 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Paragraph Captioning
Image-paragraph captioning is the process of generating descriptive paragraphs for images that contain multiple objects or scenes.
Papers and Code
Unblocking Fine-Grained Evaluation of Detailed Captions: An Explaining AutoRater and Critic-and-Revise Pipeline
Jun 09, 2025Large Vision-Language Models (VLMs) now generate highly detailed, paragraphlength image captions, yet evaluating their factual accuracy remains challenging. Current methods often miss fine-grained errors, being designed for shorter texts or lacking datasets with verified inaccuracies. We introduce DOCCI-Critique, a benchmark with 1,400 VLM-generated paragraph captions (100 images, 14 VLMs) featuring over 10,216 sentence-level human annotations of factual correctness and explanatory rationales for errors, all within paragraph context. Building on this, we develop VNLI-Critique, a model for automated sentence-level factuality classification and critique generation. We highlight three key applications: (1) VNLI-Critique demonstrates robust generalization, validated by state-of-the-art performance on the M-HalDetect benchmark and strong results in CHOCOLATE claim verification. (2) The VNLI-Critique driven AutoRater for DOCCI-Critique provides reliable VLM rankings, showing excellent alignment with human factuality judgments (e.g., 0.98 Spearman). (3) An innovative Critic-and-Revise pipeline, where critiques from VNLI-Critique guide LLM-based corrections, achieves substantial improvements in caption factuality (e.g., a 46% gain on DetailCaps-4870). Our work offers a crucial benchmark alongside practical tools, designed to significantly elevate the standards for fine-grained evaluation and foster the improvement of VLM image understanding. Project page: https://google.github.io/unblocking-detail-caption
LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
ViCrit: A Verifiable Reinforcement Learning Proxy Task for Visual Perception in VLMs
Jun 11, 2025Reinforcement learning (RL) has shown great effectiveness for fine-tuning large language models (LLMs) using tasks that are challenging yet easily verifiable, such as math reasoning or code generation. However, extending this success to visual perception in vision-language models (VLMs) has been impeded by the scarcity of vision-centric tasks that are simultaneously challenging and unambiguously verifiable. To this end, we introduce ViCrit (Visual Caption Hallucination Critic), an RL proxy task that trains VLMs to localize a subtle, synthetic visual hallucination injected into paragraphs of human-written image captions. Starting from a 200-word captions, we inject a single, subtle visual description error-altering a few words on objects, attributes, counts, or spatial relations-and task the model to pinpoint the corrupted span given the image and the modified caption. This formulation preserves the full perceptual difficulty while providing a binary, exact-match reward that is easy to compute and unambiguous. Models trained with the ViCrit Task exhibit substantial gains across a variety of VL benchmarks. Crucially, the improvements transfer beyond natural-image training data to abstract image reasoning and visual math, showing promises of learning to perceive rather than barely memorizing seen objects. To facilitate evaluation, we further introduce ViCrit-Bench, a category-balanced diagnostic benchmark that systematically probes perception errors across diverse image domains and error types. Together, our results demonstrate that fine-grained hallucination criticism is an effective and generalizable objective for enhancing visual perception in VLMs.
VLIS: Unimodal Language Models Guide Multimodal Language Generation
Oct 15, 2023



