 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBloomz
Papers and Code
When Flores Bloomz Wrong: Cross-Direction Contamination in Machine Translation Evaluation
Jan 28, 2026Large language models (LLMs) can be benchmark-contaminated, resulting in inflated scores that mask memorization as generalization, and in multilingual settings, this memorization can even transfer to "uncontaminated" languages. Using the FLORES-200 translation benchmark as a diagnostic, we study two 7-8B instruction-tuned multilingual LLMs: Bloomz, which was trained on FLORES, and Llama as an uncontaminated control. We confirm Bloomz's FLORES contamination and demonstrate that machine translation contamination can be cross-directional, artificially boosting performance in unseen translation directions due to target-side memorization. Further analysis shows that recall of memorized references often persists despite various source-side perturbation efforts like paraphrasing and named entity replacement. However, replacing named entities leads to a consistent decrease in BLEU, suggesting an effective probing method for memorization in contaminated models.
Exploring Cultural Variations in Moral Judgments with Large Language Models
Jun 14, 2025Large Language Models (LLMs) have shown strong performance across many tasks, but their ability to capture culturally diverse moral values remains unclear. In this paper, we examine whether LLMs can mirror variations in moral attitudes reported by two major cross-cultural surveys: the World Values Survey and the PEW Research Center's Global Attitudes Survey. We compare smaller, monolingual, and multilingual models (GPT-2, OPT, BLOOMZ, and Qwen) with more recent instruction-tuned models (GPT-4o, GPT-4o-mini, Gemma-2-9b-it, and Llama-3.3-70B-Instruct). Using log-probability-based moral justifiability scores, we correlate each model's outputs with survey data covering a broad set of ethical topics. Our results show that many earlier or smaller models often produce near-zero or negative correlations with human judgments. In contrast, advanced instruction-tuned models (including GPT-4o and GPT-4o-mini) achieve substantially higher positive correlations, suggesting they better reflect real-world moral attitudes. While scaling up model size and using instruction tuning can improve alignment with cross-cultural moral norms, challenges remain for certain topics and regions. We discuss these findings in relation to bias analysis, training data diversity, and strategies for improving the cultural sensitivity of LLMs.
Can Prompting LLMs Unlock Hate Speech Detection across Languages? A Zero-shot and Few-shot Study
May 09, 2025Despite growing interest in automated hate speech detection, most existing approaches overlook the linguistic diversity of online content. Multilingual instruction-tuned large language models such as LLaMA, Aya, Qwen, and BloomZ offer promising capabilities across languages, but their effectiveness in identifying hate speech through zero-shot and few-shot prompting remains underexplored. This work evaluates LLM prompting-based detection across eight non-English languages, utilizing several prompting techniques and comparing them to fine-tuned encoder models. We show that while zero-shot and few-shot prompting lag behind fine-tuned encoder models on most of the real-world evaluation sets, they achieve better generalization on functional tests for hate speech detection. Our study also reveals that prompt design plays a critical role, with each language often requiring customized prompting techniques to maximize performance.
Controlled Territory and Conflict Tracking (CONTACT): (Geo-)Mapping Occupied Territory from Open Source Intelligence
Apr 18, 2025

Open-source intelligence provides a stream of unstructured textual data that can inform assessments of territorial control. We present CONTACT, a framework for territorial control prediction using large language models (LLMs) and minimal supervision. We evaluate two approaches: SetFit, an embedding-based few-shot classifier, and a prompt tuning method applied to BLOOMZ-560m, a multilingual generative LLM. Our model is trained on a small hand-labeled dataset of news articles covering ISIS activity in Syria and Iraq, using prompt-conditioned extraction of control-relevant signals such as military operations, casualties, and location references. We show that the BLOOMZ-based model outperforms the SetFit baseline, and that prompt-based supervision improves generalization in low-resource settings. CONTACT demonstrates that LLMs fine-tuned using few-shot methods can reduce annotation burdens and support structured inference from open-ended OSINT streams. Our code is available at https://github.com/PaulKMandal/CONTACT/.
Crafting Tomorrow's Headlines: Neural News Generation and Detection in English, Turkish, Hungarian, and Persian
Aug 20, 2024



In the era dominated by information overload and its facilitation with Large Language Models (LLMs), the prevalence of misinformation poses a significant threat to public discourse and societal well-being. A critical concern at present involves the identification of machine-generated news. In this work, we take a significant step by introducing a benchmark dataset designed for neural news detection in four languages: English, Turkish, Hungarian, and Persian. The dataset incorporates outputs from multiple multilingual generators (in both, zero-shot and fine-tuned setups) such as BloomZ, LLaMa-2, Mistral, Mixtral, and GPT-4. Next, we experiment with a variety of classifiers, ranging from those based on linguistic features to advanced Transformer-based models and LLMs prompting. We present the detection results aiming to delve into the interpretablity and robustness of machine-generated texts detectors across all target languages.
Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning
Jun 01, 2024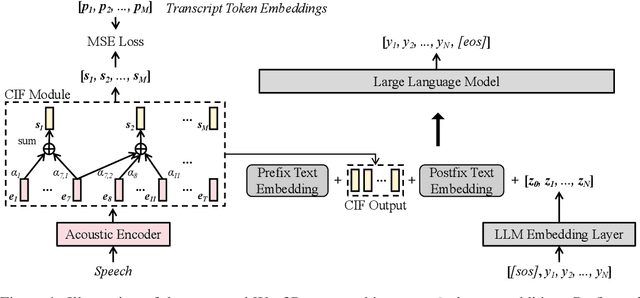
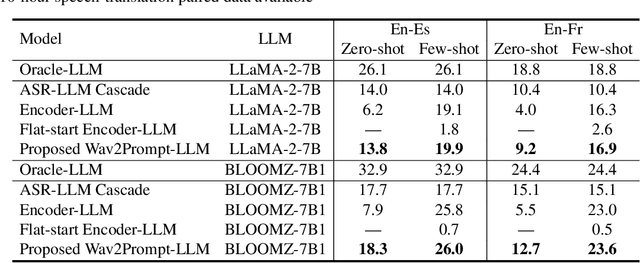


