 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSKV: Training-Efficient Channel Shrinking for KV Cache in Long-Context Scenarios
Sep 16, 2024



Large Language Models (LLMs) have been widely adopted to process long-context tasks. However, the large memory overhead of the key-value (KV) cache poses significant challenges in long-context scenarios. Existing training-free KV cache compression methods typically focus on quantization and token pruning, which have compression limits, and excessive sparsity can lead to severe performance degradation. Other methods design new architectures with less KV overhead but require significant training overhead. To address the above two drawbacks, we further explore the redundancy in the channel dimension and apply an architecture-level design with minor training costs. Therefore, we introduce CSKV, a training-efficient Channel Shrinking technique for KV cache compression: (1) We first analyze the singular value distribution of the KV cache, revealing significant redundancy and compression potential along the channel dimension. Based on this observation, we propose using low-rank decomposition for key and value layers and storing the low-dimension features. (2) To preserve model performance, we introduce a bi-branch KV cache, including a window-based full-precision KV cache and a low-precision compressed KV cache. (3) To reduce the training costs, we minimize the layer-wise reconstruction loss for the compressed KV cache instead of retraining the entire LLMs. Extensive experiments show that CSKV can reduce the memory overhead of the KV cache by 80% while maintaining the model's long-context capability. Moreover, we show that our method can be seamlessly combined with quantization to further reduce the memory overhead, achieving a compression ratio of up to 95%.
Joint Universal Adversarial Perturbations with Interpretations
Aug 03, 2024



Deep neural networks (DNNs) have significantly boosted the performance of many challenging tasks. Despite the great development, DNNs have also exposed their vulnerability. Recent studies have shown that adversaries can manipulate the predictions of DNNs by adding a universal adversarial perturbation (UAP) to benign samples. On the other hand, increasing efforts have been made to help users understand and explain the inner working of DNNs by highlighting the most informative parts (i.e., attribution maps) of samples with respect to their predictions. Moreover, we first empirically find that such attribution maps between benign and adversarial examples have a significant discrepancy, which has the potential to detect universal adversarial perturbations for defending against adversarial attacks. This finding motivates us to further investigate a new research problem: whether there exist universal adversarial perturbations that are able to jointly attack DNNs classifier and its interpretation with malicious desires. It is challenging to give an explicit answer since these two objectives are seemingly conflicting. In this paper, we propose a novel attacking framework to generate joint universal adversarial perturbations (JUAP), which can fool the DNNs model and misguide the inspection from interpreters simultaneously. Comprehensive experiments on various datasets demonstrate the effectiveness of the proposed method JUAP for joint attacks. To the best of our knowledge, this is the first effort to study UAP for jointly attacking both DNNs and interpretations.
A Survey on Efficient Inference for Large Language Models
Apr 22, 2024Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
Evaluating Quantized Large Language Models
Feb 28, 2024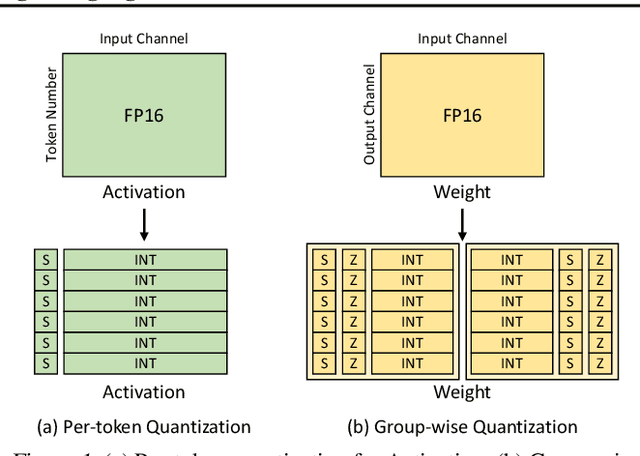



Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions.
A Causal Framework to Unify Common Domain Generalization Approaches
Jul 13, 2023



Domain generalization (DG) is about learning models that generalize well to new domains that are related to, but different from, the training domain(s). It is a fundamental problem in machine learning and has attracted much attention in recent years. A large number of approaches have been proposed. Different approaches are motivated from different perspectives, making it difficult to gain an overall understanding of the area. In this paper, we propose a causal framework for domain generalization and present an understanding of common DG approaches in the framework. Our work sheds new lights on the following questions: (1) What are the key ideas behind each DG method? (2) Why is it expected to improve generalization to new domains theoretically? (3) How are different DG methods related to each other and what are relative advantages and limitations? By providing a unified perspective on DG, we hope to help researchers better understand the underlying principles and develop more effective approaches for this critical problem in machine learning.
Model Debiasing via Gradient-based Explanation on Representation
May 20, 2023



Machine learning systems produce biased results towards certain demographic groups, known as the fairness problem. Recent approaches to tackle this problem learn a latent code (i.e., representation) through disentangled representation learning and then discard the latent code dimensions correlated with sensitive attributes (e.g., gender). Nevertheless, these approaches may suffer from incomplete disentanglement and overlook proxy attributes (proxies for sensitive attributes) when processing real-world data, especially for unstructured data, causing performance degradation in fairness and loss of useful information for downstream tasks. In this paper, we propose a novel fairness framework that performs debiasing with regard to both sensitive attributes and proxy attributes, which boosts the prediction performance of downstream task models without complete disentanglement. The main idea is to, first, leverage gradient-based explanation to find two model focuses, 1) one focus for predicting sensitive attributes and 2) the other focus for predicting downstream task labels, and second, use them to perturb the latent code that guides the training of downstream task models towards fairness and utility goals. We show empirically that our framework works with both disentangled and non-disentangled representation learning methods and achieves better fairness-accuracy trade-off on unstructured and structured datasets than previous state-of-the-art approaches.
Contrastive Domain Generalization via Logit Attribution Matching
May 13, 2023



Domain Generalization (DG) is an important open problem in machine learning. Deep models are susceptible to domain shifts of even minute degrees, which severely compromises their reliability in real applications. To alleviate the issue, most existing methods enforce various invariant constraints across multiple training domains. However,such an approach provides little performance guarantee for novel test domains in general. In this paper, we investigate a different approach named Contrastive Domain Generalization (CDG), which exploits semantic invariance exhibited by strongly contrastive data pairs in lieu of multiple domains. We present a causal DG theory that shows the potential capability of CDG; together with a regularization technique, Logit Attribution Matching (LAM), for realizing CDG. We empirically show that LAM outperforms state-of-the-art DG methods with only a small portion of paired data and that LAM helps models better focus on semantic features which are crucial to DG.