 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScripts Through Time: A Survey of the Evolving Role of Transliteration in NLP
Apr 20, 2026Cross-lingual transfer in NLP is often hindered by the ``script barrier'' where differences in writing systems inhibit transfer learning between languages. Transliteration, the process of converting the script, has emerged as a powerful technique to bridge this gap by increasing lexical overlap. This paper provides a comprehensive survey of the application of transliteration in cross-lingual NLP. We present a taxonomy of key motivations to utilize transliterations in language models, and provide an overview of different approaches of incorporating transliterations as input. We analyze the evolution and effectiveness of these methods, discussing the critical trade-offs involved, and contextualize their need in modern LLMs. The review explores various settings that show how transliteration is beneficial, including handling code-mixed text, leveraging language family relatedness, and pragmatic gains in inference efficiency. Based on this analysis, we provide concrete recommendations for researchers on selecting and implementing the most appropriate transliteration strategy based on their specific language, task, and resource constraints.
Top-b: Entropic Regulation of Relative Probability Bands in Autoregressive Language Processes
Mar 15, 2026Probabilistic language generators are theoretically modeled as discrete stochastic processes, yet standard decoding strategies (Top-k, Top-p) impose static truncation rules that fail to accommodate the dynamic information density of natural language. This misalignment often forces a suboptimal trade-off: static bounds are either too restrictive for high-entropy creative generation or too permissive for low-entropy logical reasoning. In this work, we formalize the generation process as a trajectory through a relative probability manifold. We introduce Top-b (Adaptive Relative Band Sampling), a decoding strategy that regulates the candidate set via a dynamic bandwidth coefficient coupled strictly to the instantaneous Shannon entropy of the model's distribution. We provide a theoretical framework demonstrating that Top-b acts as a variance-minimizing operator on the tail distribution. Empirical validation on GPQA and GSM8K benchmarks indicates that Top-b significantly reduces generation entropy and inter-decoding variance while maintaining competitive reasoning accuracy, effectively approximating a self-regulating control system for autoregressive generation.
IndicIFEval: A Benchmark for Verifiable Instruction-Following Evaluation in 14 Indic Languages
Feb 25, 2026Instruction-following benchmarks remain predominantly English-centric, leaving a critical evaluation gap for the hundreds of millions of Indic language speakers. We introduce IndicIFEval, a benchmark evaluating constrained generation of LLMs across 14 Indic languages using automatically verifiable, rule-based instructions. It comprises around 800 human-verified examples per language spread across two complementary subsets: IndicIFEval-Ground, translated prompts from IFEval (Zhou et al., 2023) carefully localized for Indic contexts, and IndicIFEval-Ground, synthetically generated instructions grounded in native Indic content. We conduct a comprehensive evaluation of major open-weight and proprietary models spanning both reasoning and non-reasoning models. While models maintain strong adherence to formatting constraints, they struggle significantly with lexical and cross-lingual tasks -- and despite progress in high-resource languages, instruction-following across the broader Indic family lags significantly behind English. We release IndicIFEval and its evaluation scripts to support progress on multilingual constrained generation (http://github.com/ai4bharat/IndicIFEval).
PrahokBART: A Pre-trained Sequence-to-Sequence Model for Khmer Natural Language Generation
Dec 15, 2025This work introduces {\it PrahokBART}, a compact pre-trained sequence-to-sequence model trained from scratch for Khmer using carefully curated Khmer and English corpora. We focus on improving the pre-training corpus quality and addressing the linguistic issues of Khmer, which are ignored in existing multilingual models, by incorporating linguistic components such as word segmentation and normalization. We evaluate PrahokBART on three generative tasks: machine translation, text summarization, and headline generation, where our results demonstrate that it outperforms mBART50, a strong multilingual pre-trained model. Additionally, our analysis provides insights into the impact of each linguistic module and evaluates how effectively our model handles space during text generation, which is crucial for the naturalness of texts in Khmer.
The Reasoning Lingua Franca: A Double-Edged Sword for Multilingual AI
Oct 23, 2025Large Reasoning Models (LRMs) achieve strong performance on mathematical, scientific, and other question-answering tasks, but their multilingual reasoning abilities remain underexplored. When presented with non-English questions, LRMs often default to reasoning in English, raising concerns about interpretability and the handling of linguistic and cultural nuances. We systematically compare an LRM's reasoning in English versus the language of the question. Our evaluation spans two tasks: MGSM and GPQA Diamond. Beyond measuring answer accuracy, we also analyze cognitive attributes in the reasoning traces. We find that English reasoning traces exhibit a substantially higher presence of these cognitive behaviors, and that reasoning in English generally yields higher final-answer accuracy, with the performance gap increasing as tasks become more complex. However, this English-centric strategy is susceptible to a key failure mode - getting "Lost in Translation," where translation steps lead to errors that would have been avoided by question's language reasoning.
