 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-form Image Inpainting
Free-form image inpainting is the process of reconstructing missing regions in images using free-form masks or shapes.
Papers and Code
RETHINED: A New Benchmark and Baseline for Real-Time High-Resolution Image Inpainting On Edge Devices
Mar 18, 2025



Existing image inpainting methods have shown impressive completion results for low-resolution images. However, most of these algorithms fail at high resolutions and require powerful hardware, limiting their deployment on edge devices. Motivated by this, we propose the first baseline for REal-Time High-resolution image INpainting on Edge Devices (RETHINED) that is able to inpaint at ultra-high-resolution and can run in real-time ($\leq$ 30ms) in a wide variety of mobile devices. A simple, yet effective novel method formed by a lightweight Convolutional Neural Network (CNN) to recover structure, followed by a resolution-agnostic patch replacement mechanism to provide detailed texture. Specially our pipeline leverages the structural capacity of CNN and the high-level detail of patch-based methods, which is a key component for high-resolution image inpainting. To demonstrate the real application of our method, we conduct an extensive analysis on various mobile-friendly devices and demonstrate similar inpainting performance while being $\mathrm{100 \times faster}$ than existing state-of-the-art methods. Furthemore, we realease DF8K-Inpainting, the first free-form mask UHD inpainting dataset.
BrushEdit: All-In-One Image Inpainting and Editing
Dec 13, 2024



Image editing has advanced significantly with the development of diffusion models using both inversion-based and instruction-based methods. However, current inversion-based approaches struggle with big modifications (e.g., adding or removing objects) due to the structured nature of inversion noise, which hinders substantial changes. Meanwhile, instruction-based methods often constrain users to black-box operations, limiting direct interaction for specifying editing regions and intensity. To address these limitations, we propose BrushEdit, a novel inpainting-based instruction-guided image editing paradigm, which leverages multimodal large language models (MLLMs) and image inpainting models to enable autonomous, user-friendly, and interactive free-form instruction editing. Specifically, we devise a system enabling free-form instruction editing by integrating MLLMs and a dual-branch image inpainting model in an agent-cooperative framework to perform editing category classification, main object identification, mask acquisition, and editing area inpainting. Extensive experiments show that our framework effectively combines MLLMs and inpainting models, achieving superior performance across seven metrics including mask region preservation and editing effect coherence.
Emu Edit: Precise Image Editing via Recognition and Generation Tasks
Nov 16, 2023



Instruction-based image editing holds immense potential for a variety of applications, as it enables users to perform any editing operation using a natural language instruction. However, current models in this domain often struggle with accurately executing user instructions. We present Emu Edit, a multi-task image editing model which sets state-of-the-art results in instruction-based image editing. To develop Emu Edit we train it to multi-task across an unprecedented range of tasks, such as region-based editing, free-form editing, and Computer Vision tasks, all of which are formulated as generative tasks. Additionally, to enhance Emu Edit's multi-task learning abilities, we provide it with learned task embeddings which guide the generation process towards the correct edit type. Both these elements are essential for Emu Edit's outstanding performance. Furthermore, we show that Emu Edit can generalize to new tasks, such as image inpainting, super-resolution, and compositions of editing tasks, with just a few labeled examples. This capability offers a significant advantage in scenarios where high-quality samples are scarce. Lastly, to facilitate a more rigorous and informed assessment of instructable image editing models, we release a new challenging and versatile benchmark that includes seven different image editing tasks.
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Mar 23, 2023



This paper presents a new adversarial training framework for image inpainting with segmentation confusion adversarial training (SCAT) and contrastive learning. SCAT plays an adversarial game between an inpainting generator and a segmentation network, which provides pixel-level local training signals and can adapt to images with free-form holes. By combining SCAT with standard global adversarial training, the new adversarial training framework exhibits the following three advantages simultaneously: (1) the global consistency of the repaired image, (2) the local fine texture details of the repaired image, and (3) the flexibility of handling images with free-form holes. Moreover, we propose the textural and semantic contrastive learning losses to stabilize and improve our inpainting model's training by exploiting the feature representation space of the discriminator, in which the inpainting images are pulled closer to the ground truth images but pushed farther from the corrupted images. The proposed contrastive losses better guide the repaired images to move from the corrupted image data points to the real image data points in the feature representation space, resulting in more realistic completed images. We conduct extensive experiments on two benchmark datasets, demonstrating our model's effectiveness and superiority both qualitatively and quantitatively.
Towards Interactive Image Inpainting via Sketch Refinement
Jun 14, 2023



