 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Completeness and Consistency Evaluation for Cultural Heritage Data Augmentation in Cross-Modal Retrieval
Nov 09, 2025



Cross-modal retrieval is essential for interpreting cultural heritage data, but its effectiveness is often limited by incomplete or inconsistent textual descriptions, caused by historical data loss and the high cost of expert annotation. While large language models (LLMs) offer a promising solution by enriching textual descriptions, their outputs frequently suffer from hallucinations or miss visually grounded details. To address these challenges, we propose $C^3$, a data augmentation framework that enhances cross-modal retrieval performance by improving the completeness and consistency of LLM-generated descriptions. $C^3$ introduces a completeness evaluation module to assess semantic coverage using both visual cues and language-model outputs. Furthermore, to mitigate factual inconsistencies, we formulate a Markov Decision Process to supervise Chain-of-Thought reasoning, guiding consistency evaluation through adaptive query control. Experiments on the cultural heritage datasets CulTi and TimeTravel, as well as on general benchmarks MSCOCO and Flickr30K, demonstrate that $C^3$ achieves state-of-the-art performance in both fine-tuned and zero-shot settings.
HiGarment: Cross-modal Harmony Based Diffusion Model for Flat Sketch to Realistic Garment Image
May 29, 2025



Diffusion-based garment synthesis tasks primarily focus on the design phase in the fashion domain, while the garment production process remains largely underexplored. To bridge this gap, we introduce a new task: Flat Sketch to Realistic Garment Image (FS2RG), which generates realistic garment images by integrating flat sketches and textual guidance. FS2RG presents two key challenges: 1) fabric characteristics are solely guided by textual prompts, providing insufficient visual supervision for diffusion-based models, which limits their ability to capture fine-grained fabric details; 2) flat sketches and textual guidance may provide conflicting information, requiring the model to selectively preserve or modify garment attributes while maintaining structural coherence. To tackle this task, we propose HiGarment, a novel framework that comprises two core components: i) a multi-modal semantic enhancement mechanism that enhances fabric representation across textual and visual modalities, and ii) a harmonized cross-attention mechanism that dynamically balances information from flat sketches and text prompts, allowing controllable synthesis by generating either sketch-aligned (image-biased) or text-guided (text-biased) outputs. Furthermore, we collect Multi-modal Detailed Garment, the largest open-source dataset for garment generation. Experimental results and user studies demonstrate the effectiveness of HiGarment in garment synthesis. The code and dataset will be released.
Zero-to-Hero: Zero-Shot Initialization Empowering Reference-Based Video Appearance Editing
May 29, 2025Appearance editing according to user needs is a pivotal task in video editing. Existing text-guided methods often lead to ambiguities regarding user intentions and restrict fine-grained control over editing specific aspects of objects. To overcome these limitations, this paper introduces a novel approach named {Zero-to-Hero}, which focuses on reference-based video editing that disentangles the editing process into two distinct problems. It achieves this by first editing an anchor frame to satisfy user requirements as a reference image and then consistently propagating its appearance across other frames. We leverage correspondence within the original frames to guide the attention mechanism, which is more robust than previously proposed optical flow or temporal modules in memory-friendly video generative models, especially when dealing with objects exhibiting large motions. It offers a solid ZERO-shot initialization that ensures both accuracy and temporal consistency. However, intervention in the attention mechanism results in compounded imaging degradation with over-saturated colors and unknown blurring issues. Starting from Zero-Stage, our Hero-Stage Holistically learns a conditional generative model for vidEo RestOration. To accurately evaluate the consistency of the appearance, we construct a set of videos with multiple appearances using Blender, enabling a fine-grained and deterministic evaluation. Our method outperforms the best-performing baseline with a PSNR improvement of 2.6 dB. The project page is at https://github.com/Tonniia/Zero2Hero.
Towards Cross-modal Retrieval in Chinese Cultural Heritage Documents: Dataset and Solution
May 16, 2025China has a long and rich history, encompassing a vast cultural heritage that includes diverse multimodal information, such as silk patterns, Dunhuang murals, and their associated historical narratives. Cross-modal retrieval plays a pivotal role in understanding and interpreting Chinese cultural heritage by bridging visual and textual modalities to enable accurate text-to-image and image-to-text retrieval. However, despite the growing interest in multimodal research, there is a lack of specialized datasets dedicated to Chinese cultural heritage, limiting the development and evaluation of cross-modal learning models in this domain. To address this gap, we propose a multimodal dataset named CulTi, which contains 5,726 image-text pairs extracted from two series of professional documents, respectively related to ancient Chinese silk and Dunhuang murals. Compared to existing general-domain multimodal datasets, CulTi presents a challenge for cross-modal retrieval: the difficulty of local alignment between intricate decorative motifs and specialized textual descriptions. To address this challenge, we propose LACLIP, a training-free local alignment strategy built upon a fine-tuned Chinese-CLIP. LACLIP enhances the alignment of global textual descriptions with local visual regions by computing weighted similarity scores during inference. Experimental results on CulTi demonstrate that LACLIP significantly outperforms existing models in cross-modal retrieval, particularly in handling fine-grained semantic associations within Chinese cultural heritage.
