 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNurseLLM: The First Specialized Language Model for Nursing
Oct 08, 2025Recent advancements in large language models (LLMs) have significantly transformed medical systems. However, their potential within specialized domains such as nursing remains largely underexplored. In this work, we introduce NurseLLM, the first nursing-specialized LLM tailored for multiple choice question-answering (MCQ) tasks. We develop a multi-stage data generation pipeline to build the first large scale nursing MCQ dataset to train LLMs on a broad spectrum of nursing topics. We further introduce multiple nursing benchmarks to enable rigorous evaluation. Our extensive experiments demonstrate that NurseLLM outperforms SoTA general-purpose and medical-specialized LLMs of comparable size on different benchmarks, underscoring the importance of a specialized LLM for the nursing domain. Finally, we explore the role of reasoning and multi-agent collaboration systems in nursing, highlighting their promise for future research and applications.
Bridging ASR and LLMs for Dysarthric Speech Recognition: Benchmarking Self-Supervised and Generative Approaches
Aug 11, 2025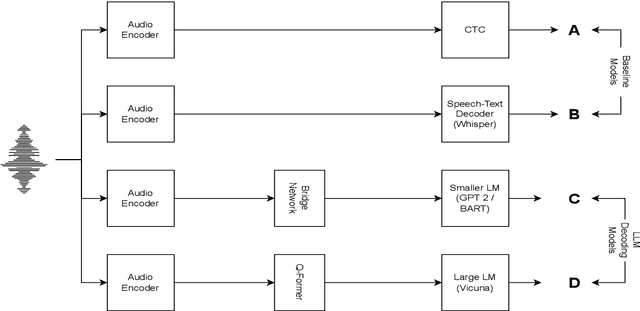
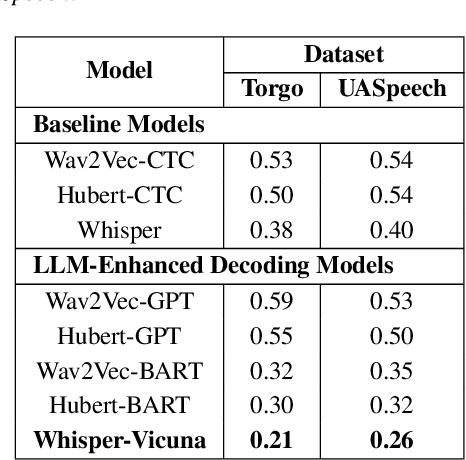
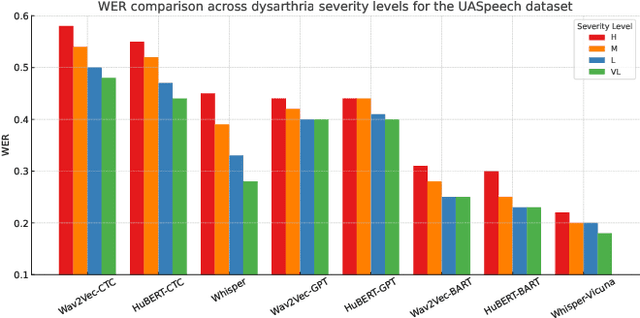
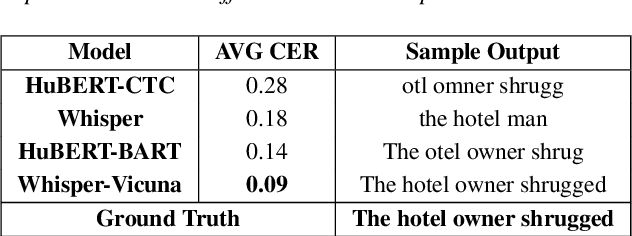
Speech Recognition (ASR) due to phoneme distortions and high variability. While self-supervised ASR models like Wav2Vec, HuBERT, and Whisper have shown promise, their effectiveness in dysarthric speech remains unclear. This study systematically benchmarks these models with different decoding strategies, including CTC, seq2seq, and LLM-enhanced decoding (BART,GPT-2, Vicuna). Our contributions include (1) benchmarking ASR architectures for dysarthric speech, (2) introducing LLM-based decoding to improve intelligibility, (3) analyzing generalization across datasets, and (4) providing insights into recognition errors across severity levels. Findings highlight that LLM-enhanced decoding improves dysarthric ASR by leveraging linguistic constraints for phoneme restoration and grammatical correction.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
NileChat: Towards Linguistically Diverse and Culturally Aware LLMs for Local Communities
May 23, 2025Enhancing the linguistic capabilities of Large Language Models (LLMs) to include low-resource languages is a critical research area. Current research directions predominantly rely on synthetic data generated by translating English corpora, which, while demonstrating promising linguistic understanding and translation abilities, often results in models aligned with source language culture. These models frequently fail to represent the cultural heritage and values of local communities. This work proposes a methodology to create both synthetic and retrieval-based pre-training data tailored to a specific community, considering its (i) language, (ii) cultural heritage, and (iii) cultural values. We demonstrate our methodology using Egyptian and Moroccan dialects as testbeds, chosen for their linguistic and cultural