 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Adaptive Synthesis and Compression for Enhanced Retrieval-Augmented Generation in Complex Domains
Aug 26, 2025



Large Language Models (LLMs) excel in language tasks but are prone to hallucinations and outdated knowledge. Retrieval-Augmented Generation (RAG) mitigates these by grounding LLMs in external knowledge. However, in complex domains involving multiple, lengthy, or conflicting documents, traditional RAG suffers from information overload and inefficient synthesis, leading to inaccurate and untrustworthy answers. To address this, we propose CASC (Context-Adaptive Synthesis and Compression), a novel framework that intelligently processes retrieved contexts. CASC introduces a Context Analyzer & Synthesizer (CAS) module, powered by a fine-tuned smaller LLM, which performs key information extraction, cross-document consistency checking and conflict resolution, and question-oriented structured synthesis. This process transforms raw, scattered information into a highly condensed, structured, and semantically rich context, significantly reducing the token count and cognitive load for the final Reader LLM. We evaluate CASC on SciDocs-QA, a new challenging multi-document question answering dataset designed for complex scientific domains with inherent redundancies and conflicts. Our extensive experiments demonstrate that CASC consistently outperforms strong baselines.
CoProSketch: Controllable and Progressive Sketch Generation with Diffusion Model
Apr 11, 2025
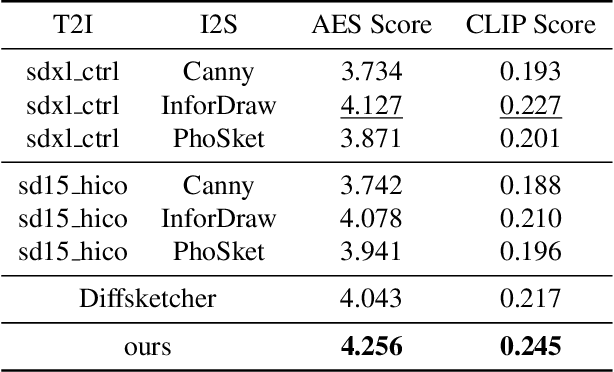
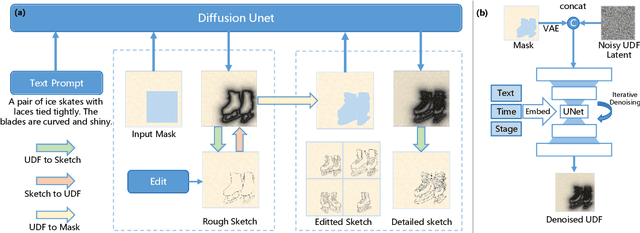
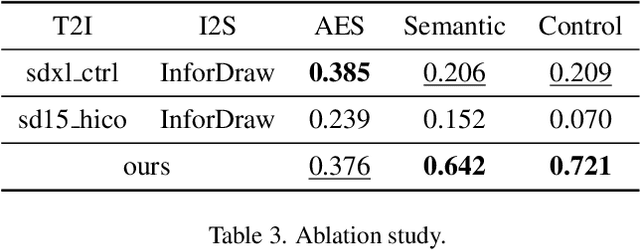
Sketches serve as fundamental blueprints in artistic creation because sketch editing is easier and more intuitive than pixel-level RGB image editing for painting artists, yet sketch generation remains unexplored despite advancements in generative models. We propose a novel framework CoProSketch, providing prominent controllability and details for sketch generation with diffusion models. A straightforward method is fine-tuning a pretrained image generation diffusion model with binarized sketch images. However, we find that the diffusion models fail to generate clear binary images, which makes the produced sketches chaotic. We thus propose to represent the sketches by unsigned distance field (UDF), which is continuous and can be easily decoded to sketches through a lightweight network. With CoProSketch, users generate a rough sketch from a bounding box and a text prompt. The rough sketch can be manually edited and fed back into the model for iterative refinement and will be decoded to a detailed sketch as the final result. Additionally, we curate the first large-scale text-sketch paired dataset as the training data. Experiments demonstrate superior semantic consistency and controllability over baselines, offering a practical solution for integrating user feedback into generative workflows.
