 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Global Replanning: Hierarchical Recovery for Cross-Device Agent Systems
Jun 18, 2026Real-world computer-use tasks often span multiple applications and devices, requiring agents to coordinate heterogeneous environments under dynamic runtime failures. Existing multi-device agent systems support task decomposition and cross-device assignment, but recovery remains largely coarse-grained: when execution fails, they typically retry the same strategy, reassign the subtask, or revise the global plan, without systematically modeling the device-local strategy space. This limits their ability to distinguish failures that can be repaired within the current device from those that require cross-device replanning. We propose \textbf{H-RePlan}, a hierarchical replanning framework for multi-device agents with unified API--CLI--GUI execution. H-RePlan equips each device with interchangeable execution strategies and separates device-local strategy recovery from orchestrator-level global replanning through a compact cross-layer failure abstraction. To evaluate this capability, we introduce \textbf{HeraBench}, a fault-injected benchmark that constructs cross-device workflows over Linux and Android devices and injects strategy- and device-level failures. Experiments show that H-RePlan substantially outperforms single-strategy and coarse-grained multi-device baselines, achieving higher completion, instruction adherence, and perfect-pass rates while reducing the token cost required for reliable end-to-end success. These results demonstrate that scope-aware hierarchical recovery is essential for robust multi-device agent execution.
Beyond Consistency: Preserving Temporal Structure in Zero-Shot Video Editing
Jun 07, 2026Existing zero-shot video editing methods rely on pre-trained diffusion models, successfully achieving spatial control and basic temporal consistency but fundamentally fail to preserve the video's original temporal structure.This distinction is critical: temporal consistency ensures visual smoothness, but temporal structure dictates the video's high-level narrative, rhythm, and semantic flow. Without this preservation, the edited output, especially for long videos with complex semantic variations, becomes narratively incoherent and semantically ambiguous. To address this limitation, we introduce a novel zero-shot editing approach that, for the first time, explicitly focuses on preserving the source video's temporal structure. We achieve this by adaptively partitioning the video into semantically distinct clips based on feature similarity and selecting a representative anchor frame for each clip. To enhance both intra-clip fidelity and computational efficiency, we design a clip-adaptive token merging strategy which leverages the anchor's semantic dominance to stabilize the editing. Furthermore, we employ an alternating combination strategy that ensures seamless inter-clip transitions while maintaining semantic distinction. Extensive experiments demonstrate that our method achieves state-of-the-art results, successfully balancing the preservation of original temporal structure with computational efficiency, and setting a new benchmark for zero-shot video editing fidelity.
ChartAct: A Benchmark for Dynamic Chart Understanding
May 28, 2026Charts are widely used to present complex data for analysis and decision making. Existing chart understanding benchmarks mainly focus on static charts, but real-world charts are often dynamic and interactive. Key information may only appear after actions such as hovering, clicking, zooming, or dragging. Dynamic chart understanding therefore requires models to identify visible content, choose proper interactions, and reason over changing chart states. To evaluate this ability, we propose ChartAct, an interactive benchmark for dynamic chart understanding. ChartAct collects and filters 673 dynamic charts from 8 real chart websites, covers 7 common chart types, and constructs 1,440 high-quality question-answer samples. Each sample is instantiated in two environments, Dynamic Chart and Dashboard Chart, to evaluate dynamic chart understanding under different contexts. Based on ChartAct, we systematically evaluate 11 advanced multimodal models and GUI agents. Experimental results show that existing models still have clear limitations in dynamic chart understanding. The strongest model, Claude-Opus-4.7, achieves an average success rate of 84.5\%, while most models remain below 60\%. We also conduct detailed failure attribution and case analysis. ChartAct provides a new benchmark for studying chart understanding in real interactive environments. Codes at https://github.com/wulin-wulin/OSWorld_Chart
PRISM: A Benchmark for Programmatic Spatial-Temporal Reasoning
May 19, 2026Programmatic video generation through code offers geometric precision and temporal coherence beyond pixel-level diffusion models, yet rigorously evaluating whether language models can produce spatially correct animated outputs remains an open problem. We introduce PRISM, a large-scale benchmark of 10,372 human-calibrated instruction-code pairs (20 times larger than prior programmatic video generation benchmarks), grounded in real-world knowledge visualization scenarios across English and Chinese and spanning 437 subject categories. We further propose a funnel-style evaluation framework with four complementary metrics: Code-Level Reliability for executability, Spatial Reasoning for layout correctness over full animation sequences, and Prompt-Aware Dynamic Visual Complexity (PADVC) and Temporal Density (TD) for diagnosing dynamic expression and temporal activity. Systematic evaluation of seven mainstream LLMs reveals a striking Execution-Spatial Gap: the average drop from execution success rate to spatial pass rate is approximately 41%, showing that runnable code does not necessarily yield spatially coherent visual output. These findings show that programmatic video generation evaluation should go beyond executability. PRISM provides a principled benchmark for advancing spatially coherent code generation.
