 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMI: Efficient Self-Supervised Learning via Mutual-Information-Inspired Dependency Optimization
Jun 06, 2026Self-supervised learning (SSL) has achieved remarkable representation learning performance, but many existing methods rely on large batch sizes, memory banks, momentum encoders, or global synchronization mechanisms that substantially increase computational cost and training complexity. In this work, we propose Semantic Mutual Information (SMI), a lightweight self-supervised objective derived from a mutual-information-inspired dependency formulation under Gaussian assumptions. Unlike conventional correlation matching objectives that operate on high-dimensional feature correlation matrices, SMI performs optimization on a sample-level dependency matrix through a nonlinear transformation of pairwise correlations. This formulation induces distinct optimization dynamics that emphasize strongly dependent semantic pairs while maintaining representation diversity. Experimental results on ImageNet using a ResNet-50 backbone demonstrate that SMI achieves competitive linear evaluation performance relative to state-of-the-art SSL approaches while substantially reducing computational complexity. Across multiple low-resource benchmarks, SMI consistently improves transfer performance over Barlow Twins, particularly on fine-grained datasets. Furthermore, analyses of optimization dynamics and representation geometry suggest improved alignment--redundancy balance, greater feature diversity, and more spatially localized semantic representations. These results indicate that nonlinear dependency optimization provides an effective and computationally efficient alternative to conventional correlation-based self-supervised learning objectives.
TRIM: A Self-Supervised Video Summarization Framework Maximizing Temporal Relative Information and Representativeness
Jun 25, 2025The increasing ubiquity of video content and the corresponding demand for efficient access to meaningful information have elevated video summarization and video highlights as a vital research area. However, many state-of-the-art methods depend heavily either on supervised annotations or on attention-based models, which are computationally expensive and brittle in the face of distribution shifts that hinder cross-domain applicability across datasets. We introduce a pioneering self-supervised video summarization model that captures both spatial and temporal dependencies without the overhead of attention, RNNs, or transformers. Our framework integrates a novel set of Markov process-driven loss metrics and a two-stage self supervised learning paradigm that ensures both performance and efficiency. Our approach achieves state-of-the-art performance on the SUMME and TVSUM datasets, outperforming all existing unsupervised methods. It also rivals the best supervised models, demonstrating the potential for efficient, annotation-free architectures. This paves the way for more generalizable video summarization techniques and challenges the prevailing reliance on complex architectures.
RETHINED: A New Benchmark and Baseline for Real-Time High-Resolution Image Inpainting On Edge Devices
Mar 18, 2025



Existing image inpainting methods have shown impressive completion results for low-resolution images. However, most of these algorithms fail at high resolutions and require powerful hardware, limiting their deployment on edge devices. Motivated by this, we propose the first baseline for REal-Time High-resolution image INpainting on Edge Devices (RETHINED) that is able to inpaint at ultra-high-resolution and can run in real-time ($\leq$ 30ms) in a wide variety of mobile devices. A simple, yet effective novel method formed by a lightweight Convolutional Neural Network (CNN) to recover structure, followed by a resolution-agnostic patch replacement mechanism to provide detailed texture. Specially our pipeline leverages the structural capacity of CNN and the high-level detail of patch-based methods, which is a key component for high-resolution image inpainting. To demonstrate the real application of our method, we conduct an extensive analysis on various mobile-friendly devices and demonstrate similar inpainting performance while being $\mathrm{100 \times faster}$ than existing state-of-the-art methods. Furthemore, we realease DF8K-Inpainting, the first free-form mask UHD inpainting dataset.
Visual Motif Identification: Elaboration of a Curated Comparative Dataset and Classification Methods
Oct 21, 2024



In cinema, visual motifs are recurrent iconographic compositions that carry artistic or aesthetic significance. Their use throughout the history of visual arts and media is interesting to researchers and filmmakers alike. Our goal in this work is to recognise and classify these motifs by proposing a new machine learning model that uses a custom dataset to that end. We show how features extracted from a CLIP model can be leveraged by using a shallow network and an appropriate loss to classify images into 20 different motifs, with surprisingly good results: an $F_1$-score of 0.91 on our test set. We also present several ablation studies justifying the input features, architecture and hyperparameters used.
