 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023



Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.
Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone
Oct 30, 2023Parameter-efficient tuning has become a trend in transferring large-scale foundation models to downstream applications. Existing methods typically embed some light-weight tuners into the backbone, where both the design and the learning of the tuners are highly dependent on the base model. This work offers a new tuning paradigm, dubbed Res-Tuning, which intentionally unbinds tuners from the backbone. With both theoretical and empirical evidence, we show that popular tuning approaches have their equivalent counterparts under our unbinding formulation, and hence can be integrated into our framework effortlessly. Thanks to the structural disentanglement, we manage to free the design of tuners from the network architecture, facilitating flexible combination of various tuning strategies. We further propose a memory-efficient variant of Res-Tuning, where the bypass i.e., formed by a sequence of tuners) is effectively detached from the main branch, such that the gradients are back-propagated only to the tuners but not to the backbone. Such a detachment also allows one-time backbone forward for multi-task inference. Extensive experiments on both discriminative and generative tasks demonstrate the superiority of our method over existing alternatives from the perspectives of efficacy and efficiency. Project page: $\href{https://res-tuning.github.io/}{\textit{https://res-tuning.github.io/}}$.
Disentangling Spatial and Temporal Learning for Efficient Image-to-Video Transfer Learning
Sep 14, 2023



Recently, large-scale pre-trained language-image models like CLIP have shown extraordinary capabilities for understanding spatial contents, but naively transferring such models to video recognition still suffers from unsatisfactory temporal modeling capabilities. Existing methods insert tunable structures into or in parallel with the pre-trained model, which either requires back-propagation through the whole pre-trained model and is thus resource-demanding, or is limited by the temporal reasoning capability of the pre-trained structure. In this work, we present DiST, which disentangles the learning of spatial and temporal aspects of videos. Specifically, DiST uses a dual-encoder structure, where a pre-trained foundation model acts as the spatial encoder, and a lightweight network is introduced as the temporal encoder. An integration branch is inserted between the encoders to fuse spatio-temporal information. The disentangled spatial and temporal learning in DiST is highly efficient because it avoids the back-propagation of massive pre-trained parameters. Meanwhile, we empirically show that disentangled learning with an extra network for integration benefits both spatial and temporal understanding. Extensive experiments on five benchmarks show that DiST delivers better performance than existing state-of-the-art methods by convincing gaps. When pre-training on the large-scale Kinetics-710, we achieve 89.7% on Kinetics-400 with a frozen ViT-L model, which verifies the scalability of DiST. Codes and models can be found in https://github.com/alibaba-mmai-research/DiST.
Towards Real-World Visual Tracking with Temporal Contexts
Aug 20, 2023Visual tracking has made significant improvements in the past few decades. Most existing state-of-the-art trackers 1) merely aim for performance in ideal conditions while overlooking the real-world conditions; 2) adopt the tracking-by-detection paradigm, neglecting rich temporal contexts; 3) only integrate the temporal information into the template, where temporal contexts among consecutive frames are far from being fully utilized. To handle those problems, we propose a two-level framework (TCTrack) that can exploit temporal contexts efficiently. Based on it, we propose a stronger version for real-world visual tracking, i.e., TCTrack++. It boils down to two levels: features and similarity maps. Specifically, for feature extraction, we propose an attention-based temporally adaptive convolution to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights. For similarity map refinement, we introduce an adaptive temporal transformer to encode the temporal knowledge efficiently and decode it for the accurate refinement of the similarity map. To further improve the performance, we additionally introduce a curriculum learning strategy. Also, we adopt online evaluation to measure performance in real-world conditions. Exhaustive experiments on 8 wellknown benchmarks demonstrate the superiority of TCTrack++. Real-world tests directly verify that TCTrack++ can be readily used in real-world applications.
Temporally-Adaptive Models for Efficient Video Understanding
Aug 10, 2023Spatial convolutions are extensively used in numerous deep video models. It fundamentally assumes spatio-temporal invariance, i.e., using shared weights for every location in different frames. This work presents Temporally-Adaptive Convolutions (TAdaConv) for video understanding, which shows that adaptive weight calibration along the temporal dimension is an efficient way to facilitate modeling complex temporal dynamics in videos. Specifically, TAdaConv empowers spatial convolutions with temporal modeling abilities by calibrating the convolution weights for each frame according to its local and global temporal context. Compared to existing operations for temporal modeling, TAdaConv is more efficient as it operates over the convolution kernels instead of the features, whose dimension is an order of magnitude smaller than the spatial resolutions. Further, kernel calibration brings an increased model capacity. Based on this readily plug-in operation TAdaConv as well as its extension, i.e., TAdaConvV2, we construct TAdaBlocks to empower ConvNeXt and Vision Transformer to have strong temporal modeling capabilities. Empirical results show TAdaConvNeXtV2 and TAdaFormer perform competitively against state-of-the-art convolutional and Transformer-based models in various video understanding benchmarks. Our codes and models are released at: https://github.com/alibaba-mmai-research/TAdaConv.
Rethinking Efficient Tuning Methods from a Unified Perspective
Mar 01, 2023Parameter-efficient transfer learning (PETL) based on large-scale pre-trained foundation models has achieved great success in various downstream applications. Existing tuning methods, such as prompt, prefix, and adapter, perform task-specific lightweight adjustments to different parts of the original architecture. However, they take effect on only some parts of the pre-trained models, i.e., only the feed-forward layers or the self-attention layers, which leaves the remaining frozen structures unable to adapt to the data distributions of downstream tasks. Further, the existing structures are strongly coupled with the Transformers, hindering parameter-efficient deployment as well as the design flexibility for new approaches. In this paper, we revisit the design paradigm of PETL and derive a unified framework U-Tuning for parameter-efficient transfer learning, which is composed of an operation with frozen parameters and a unified tuner that adapts the operation for downstream applications. The U-Tuning framework can simultaneously encompass existing methods and derive new approaches for parameter-efficient transfer learning, which prove to achieve on-par or better performances on CIFAR-100 and FGVC datasets when compared with existing PETL methods.
Physically Plausible Animation of Human Upper Body from a Single Image
Dec 09, 2022



