 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancingBox: A Lightweight MoCap System for Character Animation from Physical Proxies
Mar 18, 2026Creating compelling 3D character animations typically requires either expert use of professional software or expensive motion capture systems operated by skilled actors. We present DancingBox, a lightweight, vision-based system that makes motion capture accessible to novices by reimagining the process as digital puppetry. Instead of tracking precise human motions, DancingBox captures the approximate movements of everyday objects manipulated by users with a single webcam. These coarse proxy motions are then refined into realistic character animations by conditioning a generative motion model on bounding-box representations, enriched with human motion priors learned from large-scale datasets. To overcome the lack of paired proxy-animation data, we synthesize training pairs by converting existing motion capture sequences into proxy representations. A user study demonstrates that DancingBox enables intuitive and creative character animation using diverse proxies, from plush toys to bananas, lowering the barrier to entry for novice animators.
Seeking Physics in Diffusion Noise
Mar 15, 2026Do video diffusion models encode signals predictive of physical plausibility? We probe intermediate denoising representations of a pretrained Diffusion Transformer (DiT) and find that physically plausible and implausible videos are partially separable in mid-layer feature space across noise levels. This separability cannot be fully attributed to visual quality or generator identity, suggesting recoverable physics-related cues in frozen DiT features. Leveraging this observation, we introduce progressive trajectory selection, an inference-time strategy that scores parallel denoising trajectories at a few intermediate checkpoints using a lightweight physics verifier trained on frozen features, and prunes low-scoring candidates early. Extensive experiments on PhyGenBench demonstrate that our method improves physical consistency while reducing inference cost, achieving comparable results to Best-of-K sampling with substantially fewer denoising steps.
SMooGPT: Stylized Motion Generation using Large Language Models
Sep 04, 2025Stylized motion generation is actively studied in computer graphics, especially benefiting from the rapid advances in diffusion models. The goal of this task is to produce a novel motion respecting both the motion content and the desired motion style, e.g., ``walking in a loop like a Monkey''. Existing research attempts to address this problem via motion style transfer or conditional motion generation. They typically embed the motion style into a latent space and guide the motion implicitly in a latent space as well. Despite the progress, their methods suffer from low interpretability and control, limited generalization to new styles, and fail to produce motions other than ``walking'' due to the strong bias in the public stylization dataset. In this paper, we propose to solve the stylized motion generation problem from a new perspective of reasoning-composition-generation, based on our observations: i) human motion can often be effectively described using natural language in a body-part centric manner, ii) LLMs exhibit a strong ability to understand and reason about human motion, and iii) human motion has an inherently compositional nature, facilitating the new motion content or style generation via effective recomposing. We thus propose utilizing body-part text space as an intermediate representation, and present SMooGPT, a fine-tuned LLM, acting as a reasoner, composer, and generator when generating the desired stylized motion. Our method executes in the body-part text space with much higher interpretability, enabling fine-grained motion control, effectively resolving potential conflicts between motion content and style, and generalizes well to new styles thanks to the open-vocabulary ability of LLMs. Comprehensive experiments and evaluations, and a user perceptual study, demonstrate the effectiveness of our approach, especially under the pure text-driven stylized motion generation.
Sketch2Anim: Towards Transferring Sketch Storyboards into 3D Animation
Apr 27, 2025



Storyboarding is widely used for creating 3D animations. Animators use the 2D sketches in storyboards as references to craft the desired 3D animations through a trial-and-error process. The traditional approach requires exceptional expertise and is both labor-intensive and time-consuming. Consequently, there is a high demand for automated methods that can directly translate 2D storyboard sketches into 3D animations. This task is under-explored to date and inspired by the significant advancements of motion diffusion models, we propose to address it from the perspective of conditional motion synthesis. We thus present Sketch2Anim, composed of two key modules for sketch constraint understanding and motion generation. Specifically, due to the large domain gap between the 2D sketch and 3D motion, instead of directly conditioning on 2D inputs, we design a 3D conditional motion generator that simultaneously leverages 3D keyposes, joint trajectories, and action words, to achieve precise and fine-grained motion control. Then, we invent a neural mapper dedicated to aligning user-provided 2D sketches with their corresponding 3D keyposes and trajectories in a shared embedding space, enabling, for the first time, direct 2D control of motion generation. Our approach successfully transfers storyboards into high-quality 3D motions and inherently supports direct 3D animation editing, thanks to the flexibility of our multi-conditional motion generator. Comprehensive experiments and evaluations, and a user perceptual study demonstrate the effectiveness of our approach.
