 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-stream
Papers and Code
Uni-MDTrack: Learning Decoupled Memory and Dynamic States for Parameter-Efficient Visual Tracking in All Modality
Mar 15, 2026With the advent of Transformer-based one-stream trackers that possess strong capability in inter-frame relation modeling, recent research has increasingly focused on how to introduce spatio-temporal context. However, most existing methods rely on a limited number of historical frames, which not only leads to insufficient utilization of the context, but also inevitably increases the length of input and incurs prohibitive computational overhead. Methods that query an external memory bank, on the other hand, suffer from inadequate fusion between the retrieved spatio-temporal features and the backbone. Moreover, using discrete historical frames as context overlooks the rich dynamics of the target. To address the issues, we propose Uni-MDTrack, which consists of two core components: Memory-Aware Compression Prompt (MCP) module and Dynamic State Fusion (DSF) module. MCP effectively compresses rich memory features into memory-aware prompt tokens, which deeply interact with the input throughout the entire backbone, significantly enhancing the performance while maintaining a stable computational load. DSF complements the discrete memory by capturing the continuous dynamic, progressively introducing the updated dynamic state features from shallow to deep layers, while also preserving high efficiency. Uni-MDTrack also supports unified tracking across RGB, RGB-D/T/E, and RGB-Language modalities. Experiments show that in Uni-MDTrack, training only the MCP, DSF, and prediction head, keeping the proportion of trainable parameters around 30%, yields substantial performance gains, achieves state-of-the-art results on 10 datasets spanning five modalities. Furthermore, both MCP and DSF exhibit excellent generality, functioning as plug-and-play components that can boost the performance of various baseline trackers, while significantly outperforming existing parameter-efficient training approaches.
UTPTrack: Towards Simple and Unified Token Pruning for Visual Tracking
Feb 27, 2026One-stream Transformer-based trackers achieve advanced performance in visual object tracking but suffer from significant computational overhead that hinders real-time deployment. While token pruning offers a path to efficiency, existing methods are fragmented. They typically prune the search region, dynamic template, and static template in isolation, overlooking critical inter-component dependencies, which yields suboptimal pruning and degraded accuracy. To address this, we introduce UTPTrack, a simple and Unified Token Pruning framework that, for the first time, jointly compresses all three components. UTPTrack employs an attention-guided, token type-aware strategy to holistically model redundancy, a design that seamlessly supports unified tracking across multimodal and language-guided tasks within a single model. Extensive evaluations on 10 benchmarks demonstrate that UTPTrack achieves a new state-of-the-art in the accuracy-efficiency trade-off for pruning-based trackers, pruning 65.4% of vision tokens in RGB-based tracking and 67.5% in unified tracking while preserving 99.7% and 100.5% of baseline performance, respectively. This strong performance across both RGB and multimodal scenarios underlines its potential as a robust foundation for future research in efficient visual tracking. Code will be released at https://github.com/EIT-NLP/UTPTrack.
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Apr 12, 2024



Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as \textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($\textbf{18\%}$, $\textbf{40\%}$ and $\textbf{3\%}$ success gains) in KITTI, NuScenes, and Waymo while runing at \textbf{52.6fps} with few parameters (\textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.
From Two-Stream to One-Stream: Efficient RGB-T Tracking via Mutual Prompt Learning and Knowledge Distillation
Apr 07, 2024Due to the complementary nature of visible light and thermal infrared modalities, object tracking based on the fusion of visible light images and thermal images (referred to as RGB-T tracking) has received increasing attention from researchers in recent years. How to achieve more comprehensive fusion of information from the two modalities at a lower cost has been an issue that researchers have been exploring. Inspired by visual prompt learning, we designed a novel two-stream RGB-T tracking architecture based on cross-modal mutual prompt learning, and used this model as a teacher to guide a one-stream student model for rapid learning through knowledge distillation techniques. Extensive experiments have shown that, compared to similar RGB-T trackers, our designed teacher model achieved the highest precision rate, while the student model, with comparable precision rate to the teacher model, realized an inference speed more than three times faster than the teacher model.(Codes will be available if accepted.)