Mark My Words: A Robust Multilingual Model for Punctuation in Text and Speech Transcripts
Jun 04, 2025



Punctuation plays a vital role in structuring meaning, yet current models often struggle to restore it accurately in transcripts of spontaneous speech, especially in the presence of disfluencies such as false starts and backtracking. These limitations hinder the performance of downstream tasks like translation, text to speech, summarization, etc. where sentence boundaries are critical for preserving quality. In this work, we introduce Cadence, a generalist punctuation restoration model adapted from a pretrained large language model. Cadence is designed to handle both clean written text and highly spontaneous spoken transcripts. It surpasses the previous state of the art in performance while expanding support from 14 to all 22 Indian languages and English. We conduct a comprehensive analysis of model behavior across punctuation types and language families, identifying persistent challenges under domain shift and with rare punctuation marks. Our findings demonstrate the efficacy of utilizing pretrained language models for multilingual punctuation restoration and highlight Cadence practical value for low resource NLP pipelines at scale.
Limited-Resource Adapters Are Regularizers, Not Linguists
May 30, 2025Cross-lingual transfer from related high-resource languages is a well-established strategy to enhance low-resource language technologies. Prior work has shown that adapters show promise for, e.g., improving low-resource machine translation (MT). In this work, we investigate an adapter souping method combined with cross-attention fine-tuning of a pre-trained MT model to leverage language transfer for three low-resource Creole languages, which exhibit relatedness to different language groups across distinct linguistic dimensions. Our approach improves performance substantially over baselines. However, we find that linguistic relatedness -- or even a lack thereof -- does not covary meaningfully with adapter performance. Surprisingly, our cross-attention fine-tuning approach appears equally effective with randomly initialized adapters, implying that the benefit of adapters in this setting lies in parameter regularization, and not in meaningful information transfer. We provide analysis supporting this regularization hypothesis. Our findings underscore the reality that neural language processing involves many success factors, and that not all neural methods leverage linguistic knowledge in intuitive ways.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
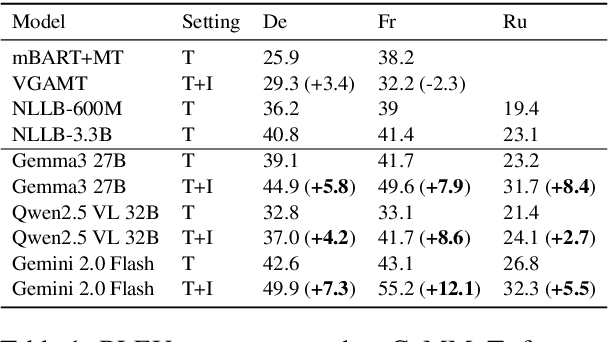

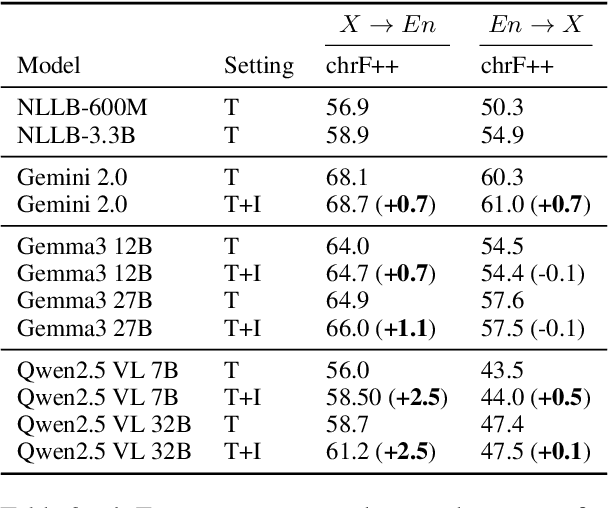
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
TikZero: Zero-Shot Text-Guided Graphics Program Synthesis
Mar 14, 2025



With the rise of generative AI, synthesizing figures from text captions becomes a compelling application. However, achieving high geometric precision and editability requires representing figures as graphics programs in languages like TikZ, and aligned training data (i.e., graphics programs with captions) remains scarce. Meanwhile, large amounts of unaligned graphics programs and captioned raster images are more readily available. We reconcile these disparate data sources by presenting TikZero, which decouples graphics program generation from text understanding by using image representations as an intermediary bridge. It enables independent training on graphics programs and captioned images and allows for zero-shot text-guided graphics program synthesis during inference. We show that our method substantially outperforms baselines that can only operate with caption-aligned graphics programs. Furthermore, when leveraging caption-aligned graphics programs as a complementary training signal, TikZero matches or exceeds the performance of much larger models, including commercial systems like GPT-4o. Our code, datasets, and select models are publicly available.
