 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-Language Models
Apr 02, 2026Developing vision-language models (VLMs) that generalize across diverse tasks requires large-scale training datasets with diverse content. In English, such datasets are typically constructed by aggregating and curating numerous existing visual question answering (VQA) resources. However, this strategy does not readily extend to other languages, where VQA datasets remain limited in both scale and domain coverage, posing a major obstacle to building high-quality multilingual and non-English VLMs. In this work, we introduce Jagle, the largest Japanese multimodal post-training dataset to date, comprising approximately 9.2 million instances across diverse tasks. Rather than relying on existing VQA datasets, we collect heterogeneous source data, including images, image-text pairs, and PDF documents, and generate VQA pairs through multiple strategies such as VLM-based QA generation, translation, and text rendering. Experiments demonstrate that a 2.2B model trained with Jagle achieves strong performance on Japanese tasks, surpassing InternVL3.5-2B in average score across ten Japanese evaluation tasks and approaching within five points of Qwen3-VL-2B-Instruct. Furthermore, combining Jagle with FineVision does not degrade English performance; instead, it improves English performance compared to training with FineVision alone. To facilitate reproducibility and future research, we release the dataset, trained models, and code.
SciCap+: A Knowledge Augmented Dataset to Study the Challenges of Scientific Figure Captioning
Jun 06, 2023



In scholarly documents, figures provide a straightforward way of communicating scientific findings to readers. Automating figure caption generation helps move model understandings of scientific documents beyond text and will help authors write informative captions that facilitate communicating scientific findings. Unlike previous studies, we reframe scientific figure captioning as a knowledge-augmented image captioning task that models need to utilize knowledge embedded across modalities for caption generation. To this end, we extended the large-scale SciCap dataset~\cite{hsu-etal-2021-scicap-generating} to SciCap+ which includes mention-paragraphs (paragraphs mentioning figures) and OCR tokens. Then, we conduct experiments with the M4C-Captioner (a multimodal transformer-based model with a pointer network) as a baseline for our study. Our results indicate that mention-paragraphs serves as additional context knowledge, which significantly boosts the automatic standard image caption evaluation scores compared to the figure-only baselines. Human evaluations further reveal the challenges of generating figure captions that are informative to readers. The code and SciCap+ dataset will be publicly available at https://github.com/ZhishenYang/scientific_figure_captioning_dataset
Keyframe Segmentation and Positional Encoding for Video-guided Machine Translation Challenge 2020
Jun 23, 2020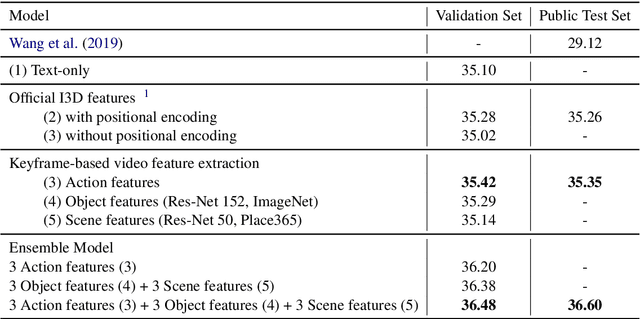

Video-guided machine translation as one of multimodal neural machine translation tasks targeting on generating high-quality text translation by tangibly engaging both video and text. In this work, we presented our video-guided machine translation system in approaching the Video-guided Machine Translation Challenge 2020. This system employs keyframe-based video feature extractions along with the video feature positional encoding. In the evaluation phase, our system scored 36.60 corpus-level BLEU-4 and achieved the 1st place on the Video-guided Machine Translation Challenge 2020.