One tough problem of image inpainting is to restore complex structures in the corrupted regions. It motivates interactive image inpainting which leverages additional hints, e.g., sketches, to assist the inpainting process. Sketch is simple and intuitive to end users, but meanwhile has free forms with much randomness. Such randomness may confuse the inpainting models, and incur severe artifacts in completed images. To address this problem, we propose a two-stage image inpainting method termed SketchRefiner. In the first stage, we propose using a cross-correlation loss function to robustly calibrate and refine the user-provided sketches in a coarse-to-fine fashion. In the second stage, we learn to extract informative features from the abstracted sketches in the feature space and modulate the inpainting process. We also propose an algorithm to simulate real sketches automatically and build a test protocol with different applications. Experimental results on public datasets demonstrate that SketchRefiner effectively utilizes sketch information and eliminates the artifacts due to the free-form sketches. Our method consistently outperforms the state-of-the-art ones both qualitatively and quantitatively, meanwhile revealing great potential in real-world applications. Our code and dataset are available.
Contextual Attention Mechanism, SRGAN Based Inpainting System for Eliminating Interruptions from Images
Apr 06, 2022
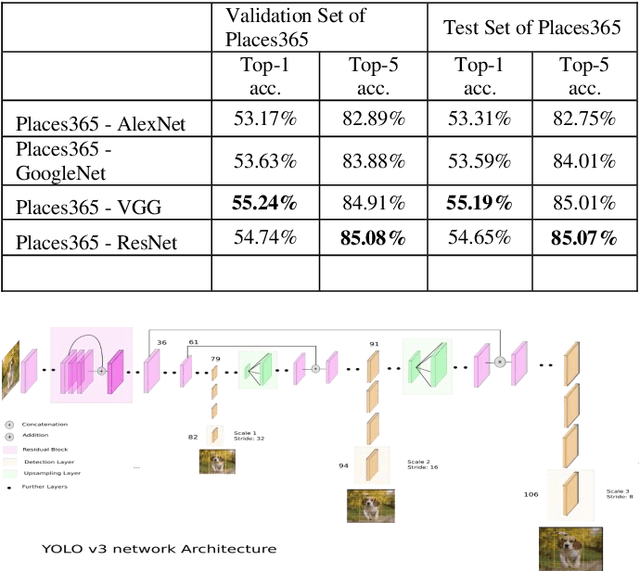
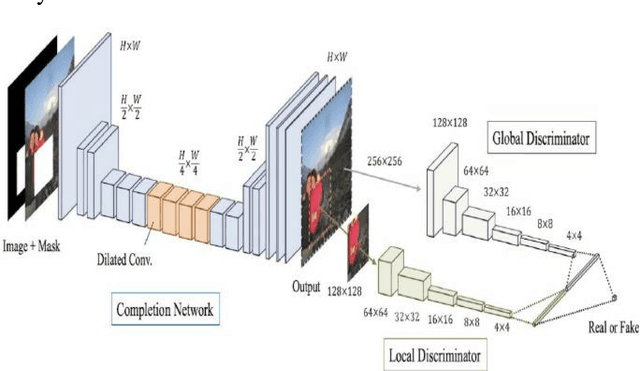
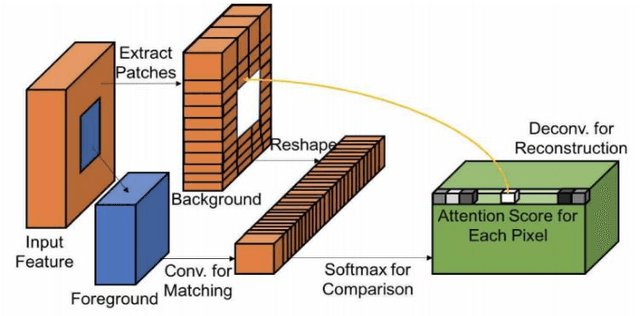
The new alternative is to use deep learning to inpaint any image by utilizing image classification and computer vision techniques. In general, image inpainting is a task of recreating or reconstructing any broken image which could be a photograph or oil/acrylic painting. With the advancement in the field of Artificial Intelligence, this topic has become popular among AI enthusiasts. With our approach, we propose an initial end-to-end pipeline for inpainting images using a complete Machine Learning approach instead of a conventional application-based approach. We first use the YOLO model to automatically identify and localize the object we wish to remove from the image. Using the result obtained from the model we can generate a mask for the same. After this, we provide the masked image and original image to the GAN model which uses the Contextual Attention method to fill in the region. It consists of two generator networks and two discriminator networks and is also called a coarse-to-fine network structure. The two generators use fully convolutional networks while the global discriminator gets hold of the entire image as input while the local discriminator gets the grip of the filled region as input. The contextual Attention mechanism is proposed to effectively borrow the neighbor information from distant spatial locations for reconstructing the missing pixels. The third part of our implementation uses SRGAN to resolve the inpainted image back to its original size. Our work is inspired by the paper Free-Form Image Inpainting with Gated Convolution and Generative Image Inpainting with Contextual Attention.
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
Aug 19, 2021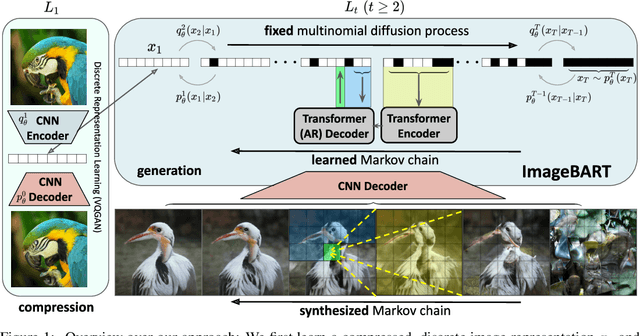