OS-FPI: A Coarse-to-Fine One-Stream Network for UAV Geo-Localization
Mar 10, 2024The geo-localization and navigation technology of unmanned aerial vehicles (UAVs) in denied environments is currently a prominent research area. Prior approaches mainly employed a two-stream network with non-shared weights to extract features from UAV and satellite images separately, followed by related modeling to obtain the response map. However, the two-stream network extracts UAV and satellite features independently. This approach significantly affects the efficiency of feature extraction and increases the computational load. To address these issues, we propose a novel coarse-to-fine one-stream network (OS-FPI). Our approach allows information exchange between UAV and satellite features during early image feature extraction. To improve the model's performance, the framework retains feature maps generated at different stages of the feature extraction process for the feature fusion network, and establishes additional connections between UAV and satellite feature maps in the feature fusion network. Additionally, the framework introduces offset prediction to further refine and optimize the model's prediction results based on the classification tasks. Our proposed model, boasts a similar inference speed to FPI while significantly reducing the number of parameters. It can achieve better performance with fewer parameters under the same conditions. Moreover, it achieves state-of-the-art performance on the UL14 dataset. Compared to previous models, our model achieved a significant 10.92-point improvement on the RDS metric, reaching 76.25. Furthermore, its performance in meter-level localization accuracy is impressive, with 182.62% improvement in 3-meter accuracy, 164.17% improvement in 5-meter accuracy, and 137.43% improvement in 10-meter accuracy.
Optimized Information Flow for Transformer Tracking
Feb 13, 2024



One-stream Transformer trackers have shown outstanding performance in challenging benchmark datasets over the last three years, as they enable interaction between the target template and search region tokens to extract target-oriented features with mutual guidance. Previous approaches allow free bidirectional information flow between template and search tokens without investigating their influence on the tracker's discriminative capability. In this study, we conducted a detailed study on the information flow of the tokens and based on the findings, we propose a novel Optimized Information Flow Tracking (OIFTrack) framework to enhance the discriminative capability of the tracker. The proposed OIFTrack blocks the interaction from all search tokens to target template tokens in early encoder layers, as the large number of non-target tokens in the search region diminishes the importance of target-specific features. In the deeper encoder layers of the proposed tracker, search tokens are partitioned into target search tokens and non-target search tokens, allowing bidirectional flow from target search tokens to template tokens to capture the appearance changes of the target. In addition, since the proposed tracker incorporates dynamic background cues, distractor objects are successfully avoided by capturing the surrounding information of the target. The OIFTrack demonstrated outstanding performance in challenging benchmarks, particularly excelling in the one-shot tracking benchmark GOT-10k, achieving an average overlap of 74.6\%. The code, models, and results of this work are available at \url{https://github.com/JananiKugaa/OIFTrack}
Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers
Jul 09, 2023This paper addresses the problem of cross-modal object tracking from RGB videos and event data. Rather than constructing a complex cross-modal fusion network, we explore the great potential of a pre-trained vision Transformer (ViT). Particularly, we delicately investigate plug-and-play training augmentations that encourage the ViT to bridge the vast distribution gap between the two modalities, enabling comprehensive cross-modal information interaction and thus enhancing its ability. Specifically, we propose a mask modeling strategy that randomly masks a specific modality of some tokens to enforce the interaction between tokens from different modalities interacting proactively. To mitigate network oscillations resulting from the masking strategy and further amplify its positive effect, we then theoretically propose an orthogonal high-rank loss to regularize the attention matrix. Extensive experiments demonstrate that our plug-and-play training augmentation techniques can significantly boost state-of-the-art one-stream and twostream trackers to a large extent in terms of both tracking precision and success rate. Our new perspective and findings will potentially bring insights to the field of leveraging powerful pre-trained ViTs to model cross-modal data. The code will be publicly available.
Generalized Relation Modeling for Transformer Tracking
Apr 21, 2023



Compared with previous two-stream trackers, the recent one-stream tracking pipeline, which allows earlier interaction between the template and search region, has achieved a remarkable performance gain. However, existing one-stream trackers always let the template interact with all parts inside the search region throughout all the encoder layers. This could potentially lead to target-background confusion when the extracted feature representations are not sufficiently discriminative. To alleviate this issue, we propose a generalized relation modeling method based on adaptive token division. The proposed method is a generalized formulation of attention-based relation modeling for Transformer tracking, which inherits the merits of both previous two-stream and one-stream pipelines whilst enabling more flexible relation modeling by selecting appropriate search tokens to interact with template tokens. An attention masking strategy and the Gumbel-Softmax technique are introduced to facilitate the parallel computation and end-to-end learning of the token division module. Extensive experiments show that our method is superior to the two-stream and one-stream pipelines and achieves state-of-the-art performance on six challenging benchmarks with a real-time running speed.