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Mar 23, 2023



This paper presents a new adversarial training framework for image inpainting with segmentation confusion adversarial training (SCAT) and contrastive learning. SCAT plays an adversarial game between an inpainting generator and a segmentation network, which provides pixel-level local training signals and can adapt to images with free-form holes. By combining SCAT with standard global adversarial training, the new adversarial training framework exhibits the following three advantages simultaneously: (1) the global consistency of the repaired image, (2) the local fine texture details of the repaired image, and (3) the flexibility of handling images with free-form holes. Moreover, we propose the textural and semantic contrastive learning losses to stabilize and improve our inpainting model's training by exploiting the feature representation space of the discriminator, in which the inpainting images are pulled closer to the ground truth images but pushed farther from the corrupted images. The proposed contrastive losses better guide the repaired images to move from the corrupted image data points to the real image data points in the feature representation space, resulting in more realistic completed images. We conduct extensive experiments on two benchmark datasets, demonstrating our model's effectiveness and superiority both qualitatively and quantitatively.
MicroAST: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer
Nov 28, 2022



Arbitrary style transfer (AST) transfers arbitrary artistic styles onto content images. Despite the recent rapid progress, existing AST methods are either incapable or too slow to run at ultra-resolutions (e.g., 4K) with limited resources, which heavily hinders their further applications. In this paper, we tackle this dilemma by learning a straightforward and lightweight model, dubbed MicroAST. The key insight is to completely abandon the use of cumbersome pre-trained Deep Convolutional Neural Networks (e.g., VGG) at inference. Instead, we design two micro encoders (content and style encoders) and one micro decoder for style transfer. The content encoder aims at extracting the main structure of the content image. The style encoder, coupled with a modulator, encodes the style image into learnable dual-modulation signals that modulate both intermediate features and convolutional filters of the decoder, thus injecting more sophisticated and flexible style signals to guide the stylizations. In addition, to boost the ability of the style encoder to extract more distinct and representative style signals, we also introduce a new style signal contrastive loss in our model. Compared to the state of the art, our MicroAST not only produces visually superior results but also is 5-73 times smaller and 6-18 times faster, for the first time enabling super-fast (about 0.5 seconds) AST at 4K ultra-resolutions. Code is available at https://github.com/EndyWon/MicroAST.
AesUST: Towards Aesthetic-Enhanced Universal Style Transfer
Aug 27, 2022

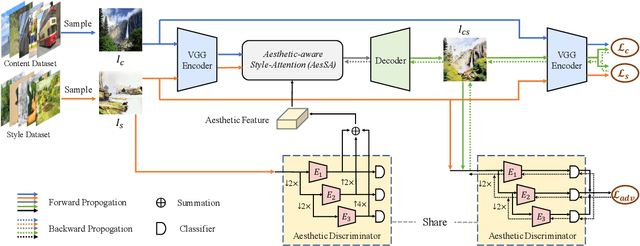
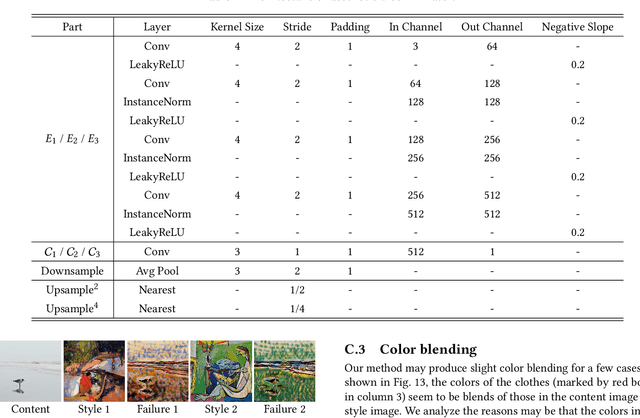
Recent studies have shown remarkable success in universal style transfer which transfers arbitrary visual styles to content images. However, existing approaches suffer from the aesthetic-unrealistic problem that introduces disharmonious patterns and evident artifacts, making the results easy to spot from real paintings. To address this limitation, we propose AesUST, a novel Aesthetic-enhanced Universal Style Transfer approach that can generate aesthetically more realistic and pleasing results for arbitrary styles. Specifically, our approach introduces an aesthetic discriminator to learn the universal human-delightful aesthetic features from a large corpus of artist-created paintings. Then, the aesthetic features are incorporated to enhance the style transfer process via a novel Aesthetic-aware Style-Attention (AesSA) module. Such an AesSA module enables our AesUST to efficiently and flexibly integrate the style patterns according to the global aesthetic channel distribution of the style image and the local semantic spatial distribution of the content image. Moreover, we also develop a new two-stage transfer training strategy with two aesthetic regularizations to train our model more effectively, further improving stylization performance. Extensive experiments and user studies demonstrate that our approach synthesizes aesthetically more harmonious and realistic results than state of the art, greatly narrowing the disparity with real artist-created paintings. Our code is available at https://github.com/EndyWon/AesUST.