Plug-and-play Class-aware Knowledge Injection for Prompt Learning with Visual-Language Model
May 07, 2026Prompt learning has become an effective and widely used technique in enhancing vision-language models (VLMs) such as CLIP for various downstream tasks, particularly in zero-shot classification within specific domains. Existing methods typically focus on either learning class-shared prompts for a given domain or generating instance-specific prompts through conditional prompt learning. While these methods have achieved promising performance, they often overlook class-specific knowledge in prompt design, leading to suboptimal outcomes. The underlying reasons are: 1) class-specific prompts offer more fine-grained supervision compared to coarse class-shared prompts, which helps prevent misclassification of data from different classes into a single class; 2) compared to class-specific prompts, instance-specific prompts neglect the richer class-level information across multiple instances, potentially causing data from the same class to be divided into multiple classes. To effectively supplement the class-specific knowledge into existing methods, we propose a plug-and-play Class-Aware Knowledge Injection (CAKI) framework. CAKI comprises two key components, i.e., class-specific prompt generation and query-key prompt matching. The former encodes class-specific knowledge into prompts from few-shot samples that belong to the same class and stores the learned prompts in a class-level knowledge bank. The latter provides a plug-and-play mechanism for each test instance to retrieve relevant class-level knowledge from the knowledge bank and inject such knowledge to refine model predictions. Extensive experiments demonstrate that our CAKI effectively improves the performance of existing methods on base and novel classes. Code is publicly available at \href{https://github.com/yjh576/CAKI}{this https URL}.
ESIA: An Energy-Based Spatiotemporal Interaction-Aware Framework for Pedestrian Intention Prediction
Apr 26, 2026Recent advances in autonomous driving have motivated research on pedestrian intention prediction, which aims to infer future crossing decisions and actions by modeling temporal dynamics, social interactions, and environmental context. However, existing studies remain constrained by oversimplified multi-agent interaction patterns, opaque reasoning logic, and a lack of global consistency in behavioral predictions, which compromise both robustness and interpretability. In this work, we propose ESIA (Energy-based Spatiotemporal Interaction-Aware framework), a novel Conditional Random Field (CRF)-based paradigm. We cast the intention prediction task as a structured prediction problem over a unified graph-based representation, treating pedestrians and the environment as spatiotemporal nodes. To characterize their distinct roles, we assign unary potentials to nodes to capture individual intentions, and pairwise potentials to edges to encode social and environmental interactions. These potentials are integrated into a unified global energy function to ensure scene-level consistency across behavioral predictions. To further constrain inference without ground-truth supervision, we introduce structural consistency terms to penalize logical contradictions. This optimization is efficiently solved via a novel Unary-Seeded Simulated Annealing (U-SSA) algorithm, which leverages high-confidence unary priors to rapidly converge to a high-quality solution. Extensive experiments on standard benchmarks demonstrate that ESIA achieves state-of-the-art performance with improved interpretability over existing methods.
Personalized Cell Segmentation: Benchmark and Framework for Reference-Guided Cell Type Segmentation
Mar 15, 2026Accurate cell segmentation is critical for biological and medical imaging studies. Although recent deep learning models have advanced this task, most methods are limited to generic cell segmentation, lacking the ability to differentiate specific cell types. In this work, we introduce the Personalized Cell Segmentation (PerCS) task, which aims to segment all cells of a specific type given a reference cell. To support this task, we establish a benchmark by reorganizing publicly available datasets, yielding 1,372 images and over 110,000 annotated cells. As a pioneering solution, we propose PerCS-DINO, a framework built on the DINOv2 backbone. By integrating image features and reference embeddings via a cross-attention transformer and contrastive learning, PerCS-DINO effectively segments cells matching the reference. Extensive experiments demonstrate the effectiveness of the proposed PerCS-DINO and highlight the challenges of this new task. We expect PerCS to serve as a useful testbed for advancing research in cell-based applications.
Towards a Science of Collective AI: LLM-based Multi-Agent Systems Need a Transition from Blind Trial-and-Error to Rigorous Science
Feb 05, 2026Recent advancements in Large Language Models (LLMs) have greatly extended the capabilities of Multi-Agent Systems (MAS), demonstrating significant effectiveness across a wide range of complex and open-ended domains. However, despite this rapid progress, the field still relies heavily on empirical trial-and-error. It lacks a unified and principled scientific framework necessary for systematic optimization and improvement. This bottleneck stems from the ambiguity of attribution: first, the absence of a structured taxonomy of factors leaves researchers restricted to unguided adjustments; second, the lack of a unified metric fails to distinguish genuine collaboration gain from mere resource accumulation. In this paper, we advocate for a transition to design science through an integrated framework. We advocate to establish the collaboration gain metric ($Γ$) as the scientific standard to isolate intrinsic gains from increased budgets. Leveraging $Γ$, we propose a factor attribution paradigm to systematically identify collaboration-driving factors. To support this, we construct a systematic MAS factor library, structuring the design space into control-level presets and information-level dynamics. Ultimately, this framework facilitates the transition from blind experimentation to rigorous science, paving the way towards a true science of Collective AI.