OST: Efficient One-stream Network for 3D Single Object Tracking in Point Clouds
Oct 16, 2022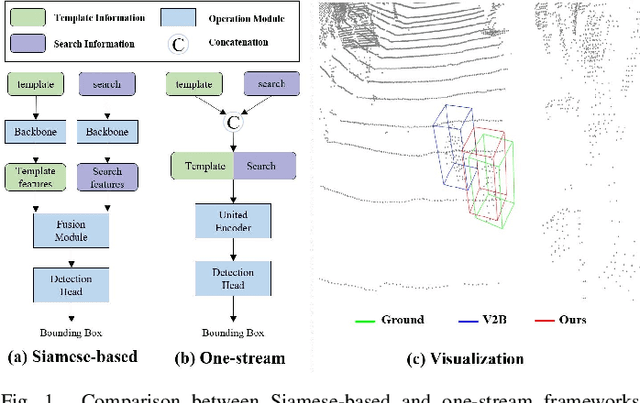
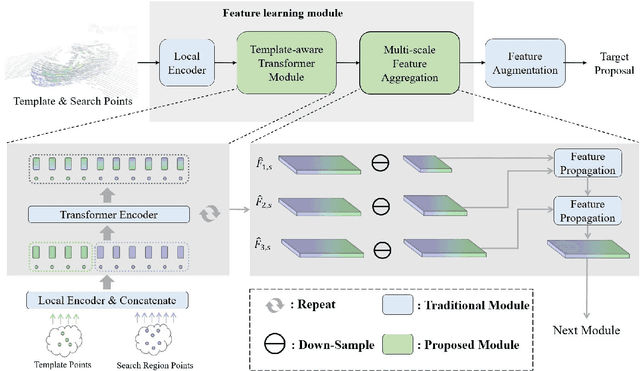
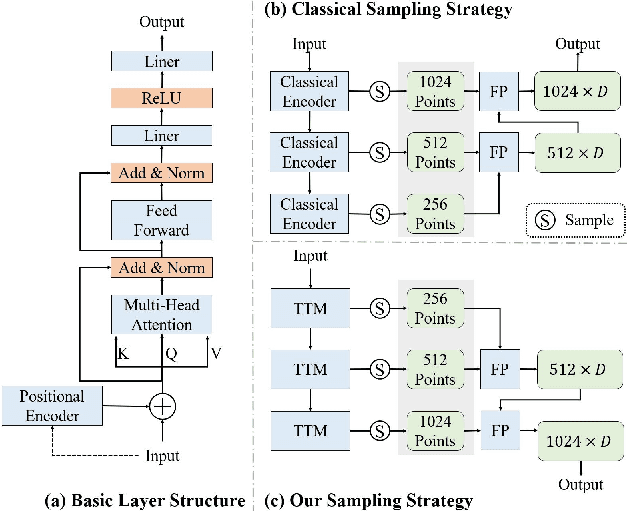
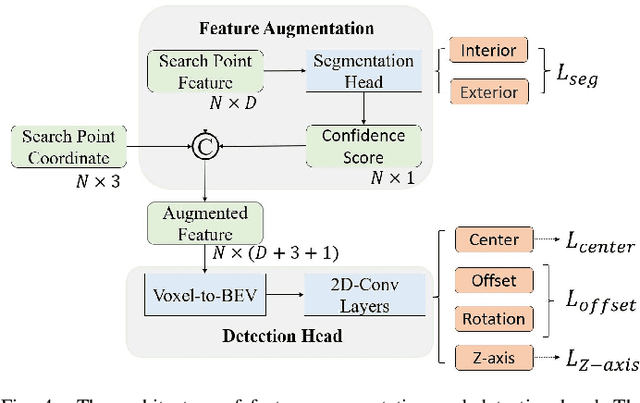
Although recent Siamese network-based trackers have achieved impressive perceptual accuracy for single object tracking in LiDAR point clouds, they advance with some heavy correlation operations on relation modeling and overlook the inherent merit of arbitrariness compared to multiple object tracking. In this work, we propose a radically novel one-stream network with the strength of the Transformer encoding, which avoids the correlation operations occurring in previous Siamese network, thus considerably reducing the computational effort. In particular, the proposed method mainly consists of a Template-aware Transformer Module (TTM) and a Multi-scale Feature Aggregation (MFA) module capable of fusing spatial and semantic information. The TTM stitches the specified template and the search region together and leverages an attention mechanism to establish the information flow, breaking the previous pattern of independent \textit{extraction-and-correlation}. As a result, this module makes it possible to directly generate template-aware features that are suitable for the arbitrary and continuously changing nature of the target, enabling the model to deal with unseen categories. In addition, the MFA is proposed to make spatial and semantic information complementary to each other, which is characterized by reverse directional feature propagation that aggregates information from shallow to deep layers. Extensive experiments on KITTI and nuScenes demonstrate that our method has achieved considerable performance not only for class-specific tracking but also for class-agnostic tracking with less computation and higher efficiency.