Multimodal language generation, which leverages the synergy of language and vision, is a rapidly expanding field. However, existing vision-language models face challenges in tasks that require complex linguistic understanding. To address this issue, we introduce Visual-Language models as Importance Sampling weights (VLIS), a novel framework that combines the visual conditioning capability of vision-language models with the language understanding of unimodal text-only language models without further training. It extracts pointwise mutual information of each image and text from a visual-language model and uses the value as an importance sampling weight to adjust the token likelihood from a text-only model. VLIS improves vision-language models on diverse tasks, including commonsense understanding (WHOOPS, OK-VQA, and ScienceQA) and complex text generation (Concadia, Image Paragraph Captioning, and ROCStories). Our results suggest that VLIS represents a promising new direction for multimodal language generation.
Enhancing image captioning with depth information using a Transformer-based framework
Jul 24, 2023Captioning images is a challenging scene-understanding task that connects computer vision and natural language processing. While image captioning models have been successful in producing excellent descriptions, the field has primarily focused on generating a single sentence for 2D images. This paper investigates whether integrating depth information with RGB images can enhance the captioning task and generate better descriptions. For this purpose, we propose a Transformer-based encoder-decoder framework for generating a multi-sentence description of a 3D scene. The RGB image and its corresponding depth map are provided as inputs to our framework, which combines them to produce a better understanding of the input scene. Depth maps could be ground truth or estimated, which makes our framework widely applicable to any RGB captioning dataset. We explored different fusion approaches to fuse RGB and depth images. The experiments are performed on the NYU-v2 dataset and the Stanford image paragraph captioning dataset. During our work with the NYU-v2 dataset, we found inconsistent labeling that prevents the benefit of using depth information to enhance the captioning task. The results were even worse than using RGB images only. As a result, we propose a cleaned version of the NYU-v2 dataset that is more consistent and informative. Our results on both datasets demonstrate that the proposed framework effectively benefits from depth information, whether it is ground truth or estimated, and generates better captions. Code, pre-trained models, and the cleaned version of the NYU-v2 dataset will be made publically available.
mPLUG-PaperOwl: Scientific Diagram Analysis with the Multimodal Large Language Model
Nov 30, 2023



Recently, the strong text creation ability of Large Language Models(LLMs) has given rise to many tools for assisting paper reading or even writing. However, the weak diagram analysis abilities of LLMs or Multimodal LLMs greatly limit their application scenarios, especially for scientific academic paper writing. In this work, towards a more versatile copilot for academic paper writing, we mainly focus on strengthening the multi-modal diagram analysis ability of Multimodal LLMs. By parsing Latex source files of high-quality papers, we carefully build a multi-modal diagram understanding dataset M-Paper. By aligning diagrams in the paper with related paragraphs, we construct professional diagram analysis samples for training and evaluation. M-Paper is the first dataset to support joint comprehension of multiple scientific diagrams, including figures and tables in the format of images or Latex codes. Besides, to better align the copilot with the user's intention, we introduce the `outline' as the control signal, which could be directly given by the user or revised based on auto-generated ones. Comprehensive experiments with a state-of-the-art Mumtimodal LLM demonstrate that training on our dataset shows stronger scientific diagram understanding performance, including diagram captioning, diagram analysis, and outline recommendation. The dataset, code, and model are available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/PaperOwl.
SciCap+: A Knowledge Augmented Dataset to Study the Challenges of Scientific Figure Captioning
Jun 06, 2023



In scholarly documents, figures provide a straightforward way of communicating scientific findings to readers. Automating figure caption generation helps move model understandings of scientific documents beyond text and will help authors write informative captions that facilitate communicating scientific findings. Unlike previous studies, we reframe scientific figure captioning as a knowledge-augmented image captioning task that models need to utilize knowledge embedded across modalities for caption generation. To this end, we extended the large-scale SciCap dataset~\cite{hsu-etal-2021-scicap-generating} to SciCap+ which includes mention-paragraphs (paragraphs mentioning figures) and OCR tokens. Then, we conduct experiments with the M4C-Captioner (a multimodal transformer-based model with a pointer network) as a baseline for our study. Our results indicate that mention-paragraphs serves as additional context knowledge, which significantly boosts the automatic standard image caption evaluation scores compared to the figure-only baselines. Human evaluations further reveal the challenges of generating figure captions that are informative to readers. The code and SciCap+ dataset will be publicly available at https://github.com/ZhishenYang/scientific_figure_captioning_dataset
KiUT: Knowledge-injected U-Transformer for Radiology Report Generation
Jun 20, 2023