A Graph-Based Method for Soccer Action Spotting Using Unsupervised Player Classification
Nov 22, 2022Action spotting in soccer videos is the task of identifying the specific time when a certain key action of the game occurs. Lately, it has received a large amount of attention and powerful methods have been introduced. Action spotting involves understanding the dynamics of the game, the complexity of events, and the variation of video sequences. Most approaches have focused on the latter, given that their models exploit the global visual features of the sequences. In this work, we focus on the former by (a) identifying and representing the players, referees, and goalkeepers as nodes in a graph, and by (b) modeling their temporal interactions as sequences of graphs. For the player identification, or player classification task, we obtain an accuracy of 97.72% in our annotated benchmark. For the action spotting task, our method obtains an overall performance of 57.83% average-mAP by combining it with other audiovisual modalities. This performance surpasses similar graph-based methods and has competitive results with heavy computing methods. Code and data are available at https://github.com/IPCV/soccer_action_spotting.
Photorealistic Facial Wrinkles Removal
Nov 03, 2022



Editing and retouching facial attributes is a complex task that usually requires human artists to obtain photo-realistic results. Its applications are numerous and can be found in several contexts such as cosmetics or digital media retouching, to name a few. Recently, advancements in conditional generative modeling have shown astonishing results at modifying facial attributes in a realistic manner. However, current methods are still prone to artifacts, and focus on modifying global attributes like age and gender, or local mid-sized attributes like glasses or moustaches. In this work, we revisit a two-stage approach for retouching facial wrinkles and obtain results with unprecedented realism. First, a state of the art wrinkle segmentation network is used to detect the wrinkles within the facial region. Then, an inpainting module is used to remove the detected wrinkles, filling them in with a texture that is statistically consistent with the surrounding skin. To achieve this, we introduce a novel loss term that reuses the wrinkle segmentation network to penalize those regions that still contain wrinkles after the inpainting. We evaluate our method qualitatively and quantitatively, showing state of the art results for the task of wrinkle removal. Moreover, we introduce the first high-resolution dataset, named FFHQ-Wrinkles, to evaluate wrinkle detection methods.
An Analysis of Generative Methods for Multiple Image Inpainting
May 04, 2022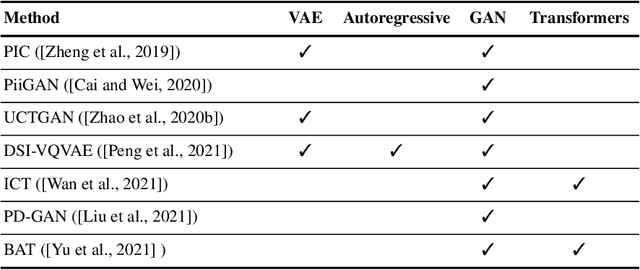
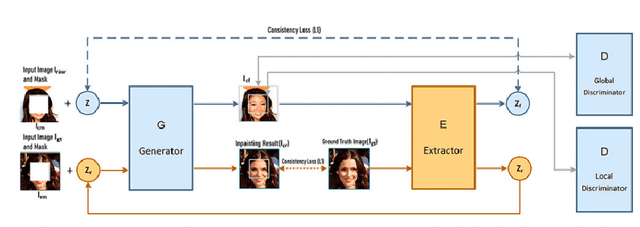
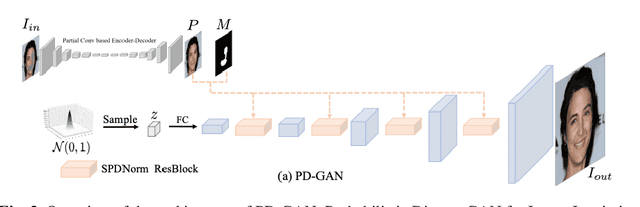
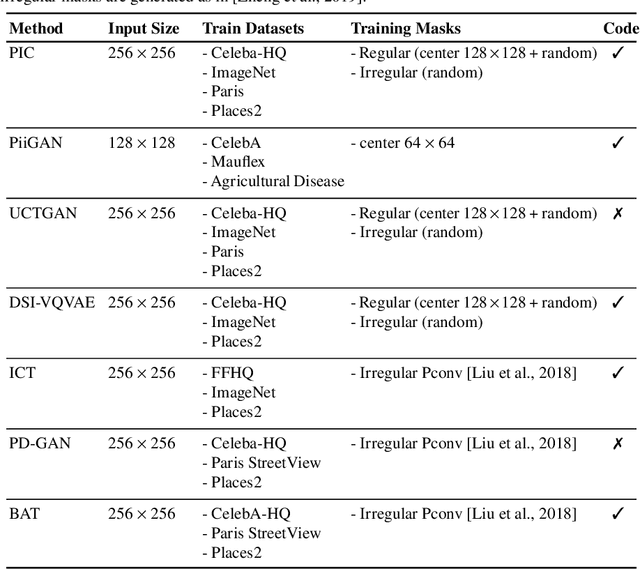