SegMo: Segment-aligned Text to 3D Human Motion Generation
Dec 24, 2025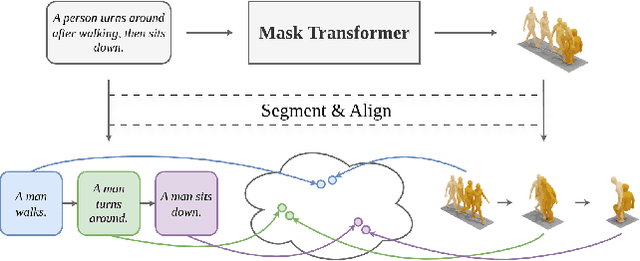
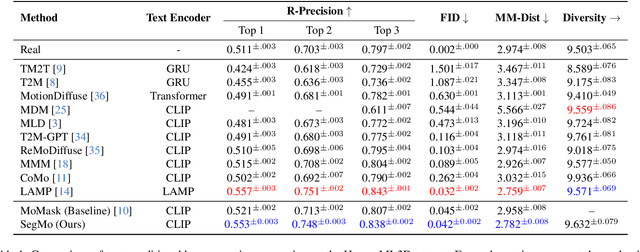
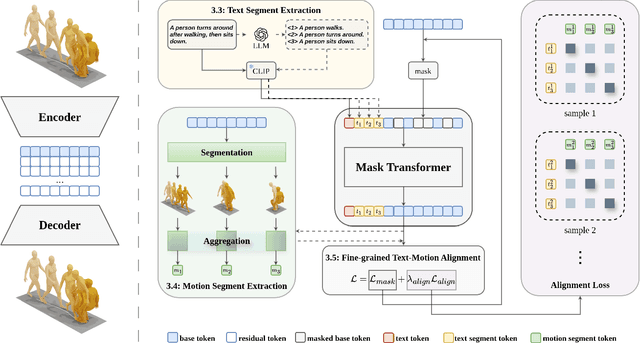
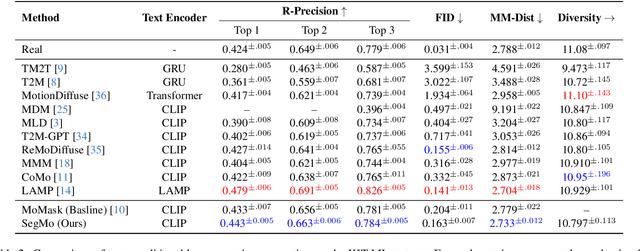
Generating 3D human motions from textual descriptions is an important research problem with broad applications in video games, virtual reality, and augmented reality. Recent methods align the textual description with human motion at the sequence level, neglecting the internal semantic structure of modalities. However, both motion descriptions and motion sequences can be naturally decomposed into smaller and semantically coherent segments, which can serve as atomic alignment units to achieve finer-grained correspondence. Motivated by this, we propose SegMo, a novel Segment-aligned text-conditioned human Motion generation framework to achieve fine-grained text-motion alignment. Our framework consists of three modules: (1) Text Segment Extraction, which decomposes complex textual descriptions into temporally ordered phrases, each representing a simple atomic action; (2) Motion Segment Extraction, which partitions complete motion sequences into corresponding motion segments; and (3) Fine-grained Text-Motion Alignment, which aligns text and motion segments with contrastive learning. Extensive experiments demonstrate that SegMo improves the strong baseline on two widely used datasets, achieving an improved TOP 1 score of 0.553 on the HumanML3D test set. Moreover, thanks to the learned shared embedding space for text and motion segments, SegMo can also be applied to retrieval-style tasks such as motion grounding and motion-to-text retrieval.
PrefPoE: Advantage-Guided Preference Fusion for Learning Where to Explore
Nov 11, 2025Exploration in reinforcement learning remains a critical challenge, as naive entropy maximization often results in high variance and inefficient policy updates. We introduce \textbf{PrefPoE}, a novel \textit{Preference-Product-of-Experts} framework that performs intelligent, advantage-guided exploration via the first principled application of product-of-experts (PoE) fusion for single-task exploration-exploitation balancing. By training a preference network to concentrate probability mass on high-advantage actions and fusing it with the main policy through PoE, PrefPoE creates a \textbf{soft trust region} that stabilizes policy updates while maintaining targeted exploration. Across diverse control tasks spanning both continuous and discrete action spaces, PrefPoE demonstrates consistent improvements: +321\% on HalfCheetah-v4 (1276~$\rightarrow$~5375), +69\% on Ant-v4, +276\% on LunarLander-v2, with consistently enhanced training stability and sample efficiency. Unlike standard PPO, which suffers from entropy collapse, PrefPoE sustains adaptive exploration through its unique dynamics, thereby preventing premature convergence and enabling superior performance. Our results establish that learning \textit{where to explore} through advantage-guided preferences is as crucial as learning how to act, offering a general framework for enhancing policy gradient methods across the full spectrum of reinforcement learning domains. Code and pretrained models are available in supplementary materials.