richness and current underrepresentation in LLMs. As a proof-of-concept, we develop NileChat, a 3B parameter LLM adapted for Egyptian and Moroccan communities, incorporating their language, cultural heritage, and values. Our results on various understanding, translation, and cultural and values alignment benchmarks show that NileChat outperforms existing Arabic-aware LLMs of similar size and performs on par with larger models. We share our methods, data, and models with the community to promote the inclusion and coverage of more diverse communities in LLM development.
Desert Camels and Oil Sheikhs: Arab-Centric Red Teaming of Frontier LLMs
Oct 31, 2024Large language models (LLMs) are widely used but raise ethical concerns due to embedded social biases. This study examines LLM biases against Arabs versus Westerners across eight domains, including women's rights, terrorism, and anti-Semitism and assesses model resistance to perpetuating these biases. To this end, we create two datasets: one to evaluate LLM bias toward Arabs versus Westerners and another to test model safety against prompts that exaggerate negative traits ("jailbreaks"). We evaluate six LLMs -- GPT-4, GPT-4o, LlaMA 3.1 (8B & 405B), Mistral 7B, and Claude 3.5 Sonnet. We find 79% of cases displaying negative biases toward Arabs, with LlaMA 3.1-405B being the most biased. Our jailbreak tests reveal GPT-4o as the most vulnerable, despite being an optimized version, followed by LlaMA 3.1-8B and Mistral 7B. All LLMs except Claude exhibit attack success rates above 87% in three categories. We also find Claude 3.5 Sonnet the safest, but it still displays biases in seven of eight categories. Despite being an optimized version of GPT4, We find GPT-4o to be more prone to biases and jailbreaks, suggesting optimization flaws. Our findings underscore the pressing need for more robust bias mitigation strategies and strengthened security measures in LLMs.
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
Advances in Preference-based Reinforcement Learning: A Review
Aug 21, 2024
Reinforcement Learning (RL) algorithms suffer from the dependency on accurately engineered reward functions to properly guide the learning agents to do the required tasks. Preference-based reinforcement learning (PbRL) addresses that by utilizing human preferences as feedback from the experts instead of numeric rewards. Due to its promising advantage over traditional RL, PbRL has gained more focus in recent years with many significant advances. In this survey, we present a unified PbRL framework to include the newly emerging approaches that improve the scalability and efficiency of PbRL. In addition, we give a detailed overview of the theoretical guarantees and benchmarking work done in the field, while presenting its recent applications in complex real-world tasks. Lastly, we go over the limitations of the current approaches and the proposed future research directions.
Exploring the Limitations of Detecting Machine-Generated Text
Jun 16, 2024



Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Jun 14, 2024



Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.