Image inpainting refers to the restoration of an image with missing regions in a way that is not detectable by the observer. The inpainting regions can be of any size and shape. This is an ill-posed inverse problem that does not have a unique solution. In this work, we focus on learning-based image completion methods for multiple and diverse inpainting which goal is to provide a set of distinct solutions for a given damaged image. These methods capitalize on the probabilistic nature of certain generative models to sample various solutions that coherently restore the missing content. Along the chapter, we will analyze the underlying theory and analyze the recent proposals for multiple inpainting. To investigate the pros and cons of each method, we present quantitative and qualitative comparisons, on common datasets, regarding both the quality and the diversity of the set of inpainted solutions. Our analysis allows us to identify the most successful generative strategies in both inpainting quality and inpainting diversity. This task is closely related to the learning of an accurate probability distribution of images. Depending on the dataset in use, the challenges that entail the training of such a model will be discussed through the analysis.
Analysis of Different Losses for Deep Learning Image Colorization
Apr 06, 2022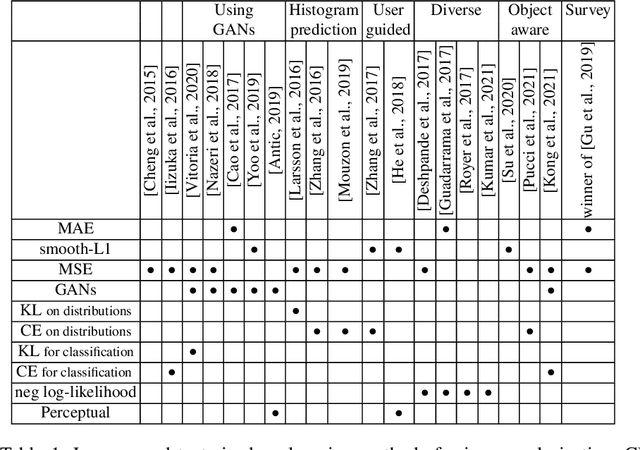
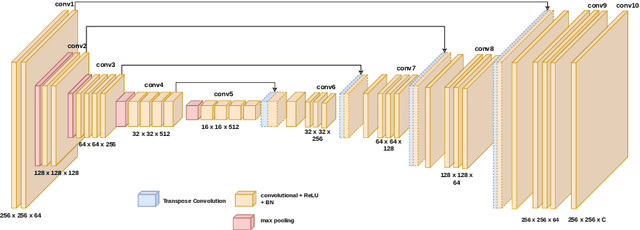
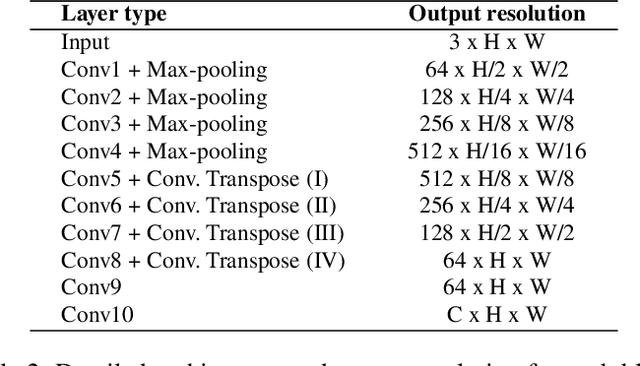

Image colorization aims to add color information to a grayscale image in a realistic way. Recent methods mostly rely on deep learning strategies. While learning to automatically colorize an image, one can define well-suited objective functions related to the desired color output. Some of them are based on a specific type of error between the predicted image and ground truth one, while other losses rely on the comparison of perceptual properties. But, is the choice of the objective function that crucial, i.e., does it play an important role in the results? In this chapter, we aim to answer this question by analyzing the impact of the loss function on the estimated colorization results. To that goal, we review the different losses and evaluation metrics that are used in the literature. We then train a baseline network with several of the reviewed objective functions: classic L1 and L2 losses, as well as more complex combinations such as Wasserstein GAN and VGG-based LPIPS loss. Quantitative results show that the models trained with VGG-based LPIPS provide overall slightly better results for most evaluation metrics. Qualitative results exhibit more vivid colors when with Wasserstein GAN plus the L2 loss or again with the VGG-based LPIPS. Finally, the convenience of quantitative user studies is also discussed to overcome the difficulty of properly assessing on colorized images, notably for the case of old archive photographs where no ground truth is available.
