 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADD: Physics-Based Motion Imitation with Adversarial Differential Discriminators
May 08, 2025



Multi-objective optimization problems, which require the simultaneous optimization of multiple terms, are prevalent across numerous applications. Existing multi-objective optimization methods often rely on manually tuned aggregation functions to formulate a joint optimization target. The performance of such hand-tuned methods is heavily dependent on careful weight selection, a time-consuming and laborious process. These limitations also arise in the setting of reinforcement-learning-based motion tracking for physically simulated characters, where intricately crafted reward functions are typically used to achieve high-fidelity results. Such solutions not only require domain expertise and significant manual adjustment, but also limit the applicability of the resulting reward function across diverse skills. To bridge this gap, we present a novel adversarial multi-objective optimization technique that is broadly applicable to a range of multi-objective optimization problems, including motion tracking. The proposed adversarial differential discriminator receives a single positive sample, yet is still effective at guiding the optimization process. We demonstrate that our technique can enable characters to closely replicate a variety of acrobatic and agile behaviors, achieving comparable quality to state-of-the-art motion-tracking methods, without relying on manually tuned reward functions. Results are best visualized through https://youtu.be/rz8BYCE9E2w.
Learning Bipedal Robot Locomotion from Human Movement
May 26, 2021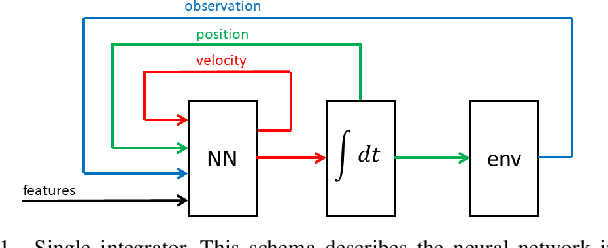
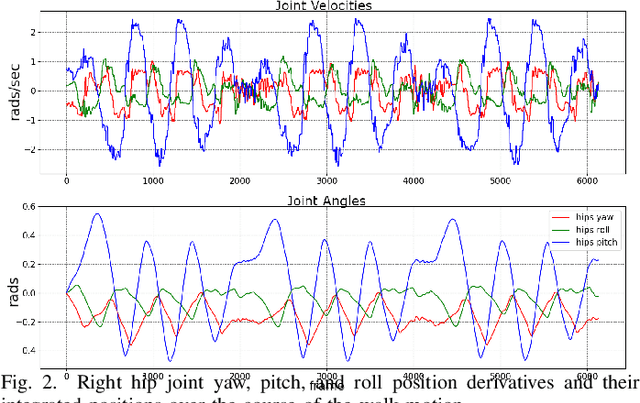
Teaching an anthropomorphic robot from human example offers the opportunity to impart humanlike qualities on its movement. In this work we present a reinforcement learning based method for teaching a real world bipedal robot to perform movements directly from human motion capture data. Our method seamlessly transitions from training in a simulation environment to executing on a physical robot without requiring any real world training iterations or offline steps. To overcome the disparity in joint configurations between the robot and the motion capture actor, our method incorporates motion re-targeting into the training process. Domain randomization techniques are used to compensate for the differences between the simulated and physical systems. We demonstrate our method on an internally developed humanoid robot with movements ranging from a dynamic walk cycle to complex balancing and waving. Our controller preserves the style imparted by the motion capture data and exhibits graceful failure modes resulting in safe operation for the robot. This work was performed for research purposes only.