Radiology report generation aims to automatically generate a clinically accurate and coherent paragraph from the X-ray image, which could relieve radiologists from the heavy burden of report writing. Although various image caption methods have shown remarkable performance in the natural image field, generating accurate reports for medical images requires knowledge of multiple modalities, including vision, language, and medical terminology. We propose a Knowledge-injected U-Transformer (KiUT) to learn multi-level visual representation and adaptively distill the information with contextual and clinical knowledge for word prediction. In detail, a U-connection schema between the encoder and decoder is designed to model interactions between different modalities. And a symptom graph and an injected knowledge distiller are developed to assist the report generation. Experimentally, we outperform state-of-the-art methods on two widely used benchmark datasets: IU-Xray and MIMIC-CXR. Further experimental results prove the advantages of our architecture and the complementary benefits of the injected knowledge.
Bypass Network for Semantics Driven Image Paragraph Captioning
Jun 21, 2022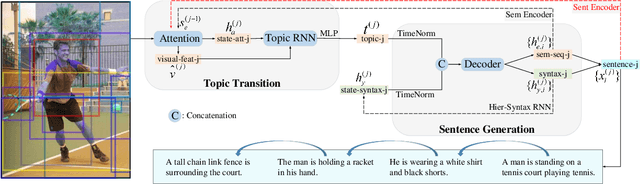

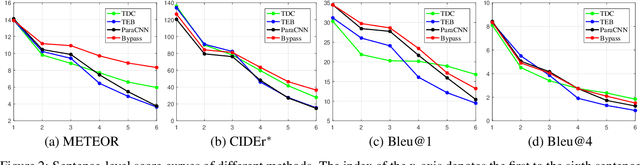
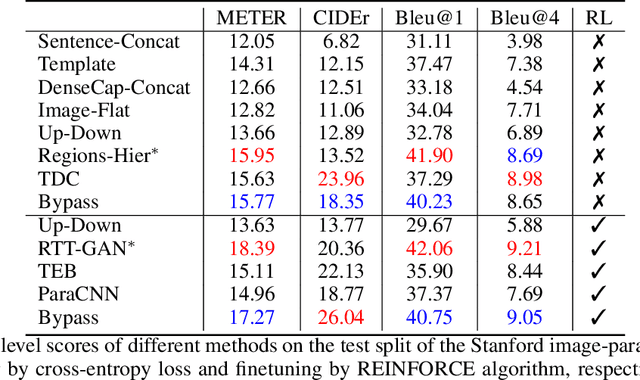
Image paragraph captioning aims to describe a given image with a sequence of coherent sentences. Most existing methods model the coherence through the topic transition that dynamically infers a topic vector from preceding sentences. However, these methods still suffer from immediate or delayed repetitions in generated paragraphs because (i) the entanglement of syntax and semantics distracts the topic vector from attending pertinent visual regions; (ii) there are few constraints or rewards for learning long-range transitions. In this paper, we propose a bypass network that separately models semantics and linguistic syntax of preceding sentences. Specifically, the proposed model consists of two main modules, i.e. a topic transition module and a sentence generation module. The former takes previous semantic vectors as queries and applies attention mechanism on regional features to acquire the next topic vector, which reduces immediate repetition by eliminating linguistics. The latter decodes the topic vector and the preceding syntax state to produce the following sentence. To further reduce delayed repetition in generated paragraphs, we devise a replacement-based reward for the REINFORCE training. Comprehensive experiments on the widely used benchmark demonstrate the superiority of the proposed model over the state of the art for coherence while maintaining high accuracy.
Reading Radiology Imaging Like The Radiologist
Jul 20, 2023Automated radiology report generation aims to generate radiology reports that contain rich, fine-grained descriptions of radiology imaging. Compared with image captioning in the natural image domain, medical images are very similar to each other, with only minor differences in the occurrence of diseases. Given the importance of these minor differences in the radiology report, it is crucial to encourage the model to focus more on the subtle regions of disease occurrence. Secondly, the problem of visual and textual data biases is serious. Not only do normal cases make up the majority of the dataset, but sentences describing areas with pathological changes also constitute only a small part of the paragraph. Lastly, generating medical image reports involves the challenge of long text generation, which requires more expertise and empirical training in medical knowledge. As a result, the difficulty of generating such reports is increased. To address these challenges, we propose a disease-oriented retrieval framework that utilizes similar reports as prior knowledge references. We design a factual consistency captioning generator to generate more accurate and factually consistent disease descriptions. Our framework can find most similar reports for a given disease from the CXR database by retrieving a disease-oriented mask consisting of the position and morphological characteristics. By referencing the disease-oriented similar report and the visual features, the factual consistency model can generate a more accurate radiology report.