Wav2Prompt is proposed which allows straightforward integration between spoken input and a text-based large language model (LLM). Wav2Prompt uses a simple training process with only the same data used to train an automatic speech recognition (ASR) model. After training, Wav2Prompt learns continuous representations from speech and uses them as LLM prompts. To avoid task over-fitting issues found in prior work and preserve the emergent abilities of LLMs, Wav2Prompt takes LLM token embeddings as the training targets and utilises a continuous integrate-and-fire mechanism for explicit speech-text alignment. Therefore, a Wav2Prompt-LLM combination can be applied to zero-shot spoken language tasks such as speech translation (ST), speech understanding (SLU), speech question answering (SQA) and spoken-query-based QA (SQQA). It is shown that for these zero-shot tasks, Wav2Prompt performs similarly to an ASR-LLM cascade and better than recent prior work. If relatively small amounts of task-specific paired data are available in few-shot scenarios, the Wav2Prompt-LLM combination can be end-to-end (E2E) fine-tuned. The Wav2Prompt-LLM combination then yields greatly improved results relative to an ASR-LLM cascade for the above tasks. For instance, for English-French ST with the BLOOMZ-7B1 LLM, a Wav2Prompt-LLM combination gave a 8.5 BLEU point increase over an ASR-LLM cascade.
Benchmarking Pre-trained Large Language Models' Potential Across Urdu NLP tasks
May 24, 2024Large Language Models (LLMs) pre-trained on multilingual data have revolutionized natural language processing research, by transitioning from languages and task specific model pipelines to a single model adapted on a variety of tasks. However majority of existing multilingual NLP benchmarks for LLMs provide evaluation data in only few languages with little linguistic diversity. In addition these benchmarks lack quality assessment against the respective state-of the art models. This study presents an in-depth examination of prominent LLMs; GPT-3.5-turbo, Llama2-7B-Chat, Bloomz 7B1 and Bloomz 3B, across 14 tasks using 15 Urdu datasets, in a zero-shot setting, and their performance against state-of-the-art (SOTA) models, has been compared and analysed. Our experiments show that SOTA models surpass all the encoder-decoder pre-trained language models in all Urdu NLP tasks with zero-shot learning. Our results further show that LLMs with fewer parameters, but more language specific data in the base model perform better than larger computational models, but low language data.
Evaluating Quantized Large Language Models
Feb 28, 2024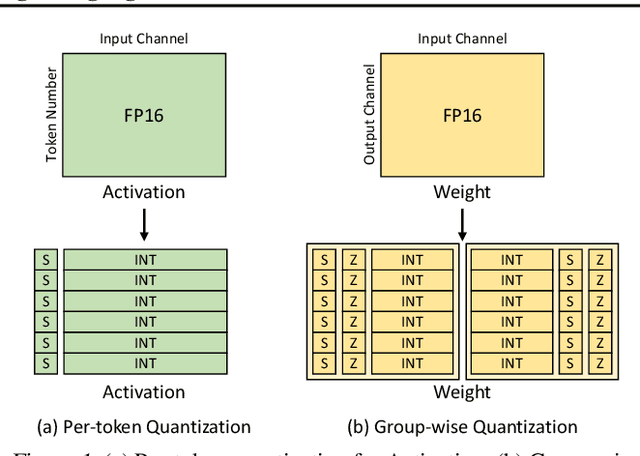



Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions.
MoZIP: A Multilingual Benchmark to Evaluate Large Language Models in Intellectual Property
Feb 26, 2024Large language models (LLMs) have demonstrated impressive performance in various natural language processing (NLP) tasks. However, there is limited understanding of how well LLMs perform in specific domains (e.g, the intellectual property (IP) domain). In this paper, we contribute a new benchmark, the first Multilingual-oriented quiZ on Intellectual Property (MoZIP), for the evaluation of LLMs in the IP domain. The MoZIP benchmark includes three challenging tasks: IP multiple-choice quiz (IPQuiz), IP question answering (IPQA), and patent matching (PatentMatch). In addition, we also develop a new IP-oriented multilingual large language model (called MoZi), which is a BLOOMZ-based model that has been supervised fine-tuned with multilingual IP-related text data. We evaluate our proposed MoZi model and four well-known LLMs (i.e., BLOOMZ, BELLE, ChatGLM and ChatGPT) on the MoZIP benchmark. Experimental results demonstrate that MoZi outperforms BLOOMZ, BELLE and ChatGLM by a noticeable margin, while it had lower scores compared with ChatGPT. Notably, the performance of current LLMs on the MoZIP benchmark has much room for improvement, and even the most powerful ChatGPT does not reach the passing level. Our source code, data, and models are available at \url{https://github.com/AI-for-Science/MoZi}.
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
Feb 20, 2024



The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.