We present a new method for generating controllable, dynamically responsive, and photorealistic human animations. Given an image of a person, our system allows the user to generate Physically plausible Upper Body Animation (PUBA) using interaction in the image space, such as dragging their hand to various locations. We formulate a reinforcement learning problem to train a dynamic model that predicts the person's next 2D state (i.e., keypoints on the image) conditioned on a 3D action (i.e., joint torque), and a policy that outputs optimal actions to control the person to achieve desired goals. The dynamic model leverages the expressiveness of 3D simulation and the visual realism of 2D videos. PUBA generates 2D keypoint sequences that achieve task goals while being responsive to forceful perturbation. The sequences of keypoints are then translated by a pose-to-image generator to produce the final photorealistic video.
Progressive Learning without Forgetting
Nov 28, 2022



Learning from changing tasks and sequential experience without forgetting the obtained knowledge is a challenging problem for artificial neural networks. In this work, we focus on two challenging problems in the paradigm of Continual Learning (CL) without involving any old data: (i) the accumulation of catastrophic forgetting caused by the gradually fading knowledge space from which the model learns the previous knowledge; (ii) the uncontrolled tug-of-war dynamics to balance the stability and plasticity during the learning of new tasks. In order to tackle these problems, we present Progressive Learning without Forgetting (PLwF) and a credit assignment regime in the optimizer. PLwF densely introduces model functions from previous tasks to construct a knowledge space such that it contains the most reliable knowledge on each task and the distribution information of different tasks, while credit assignment controls the tug-of-war dynamics by removing gradient conflict through projection. Extensive ablative experiments demonstrate the effectiveness of PLwF and credit assignment. In comparison with other CL methods, we report notably better results even without relying on any raw data.
PVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework
Nov 21, 2022