Texture Reformer: Towards Fast and Universal Interactive Texture Transfer
Dec 06, 2021
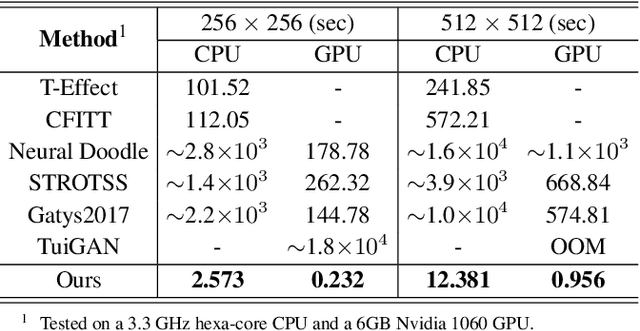
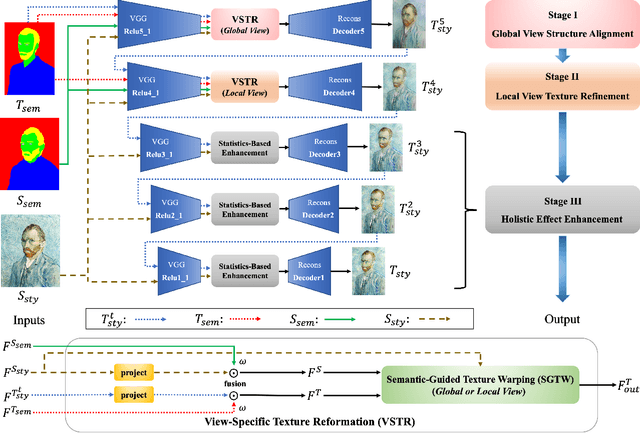
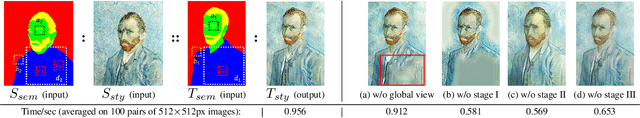
In this paper, we present the texture reformer, a fast and universal neural-based framework for interactive texture transfer with user-specified guidance. The challenges lie in three aspects: 1) the diversity of tasks, 2) the simplicity of guidance maps, and 3) the execution efficiency. To address these challenges, our key idea is to use a novel feed-forward multi-view and multi-stage synthesis procedure consisting of I) a global view structure alignment stage, II) a local view texture refinement stage, and III) a holistic effect enhancement stage to synthesize high-quality results with coherent structures and fine texture details in a coarse-to-fine fashion. In addition, we also introduce a novel learning-free view-specific texture reformation (VSTR) operation with a new semantic map guidance strategy to achieve more accurate semantic-guided and structure-preserved texture transfer. The experimental results on a variety of application scenarios demonstrate the effectiveness and superiority of our framework. And compared with the state-of-the-art interactive texture transfer algorithms, it not only achieves higher quality results but, more remarkably, also is 2-5 orders of magnitude faster. Code is available at https://github.com/EndyWon/Texture-Reformer.
