 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes
Jun 06, 2025Constructing real-world data-to-insight pipelines often involves data extraction from data lakes, data integration across heterogeneous data sources, and diverse operations from data cleaning to analysis. The design and implementation of data science pipelines require domain knowledge, technical expertise, and even project-specific insights. AI systems have shown remarkable reasoning, coding, and understanding capabilities. However, it remains unclear to what extent these capabilities translate into successful design and execution of such complex pipelines. We introduce KRAMABENCH: a benchmark composed of 104 manually-curated real-world data science pipelines spanning 1700 data files from 24 data sources in 6 different domains. We show that these pipelines test the end-to-end capabilities of AI systems on data processing, requiring data discovery, wrangling and cleaning, efficient processing, statistical reasoning, and orchestrating data processing steps given a high-level task. Our evaluation tests 5 general models and 3 code generation models using our reference framework, DS-GURU, which instructs the AI model to decompose a question into a sequence of subtasks, reason through each step, and synthesize Python code that implements the proposed design. Our results on KRAMABENCH show that, although the models are sufficiently capable of solving well-specified data science code generation tasks, when extensive data processing and domain knowledge are required to construct real-world data science pipelines, existing out-of-box models fall short. Progress on KramaBench represents crucial steps towards developing autonomous data science agents for real-world applications. Our code, reference framework, and data are available at https://github.com/mitdbg/KramaBench.
Abacus: A Cost-Based Optimizer for Semantic Operator Systems
May 20, 2025LLMs enable an exciting new class of data processing applications over large collections of unstructured documents. Several new programming frameworks have enabled developers to build these applications by composing them out of semantic operators: a declarative set of AI-powered data transformations with natural language specifications. These include LLM-powered maps, filters, joins, etc. used for document processing tasks such as information extraction, summarization, and more. While systems of semantic operators have achieved strong performance on benchmarks, they can be difficult to optimize. An optimizer for this setting must determine how to physically implement each semantic operator in a way that optimizes the system globally. Existing optimizers are limited in the number of optimizations they can apply, and most (if not all) cannot optimize system quality, cost, or latency subject to constraint(s) on the other dimensions. In this paper we present Abacus, an extensible, cost-based optimizer which searches for the best implementation of a semantic operator system given a (possibly constrained) optimization objective. Abacus estimates operator performance by leveraging a minimal set of validation examples and, if available, prior beliefs about operator performance. We evaluate Abacus on document processing workloads in the biomedical and legal domains (BioDEX; CUAD) and multi-modal question answering (MMQA). We demonstrate that systems optimized by Abacus achieve 18.7%-39.2% better quality and up to 23.6x lower cost and 4.2x lower latency than the next best system.
PalimpChat: Declarative and Interactive AI analytics
Feb 05, 2025



Thanks to the advances in generative architectures and large language models, data scientists can now code pipelines of machine-learning operations to process large collections of unstructured data. Recent progress has seen the rise of declarative AI frameworks (e.g., Palimpzest, Lotus, and DocETL) to build optimized and increasingly complex pipelines, but these systems often remain accessible only to expert programmers. In this demonstration, we present PalimpChat, a chat-based interface to Palimpzest that bridges this gap by letting users create and run sophisticated AI pipelines through natural language alone. By integrating Archytas, a ReAct-based reasoning agent, and Palimpzest's suite of relational and LLM-based operators, PalimpChat provides a practical illustration of how a chat interface can make declarative AI frameworks truly accessible to non-experts. Our demo system is publicly available online. At SIGMOD'25, participants can explore three real-world scenarios--scientific discovery, legal discovery, and real estate search--or apply PalimpChat to their own datasets. In this paper, we focus on how PalimpChat, supported by the Palimpzest optimizer, simplifies complex AI workflows such as extracting and analyzing biomedical data.
A Declarative System for Optimizing AI Workloads
May 23, 2024



Modern AI models provide the key to a long-standing dream: processing analytical queries about almost any kind of data. Until recently, it was difficult and expensive to extract facts from company documents, data from scientific papers, or insights from image and video corpora. Today's models can accomplish these tasks with high accuracy. However, a programmer who wants to answer a substantive AI-powered query must orchestrate large numbers of models, prompts, and data operations. For even a single query, the programmer has to make a vast number of decisions such as the choice of model, the right inference method, the most cost-effective inference hardware, the ideal prompt design, and so on. The optimal set of decisions can change as the query changes and as the rapidly-evolving technical landscape shifts. In this paper we present Palimpzest, a system that enables anyone to process AI-powered analytical queries simply by defining them in a declarative language. The system uses its cost optimization framework -- which explores the search space of AI models, prompting techniques, and related foundation model optimizations -- to implement the query with the best trade-offs between runtime, financial cost, and output data quality. We describe the workload of AI-powered analytics tasks, the optimization methods that Palimpzest uses, and the prototype system itself. We evaluate Palimpzest on tasks in Legal Discovery, Real Estate Search, and Medical Schema Matching. We show that even our simple prototype offers a range of appealing plans, including one that is 3.3x faster, 2.9x cheaper, and offers better data quality than the baseline method. With parallelism enabled, Palimpzest can produce plans with up to a 90.3x speedup at 9.1x lower cost relative to a single-threaded GPT-4 baseline, while obtaining an F1-score within 83.5% of the baseline. These require no additional work by the user.
Detecting Layout Templates in Complex Multiregion Files
Sep 15, 2021
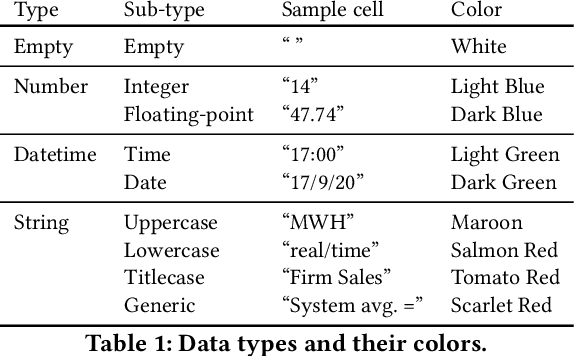
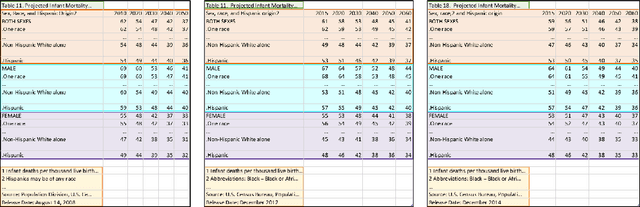

Spreadsheets are among the most commonly used file formats for data management, distribution, and analysis. Their widespread employment makes it easy to gather large collections of data, but their flexible canvas-based structure makes automated analysis difficult without heavy preparation. One of the common problems that practitioners face is the presence of multiple, independent regions in a single spreadsheet, possibly separated by repeated empty cells. We define such files as "multiregion" files. In collections of various spreadsheets, we can observe that some share the same layout. We present the Mondrian approach to automatically identify layout templates across multiple files and systematically extract the corresponding regions. Our approach is composed of three phases: first, each file is rendered as an image and inspected for elements that could form regions; then, using a clustering algorithm, the identified elements are grouped to form regions; finally, every file layout is represented as a graph and compared with others to find layout templates. We compare our method to state-of-the-art table recognition algorithms on two corpora of real-world enterprise spreadsheets. Our approach shows the best performances in detecting reliable region boundaries within each file and can correctly identify recurring layouts across files.