Visual object tracking is an essential capability of intelligent robots. Most existing approaches have ignored the online latency that can cause severe performance degradation during real-world processing. Especially for unmanned aerial vehicle, where robust tracking is more challenging and onboard computation is limited, latency issue could be fatal. In this work, we present a simple framework for end-to-end latency-aware tracking, i.e., end-to-end predictive visual tracking (PVT++). PVT++ is capable of turning most leading-edge trackers into predictive trackers by appending an online predictor. Unlike existing solutions that use model-based approaches, our framework is learnable, such that it can take not only motion information as input but it can also take advantage of visual cues or a combination of both. Moreover, since PVT++ is end-to-end optimizable, it can further boost the latency-aware tracking performance by joint training. Additionally, this work presents an extended latency-aware evaluation benchmark for assessing an any-speed tracker in the online setting. Empirical results on robotic platform from aerial perspective show that PVT++ can achieve up to 60% performance gain on various trackers and exhibit better robustness than prior model-based solution, largely mitigating the degradation brought by latency. Code and models will be made public.
RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection
Sep 05, 2022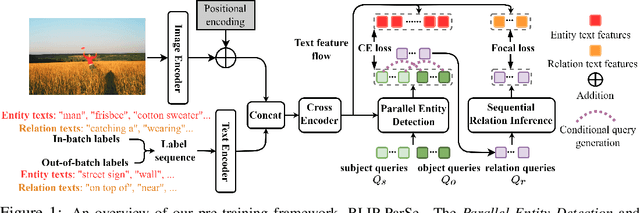
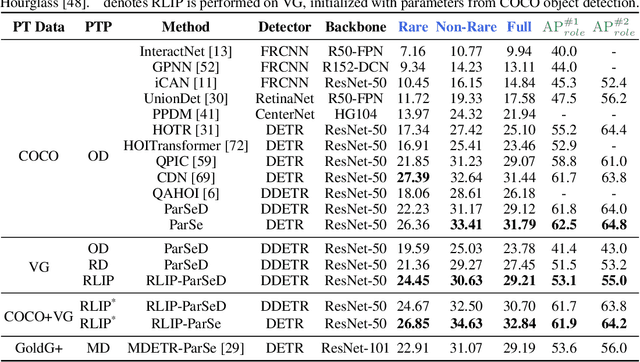
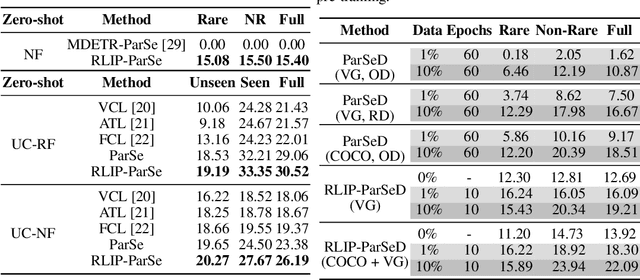

The task of Human-Object Interaction (HOI) detection targets fine-grained visual parsing of humans interacting with their environment, enabling a broad range of applications. Prior work has demonstrated the benefits of effective architecture design and integration of relevant cues for more accurate HOI detection. However, the design of an appropriate pre-training strategy for this task remains underexplored by existing approaches. To address this gap, we propose Relational Language-Image Pre-training (RLIP), a strategy for contrastive pre-training that leverages both entity and relation descriptions. To make effective use of such pre-training, we make three technical contributions: (1) a new Parallel entity detection and Sequential relation inference (ParSe) architecture that enables the use of both entity and relation descriptions during holistically optimized pre-training; (2) a synthetic data generation framework, Label Sequence Extension, that expands the scale of language data available within each minibatch; (3) mechanisms to account for ambiguity, Relation Quality Labels and Relation Pseudo-Labels, to mitigate the influence of ambiguous/noisy samples in the pre-training data. Through extensive experiments, we demonstrate the benefits of these contributions, collectively termed RLIP-ParSe, for improved zero-shot, few-shot and fine-tuning HOI detection performance as well as increased robustness to learning from noisy annotations. Code will be available at \url{https://github.com/JacobYuan7/RLIP}.