IteRABRe: Iterative Recovery-Aided Block Reduction
Mar 08, 2025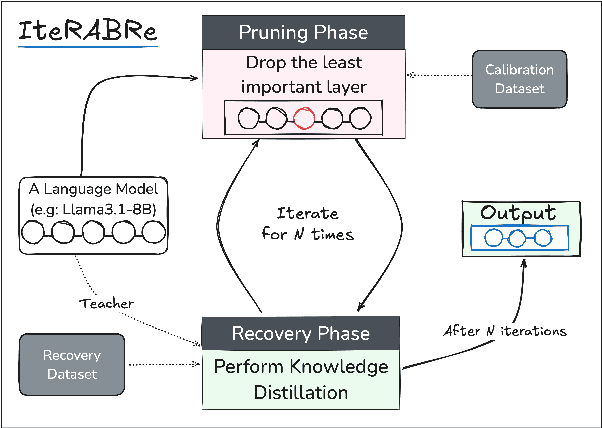
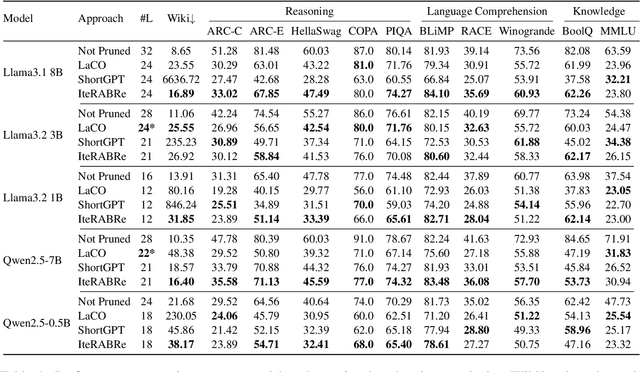
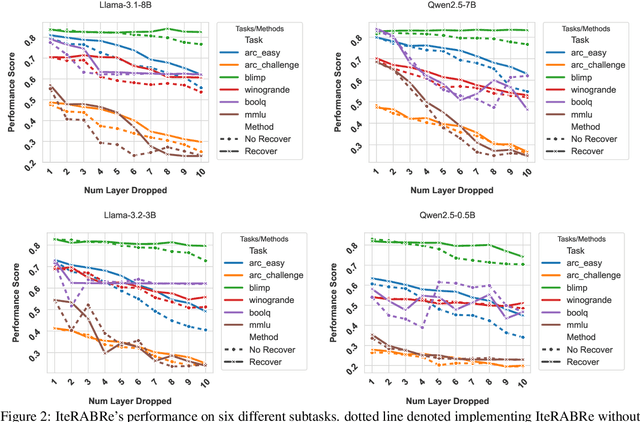
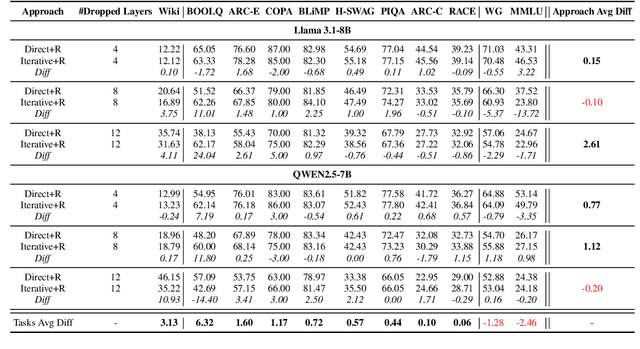
Large Language Models (LLMs) have grown increasingly expensive to deploy, driving the need for effective model compression techniques. While block pruning offers a straightforward approach to reducing model size, existing methods often struggle to maintain performance or require substantial computational resources for recovery. We present IteRABRe, a simple yet effective iterative pruning method that achieves superior compression results while requiring minimal computational resources. Using only 2.5M tokens for recovery, our method outperforms baseline approaches by ~3% on average when compressing the Llama3.1-8B and Qwen2.5-7B models. IteRABRe demonstrates particular strength in the preservation of linguistic capabilities, showing an improvement 5% over the baselines in language-related tasks. Our analysis reveals distinct pruning characteristics between these models, while also demonstrating preservation of multilingual capabilities.