PoseTraj: Pose-Aware Trajectory Control in Video Diffusion
Mar 20, 2025



Recent advancements in trajectory-guided video generation have achieved notable progress. However, existing models still face challenges in generating object motions with potentially changing 6D poses under wide-range rotations, due to limited 3D understanding. To address this problem, we introduce PoseTraj, a pose-aware video dragging model for generating 3D-aligned motion from 2D trajectories. Our method adopts a novel two-stage pose-aware pretraining framework, improving 3D understanding across diverse trajectories. Specifically, we propose a large-scale synthetic dataset PoseTraj-10K, containing 10k videos of objects following rotational trajectories, and enhance the model perception of object pose changes by incorporating 3D bounding boxes as intermediate supervision signals. Following this, we fine-tune the trajectory-controlling module on real-world videos, applying an additional camera-disentanglement module to further refine motion accuracy. Experiments on various benchmark datasets demonstrate that our method not only excels in 3D pose-aligned dragging for rotational trajectories but also outperforms existing baselines in trajectory accuracy and video quality.
MulSMo: Multimodal Stylized Motion Generation by Bidirectional Control Flow
Dec 13, 2024Generating motion sequences conforming to a target style while adhering to the given content prompts requires accommodating both the content and style. In existing methods, the information usually only flows from style to content, which may cause conflict between the style and content, harming the integration. Differently, in this work we build a bidirectional control flow between the style and the content, also adjusting the style towards the content, in which case the style-content collision is alleviated and the dynamics of the style is better preserved in the integration. Moreover, we extend the stylized motion generation from one modality, i.e. the style motion, to multiple modalities including texts and images through contrastive learning, leading to flexible style control on the motion generation. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, while also enabling multimodal signals control. The code of our method will be made publicly available.
SMooDi: Stylized Motion Diffusion Model
Jul 17, 2024



We introduce a novel Stylized Motion Diffusion model, dubbed SMooDi, to generate stylized motion driven by content texts and style motion sequences. Unlike existing methods that either generate motion of various content or transfer style from one sequence to another, SMooDi can rapidly generate motion across a broad range of content and diverse styles. To this end, we tailor a pre-trained text-to-motion model for stylization. Specifically, we propose style guidance to ensure that the generated motion closely matches the reference style, alongside a lightweight style adaptor that directs the motion towards the desired style while ensuring realism. Experiments across various applications demonstrate that our proposed framework outperforms existing methods in stylized motion generation.
Performance analysis for a rotary compressor at high speed: experimental study and mathematical modeling
Jul 13, 2024This paper conducted a comprehensive study on the performance of a rotary compressor over a rotational speed range of 80Hz to 200Hz through experimental tests and mathematical modeling. A compressor performance test rig was designed to conduct the performance tests, with fast-response pressure sensors and displacement sensors capturing the P-V diagram and dynamic motion of the moving components. Results show that the compressor efficiency degrades at high speeds due to the dominant loss factors of leakage and discharge power loss. Supercharging effects become significant at speeds above 160Hz, and its net effects reduce the compressor efficiency, especially at high speeds. This study identifies and analyzes the loss factors on the mass flow rate and power consumption based on experimental data, and hypothesizes possible mechanisms for each loss factor, which can aid in the design of a high-speed rotary compressor with higher efficiency.
OmniControl: Control Any Joint at Any Time for Human Motion Generation
Oct 12, 2023



We present a novel approach named OmniControl for incorporating flexible spatial control signals into a text-conditioned human motion generation model based on the diffusion process. Unlike previous methods that can only control the pelvis trajectory, OmniControl can incorporate flexible spatial control signals over different joints at different times with only one model. Specifically, we propose analytic spatial guidance that ensures the generated motion can tightly conform to the input control signals. At the same time, realism guidance is introduced to refine all the joints to generate more coherent motion. Both the spatial and realism guidance are essential and they are highly complementary for balancing control accuracy and motion realism. By combining them, OmniControl generates motions that are realistic, coherent, and consistent with the spatial constraints. Experiments on HumanML3D and KIT-ML datasets show that OmniControl not only achieves significant improvement over state-of-the-art methods on pelvis control but also shows promising results when incorporating the constraints over other joints.
