 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Noise on LLM-Models Performance in Abstraction and Reasoning Corpus (ARC) Tasks with Model Temperature Considerations
Apr 22, 2025Recent advancements in Large Language Models (LLMs) have generated growing interest in their structured reasoning capabilities, particularly in tasks involving abstraction and pattern recognition. The Abstraction and Reasoning Corpus (ARC) benchmark plays a crucial role in evaluating these capabilities by testing how well AI models generalize to novel problems. While GPT-4o demonstrates strong performance by solving all ARC tasks under zero-noise conditions, other models like DeepSeek R1 and LLaMA 3.2 fail to solve any, suggesting limitations in their ability to reason beyond simple pattern matching. To explore this gap, we systematically evaluate these models across different noise levels and temperature settings. Our results reveal that the introduction of noise consistently impairs model performance, regardless of architecture. This decline highlights a shared vulnerability: current LLMs, despite showing signs of abstract reasoning, remain highly sensitive to input perturbations. Such fragility raises concerns about their real-world applicability, where noise and uncertainty are common. By comparing how different model architectures respond to these challenges, we offer insights into the structural weaknesses of modern LLMs in reasoning tasks. This work underscores the need for developing more robust and adaptable AI systems capable of handling the ambiguity and variability inherent in real-world scenarios. Our findings aim to guide future research toward enhancing model generalization, robustness, and alignment with human-like cognitive flexibility.
Exploring Next Token Prediction in Theory of Mind (ToM) Tasks: Comparative Experiments with GPT-2 and LLaMA-2 AI Models
Apr 22, 2025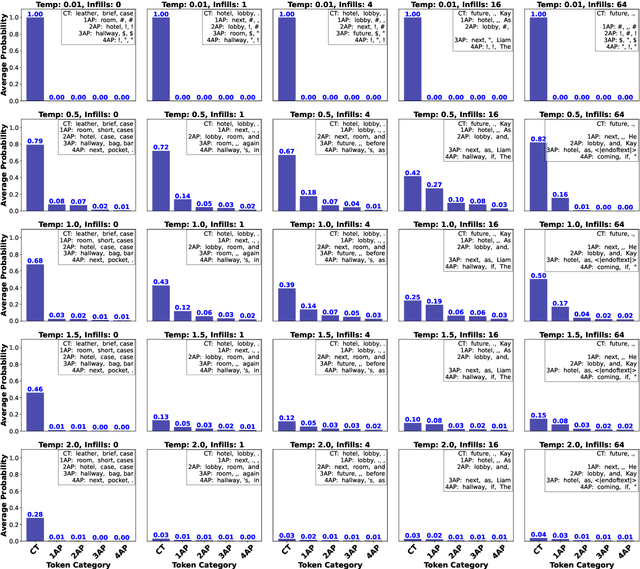
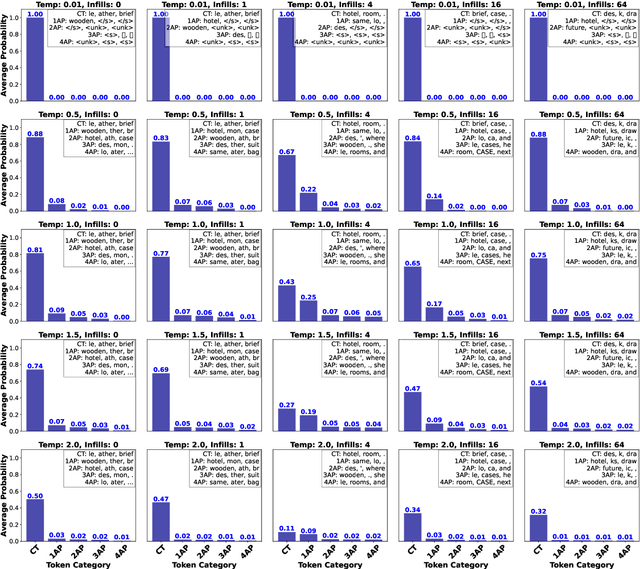
Language models have made significant progress in generating coherent text and predicting next tokens based on input prompts. This study compares the next-token prediction performance of two well-known models: OpenAI's GPT-2 and Meta's Llama-2-7b-chat-hf on Theory of Mind (ToM) tasks. To evaluate their capabilities, we built a dataset from 10 short stories sourced from the Explore ToM Dataset. We enhanced these stories by programmatically inserting additional sentences (infills) using GPT-4, creating variations that introduce different levels of contextual complexity. This setup enables analysis of how increasing context affects model performance. We tested both models under four temperature settings (0.01, 0.5, 1.0, 2.0) and evaluated their ability to predict the next token across three reasoning levels. Zero-order reasoning involves tracking the state, either current (ground truth) or past (memory). First-order reasoning concerns understanding another's mental state (e.g., "Does Anne know the apple is salted?"). Second-order reasoning adds recursion (e.g., "Does Anne think that Charles knows the apple is salted?"). Our results show that adding more infill sentences slightly reduces prediction accuracy, as added context increases complexity and ambiguity. Llama-2 consistently outperforms GPT-2 in prediction accuracy, especially at lower temperatures, demonstrating greater confidence in selecting the most probable token. As reasoning complexity rises, model responses diverge more. Notably, GPT-2 and Llama-2 display greater variability in predictions during first- and second-order reasoning tasks. These findings illustrate how model architecture, temperature, and contextual complexity influence next-token prediction, contributing to a better understanding of the strengths and limitations of current language models.