Diversified Patch-based Style Transfer with Shifted Style Normalization
Jan 16, 2021
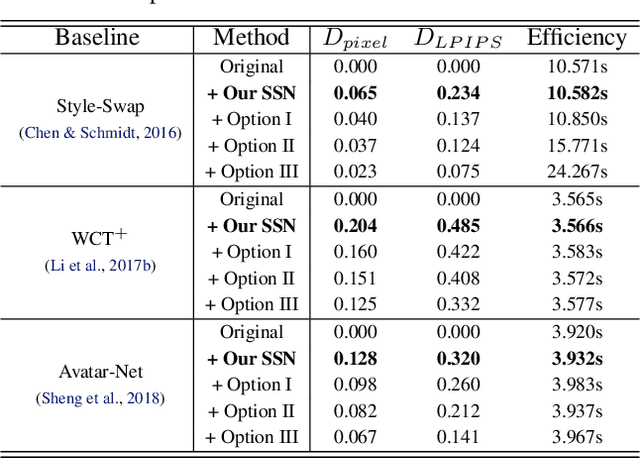
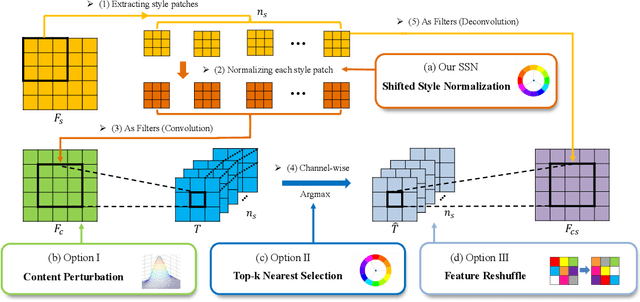
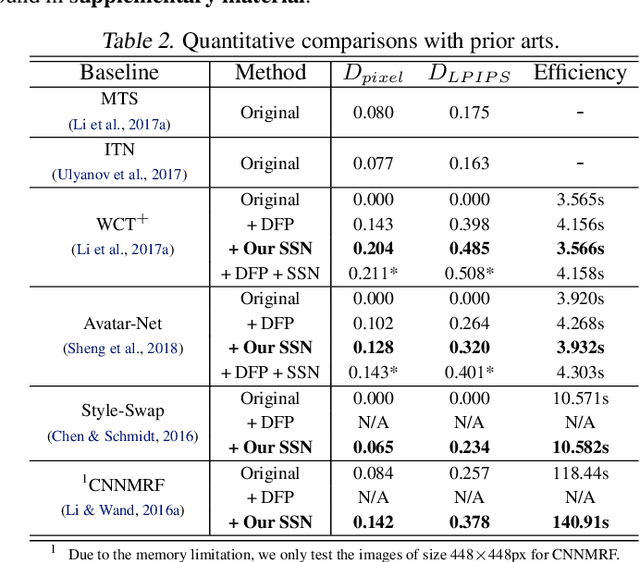
Gram-based and patch-based approaches are two important research lines of image style transfer. Recent diversified Gram-based methods have been able to produce multiple and diverse reasonable solutions for the same content and style inputs. However, as another popular research interest, the diversity of patch-based methods remains challenging due to the stereotyped style swapping process based on nearest patch matching. To resolve this dilemma, in this paper, we dive into the core style swapping process of patch-based style transfer and explore possible ways to diversify it. What stands out is an operation called shifted style normalization (SSN), the most effective and efficient way to empower existing patch-based methods to generate diverse results for arbitrary styles. The key insight is to use an important intuition that neural patches with higher activation values could contribute more to diversity. Theoretical analyses and extensive experiments are conducted to demonstrate the effectiveness of our method, and compared with other possible options and state-of-the-art algorithms, it shows remarkable superiority in both diversity and efficiency.
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Sep 06, 2020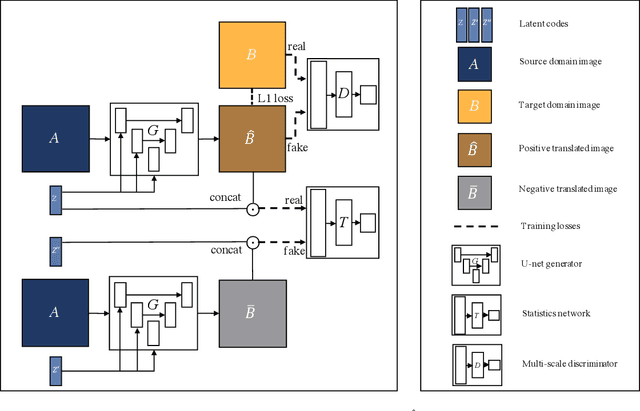
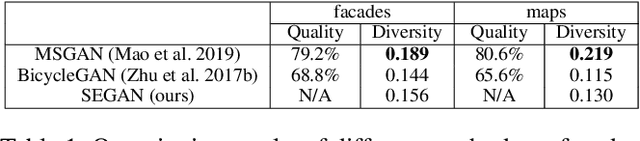

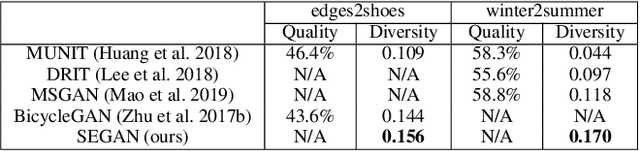
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.