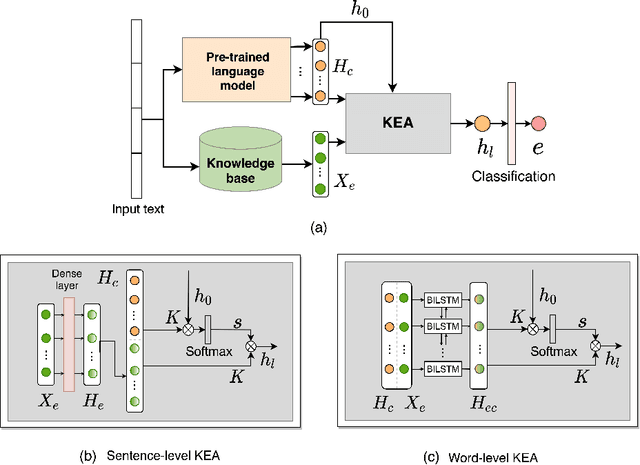
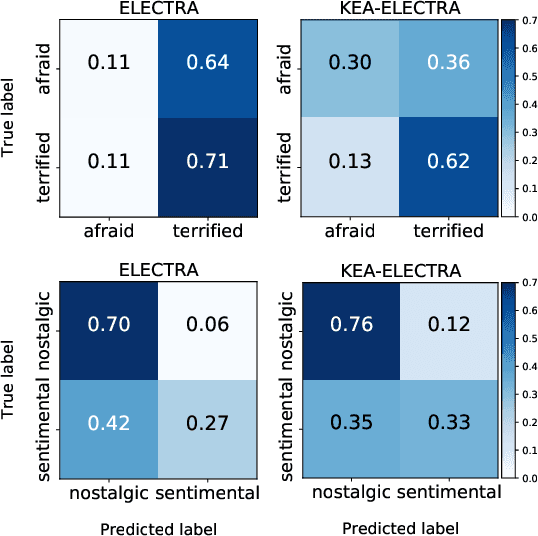
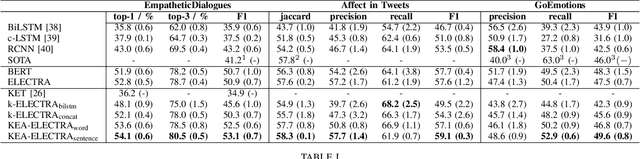

Modern emotion recognition systems are trained to recognize only a small set of emotions, and hence fail to capture the broad spectrum of emotions people experience and express in daily life. In order to engage in more empathetic interactions, future AI has to perform \textit{fine-grained} emotion recognition, distinguishing between many more varied emotions. Here, we focus on improving fine-grained emotion recognition by introducing external knowledge into a pre-trained self-attention model. We propose Knowledge-Embedded Attention (KEA) to use knowledge from emotion lexicons to augment the contextual representations from pre-trained ELECTRA and BERT models. Our results and error analyses outperform previous models on several datasets, and is better able to differentiate closely-confusable emotions, such as afraid and terrified.