T-Person-GAN: Text-to-Person Image Generation with Identity-Consistency and Manifold Mix-Up
Aug 18, 2022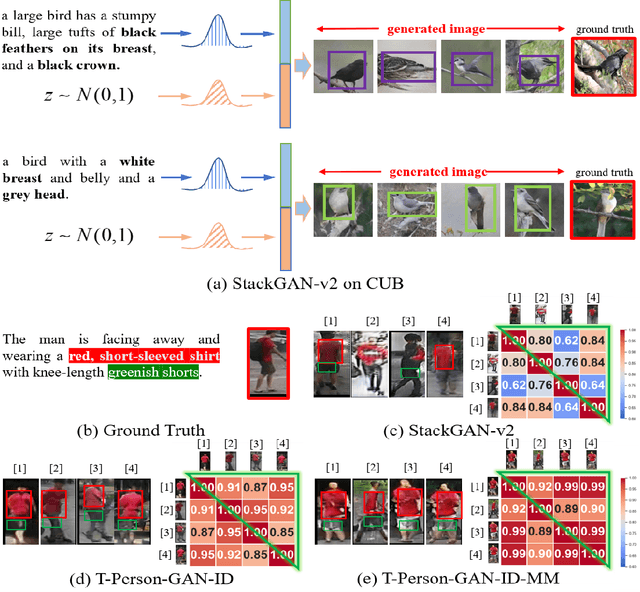
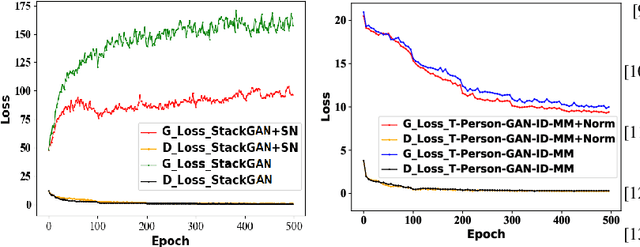
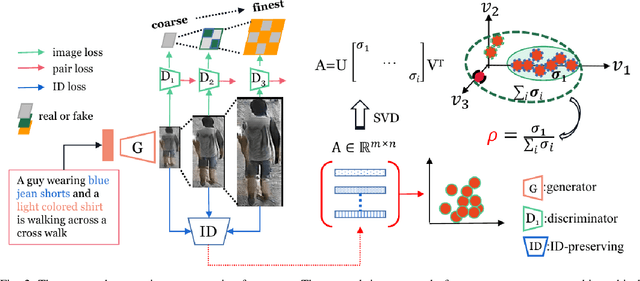
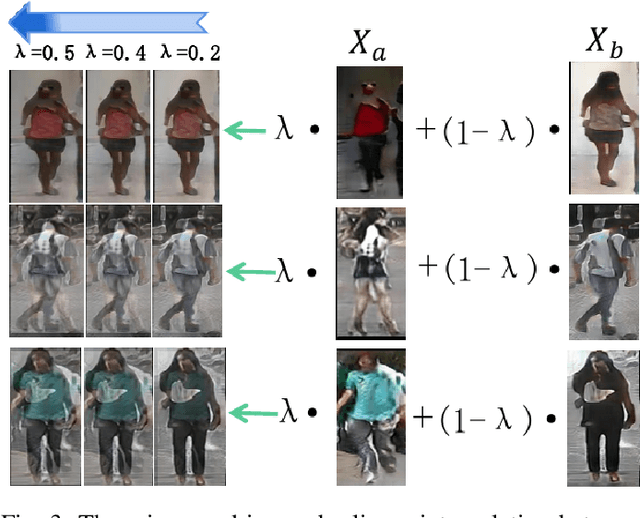
In this paper, we present an end-to-end approach to generate high-resolution person images conditioned on texts only. State-of-the-art text-to-image generation models are mainly designed for center-object generation, e.g., flowers and birds. Unlike center-placed objects with similar shapes and orientation, person image generation is a more challenging task, for which we observe the followings: 1) the generated images for the same person exhibit visual details with identity-consistency, e.g., identity-related textures/clothes/shoes across the images, and 2) those images should be discriminant for being robust against the inter-person variations caused by visual ambiguities. To address the above challenges, we develop an effective generative model to produce person images with two novel mechanisms. In particular, our first mechanism (called T-Person-GAN-ID) is to integrate the one-stream generator with an identity-preserving network such that the representations of generated data are regularized in their feature space to ensure the identity-consistency. The second mechanism (called T-Person-GAN-ID-MM) is based on the manifold mix-up to produce mixed images via the linear interpolation across generated images from different manifold identities, and we further enforce such interpolated images to be linearly classified in the feature space. This amounts to learning a linear classification boundary that can perfectly separate images from two identities. Our proposed method is empirically validated to achieve a remarkable improvement in text-to-person image generation. Our architecture is orthogonal to StackGAN++ , and focuses on person image generation, with all of them together to enrich the spectrum of GANs for the image generation task. Codes are available on \url{https://github.com/linwu-github/Person-Image-Generation.git}.