Autoregressive models and their sequential factorization of the data likelihood have recently demonstrated great potential for image representation and synthesis. Nevertheless, they incorporate image context in a linear 1D order by attending only to previously synthesized image patches above or to the left. Not only is this unidirectional, sequential bias of attention unnatural for images as it disregards large parts of a scene until synthesis is almost complete. It also processes the entire image on a single scale, thus ignoring more global contextual information up to the gist of the entire scene. As a remedy we incorporate a coarse-to-fine hierarchy of context by combining the autoregressive formulation with a multinomial diffusion process: Whereas a multistage diffusion process successively removes information to coarsen an image, we train a (short) Markov chain to invert this process. In each stage, the resulting autoregressive ImageBART model progressively incorporates context from previous stages in a coarse-to-fine manner. Experiments show greatly improved image modification capabilities over autoregressive models while also providing high-fidelity image generation, both of which are enabled through efficient training in a compressed latent space. Specifically, our approach can take unrestricted, user-provided masks into account to perform local image editing. Thus, in contrast to pure autoregressive models, it can solve free-form image inpainting and, in the case of conditional models, local, text-guided image modification without requiring mask-specific training.
NeRF-In: Free-Form NeRF Inpainting with RGB-D Priors
Jun 10, 2022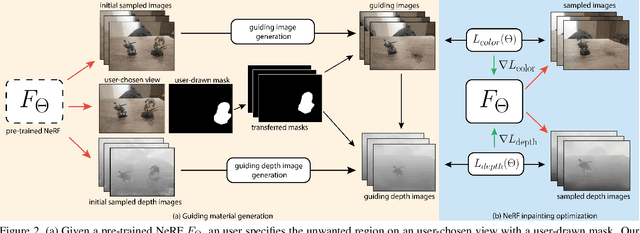
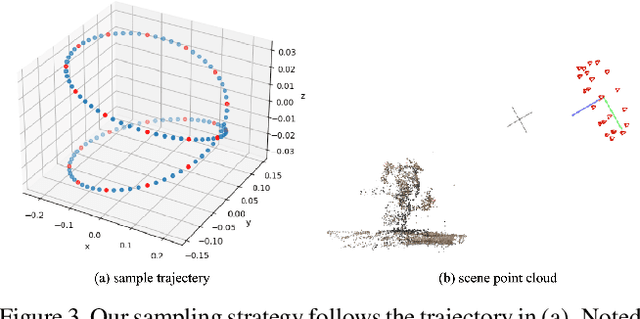