Article Reranking by Memory-Enhanced Key Sentence Matching for Detecting Previously Fact-Checked Claims
Dec 20, 2021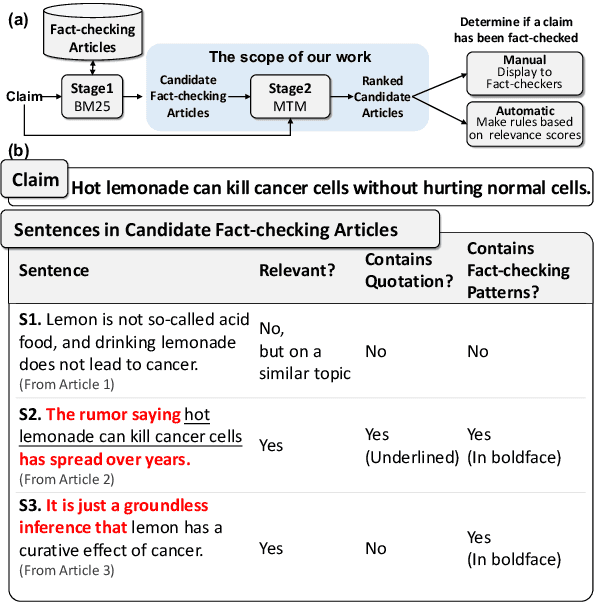
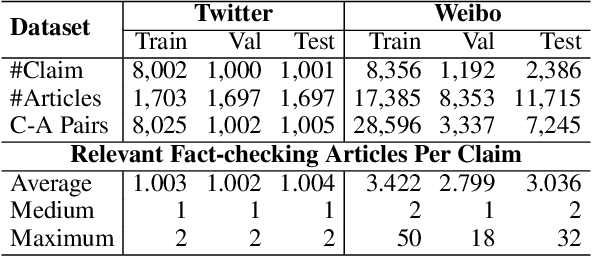
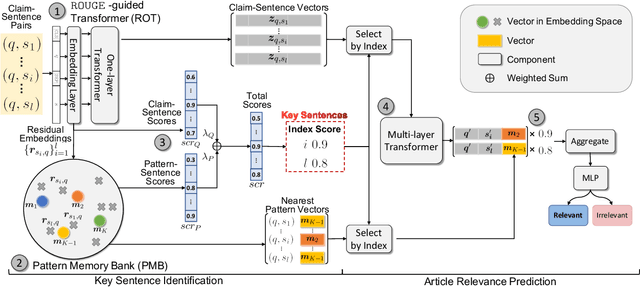
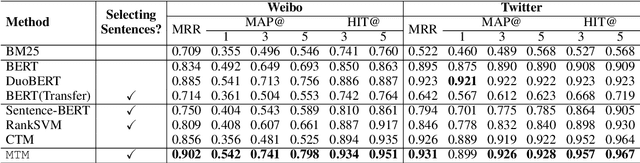
False claims that have been previously fact-checked can still spread on social media. To mitigate their continual spread, detecting previously fact-checked claims is indispensable. Given a claim, existing works focus on providing evidence for detection by reranking candidate fact-checking articles (FC-articles) retrieved by BM25. However, these performances may be limited because they ignore the following characteristics of FC-articles: (1) claims are often quoted to describe the checked events, providing lexical information besides semantics; (2) sentence templates to introduce or debunk claims are common across articles, providing pattern information. Models that ignore the two aspects only leverage semantic relevance and may be misled by sentences that describe similar but irrelevant events. In this paper, we propose a novel reranker, MTM (Memory-enhanced Transformers for Matching) to rank FC-articles using key sentences selected with event (lexical and semantic) and pattern information. For event information, we propose a ROUGE-guided Transformer which is finetuned with regression of ROUGE. For pattern information, we generate pattern vectors for matching with sentences. By fusing event and pattern information, we select key sentences to represent an article and then predict if the article fact-checks the given claim using the claim, key sentences, and patterns. Experiments on two real-world datasets show that MTM outperforms existing methods. Human evaluation proves that MTM can capture key sentences for explanations. The code and the dataset are at https://github.com/ICTMCG/MTM.