Influence of Color Spaces for Deep Learning Image Colorization
Apr 06, 2022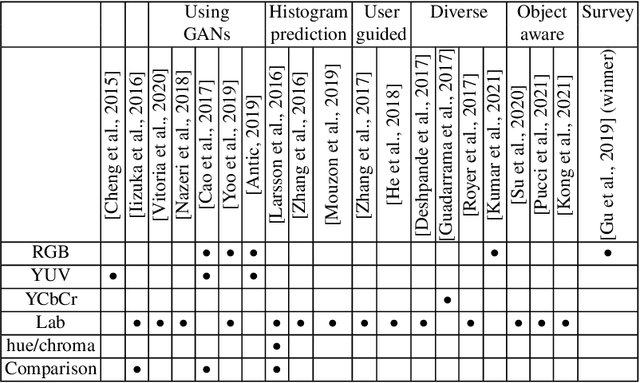

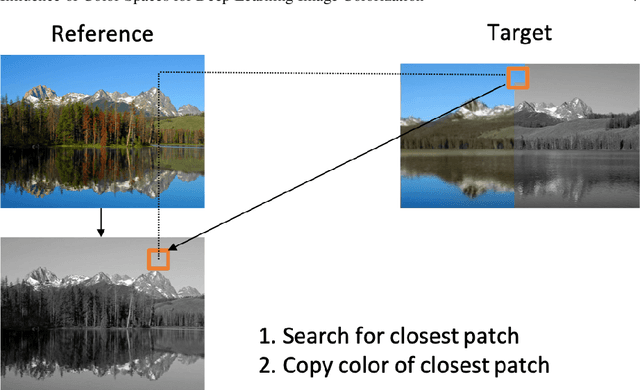
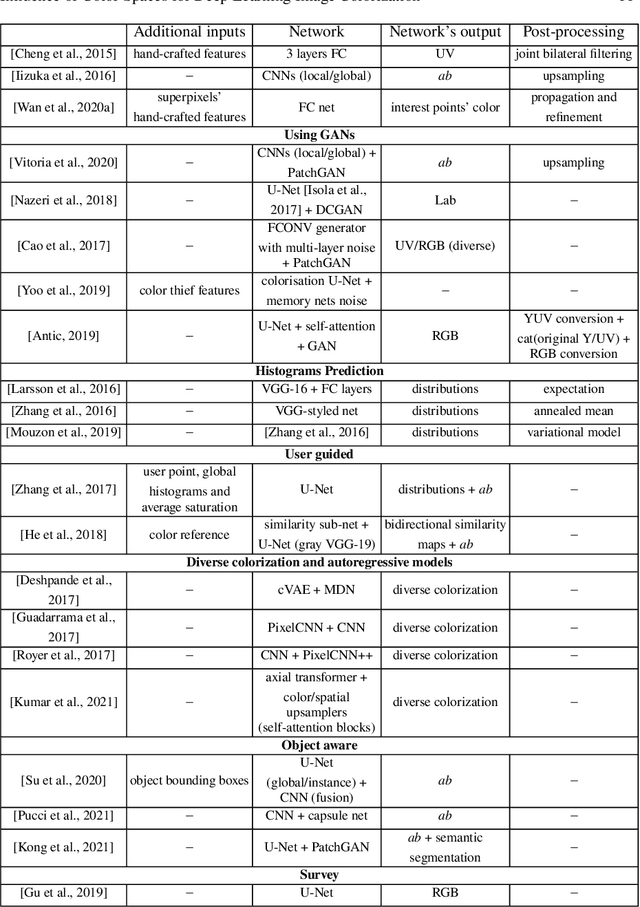
Colorization is a process that converts a grayscale image into a color one that looks as natural as possible. Over the years this task has received a lot of attention. Existing colorization methods rely on different color spaces: RGB, YUV, Lab, etc. In this chapter, we aim to study their influence on the results obtained by training a deep neural network, to answer the question: "Is it crucial to correctly choose the right color space in deep-learning based colorization?". First, we briefly summarize the literature and, in particular, deep learning-based methods. We then compare the results obtained with the same deep neural network architecture with RGB, YUV and Lab color spaces. Qualitative and quantitative analysis do not conclude similarly on which color space is better. We then show the importance of carefully designing the architecture and evaluation protocols depending on the types of images that are being processed and their specificities: strong/small contours, few/many objects, recent/archive images.
Learning Football Body-Orientation as a Matter of Classification