Though Neural Radiance Field (NeRF) demonstrates compelling novel view synthesis results, it is still unintuitive to edit a pre-trained NeRF because the neural network's parameters and the scene geometry/appearance are often not explicitly associated. In this paper, we introduce the first framework that enables users to remove unwanted objects or retouch undesired regions in a 3D scene represented by a pre-trained NeRF without any category-specific data and training. The user first draws a free-form mask to specify a region containing unwanted objects over a rendered view from the pre-trained NeRF. Our framework first transfers the user-provided mask to other rendered views and estimates guiding color and depth images within these transferred masked regions. Next, we formulate an optimization problem that jointly inpaints the image content in all masked regions across multiple views by updating the NeRF model's parameters. We demonstrate our framework on diverse scenes and show it obtained visual plausible and structurally consistent results across multiple views using shorter time and less user manual efforts.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022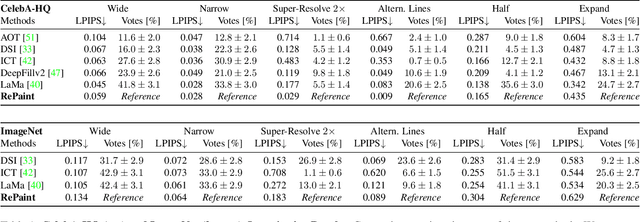
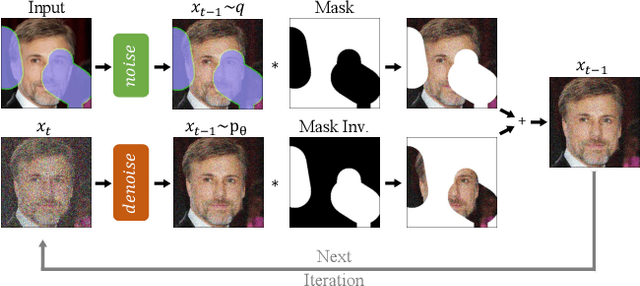


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Free-Form Image Inpainting via Contrastive Attention Network
Oct 29, 2020
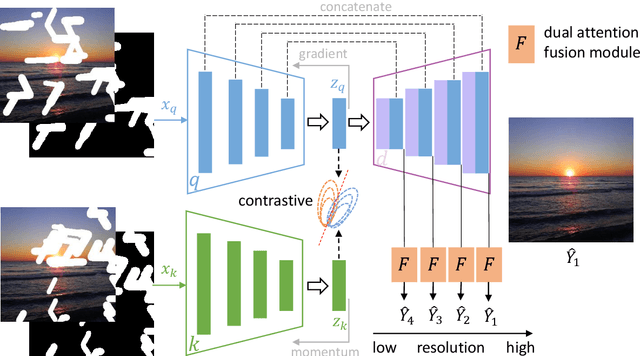
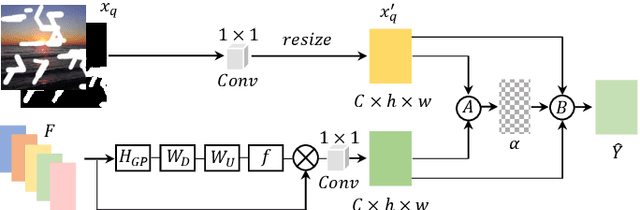

Most deep learning based image inpainting approaches adopt autoencoder or its variants to fill missing regions in images. Encoders are usually utilized to learn powerful representational spaces, which are important for dealing with sophisticated learning tasks. Specifically, in image inpainting tasks, masks with any shapes can appear anywhere in images (i.e., free-form masks) which form complex patterns. It is difficult for encoders to capture such powerful representations under this complex situation. To tackle this problem, we propose a self-supervised Siamese inference network to improve the robustness and generalization. It can encode contextual semantics from full resolution images and obtain more discriminative representations. we further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine both the restored and known regions in a smooth way. This multi-scale architecture is beneficial for decoding discriminative representations learned by encoders into images layer by layer. In this way, unknown regions will be filled naturally from outside to inside. Qualitative and quantitative experiments on multiple datasets, including facial and natural datasets (i.e., Celeb-HQ, Pairs Street View, Places2 and ImageNet), demonstrate that our proposed method outperforms state-of-the-art methods in generating high-quality inpainting results.