Jun 01, 2021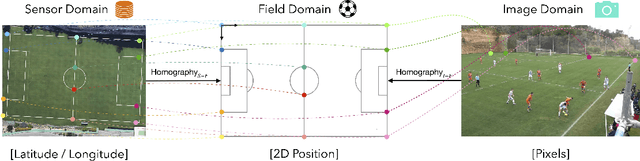
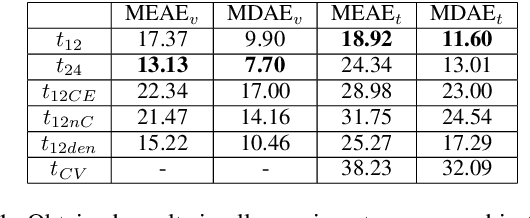
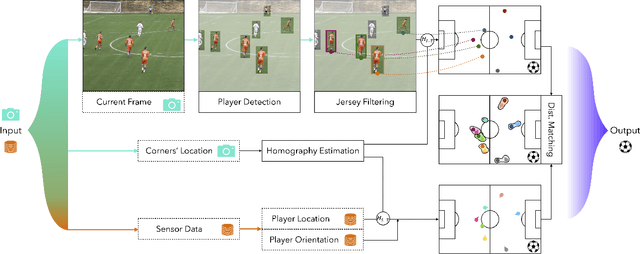
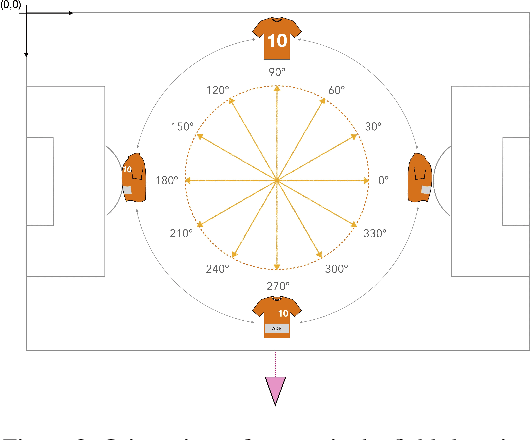
Orientation is a crucial skill for football players that becomes a differential factor in a large set of events, especially the ones involving passes. However, existing orientation estimation methods, which are based on computer-vision techniques, still have a lot of room for improvement. To the best of our knowledge, this article presents the first deep learning model for estimating orientation directly from video footage. By approaching this challenge as a classification problem where classes correspond to orientation bins, and by introducing a cyclic loss function, a well-known convolutional network is refined to provide player orientation data. The model is trained by using ground-truth orientation data obtained from wearable EPTS devices, which are individually compensated with respect to the perceived orientation in the current frame. The obtained results outperform previous methods; in particular, the absolute median error is less than 12 degrees per player. An ablation study is included in order to show the potential generalization to any kind of football video footage.