InfinitePOD: Building Datacenter-Scale High-Bandwidth Domain for LLM with Optical Circuit Switching Transceivers
Feb 07, 2025



Scaling Large Language Model (LLM) training relies on multi-dimensional parallelism, where High-Bandwidth Domains (HBDs) are critical for communication-intensive parallelism like Tensor Parallelism (TP) and Expert Parallelism (EP). However, existing HBD architectures face fundamental limitations in scalability, cost, and fault resiliency: switch-centric HBDs (e.g., NVL-72) incur prohibitive scaling costs, while GPU-centric HBDs (e.g., TPUv3/Dojo) suffer from severe fault propagation. Switch-GPU hybrid HBDs such as TPUv4 takes a middle-ground approach by leveraging Optical Circuit Switches, but the fault explosion radius remains large at the cube level (e.g., 64 TPUs). We propose InfinitePOD, a novel transceiver-centric HBD architecture that unifies connectivity and dynamic switching at the transceiver level using Optical Circuit Switching (OCS). By embedding OCS within each transceiver, InfinitePOD achieves reconfigurable point-to-multipoint connectivity, allowing the topology to adapt into variable-size rings. This design provides: i) datacenter-wide scalability without cost explosion; ii) fault resilience by isolating failures to a single node, and iii) full bandwidth utilization for fault-free GPUs. Key innovations include a Silicon Photonic (SiPh) based low-cost OCS transceiver (OCSTrx), a reconfigurable k-hop ring topology co-designed with intra-/inter-node communication, and an HBD-DCN orchestration algorithm maximizing GPU utilization while minimizing cross-ToR datacenter network traffic. The evaluation demonstrates that InfinitePOD achieves 31% of the cost of NVL-72, near-zero GPU waste ratio (over one order of magnitude lower than NVL-72 and TPUv4), near-zero cross-ToR traffic when node fault ratios under 7%, and improves Model FLOPs Utilization by 3.37x compared to NVIDIA DGX (8 GPUs per Node).
BlinkVision: A Benchmark for Optical Flow, Scene Flow and Point Tracking Estimation using RGB Frames and Events
Oct 27, 2024Recent advances in event-based vision suggest that these systems complement traditional cameras by providing continuous observation without frame rate limitations and a high dynamic range, making them well-suited for correspondence tasks such as optical flow and point tracking. However, there is still a lack of comprehensive benchmarks for correspondence tasks that include both event data and images. To address this gap, we propose BlinkVision, a large-scale and diverse benchmark with multiple modalities and dense correspondence annotations. BlinkVision offers several valuable features: 1) Rich modalities: It includes both event data and RGB images. 2) Extensive annotations: It provides dense per-pixel annotations covering optical flow, scene flow, and point tracking. 3) Large vocabulary: It contains 410 everyday categories, sharing common classes with popular 2D and 3D datasets like LVIS and ShapeNet. 4) Naturalistic: It delivers photorealistic data and covers various naturalistic factors, such as camera shake and deformation. BlinkVision enables extensive benchmarks on three types of correspondence tasks (optical flow, point tracking, and scene flow estimation) for both image-based and event-based methods, offering new observations, practices, and insights for future research. The benchmark website is https://www.blinkvision.net/.
BlinkTrack: Feature Tracking over 100 FPS via Events and Images
Sep 26, 2024Feature tracking is crucial for, structure from motion (SFM), simultaneous localization and mapping (SLAM), object tracking and various computer vision tasks. Event cameras, known for their high temporal resolution and ability to capture asynchronous changes, have gained significant attention for their potential in feature tracking, especially in challenging conditions. However, event cameras lack the fine-grained texture information that conventional cameras provide, leading to error accumulation in tracking. To address this, we propose a novel framework, BlinkTrack, which integrates event data with RGB images for high-frequency feature tracking. Our method extends the traditional Kalman filter into a learning-based framework, utilizing differentiable Kalman filters in both event and image branches. This approach improves single-modality tracking, resolves ambiguities, and supports asynchronous data fusion. We also introduce new synthetic and augmented datasets to better evaluate our model. Experimental results indicate that BlinkTrack significantly outperforms existing event-based methods, exceeding 100 FPS with preprocessed event data and 80 FPS with multi-modality data.
Vector-Vector-Matrix Architecture: A Novel Hardware-Aware Framework for Low-Latency Inference in NLP Applications
Oct 06, 2020
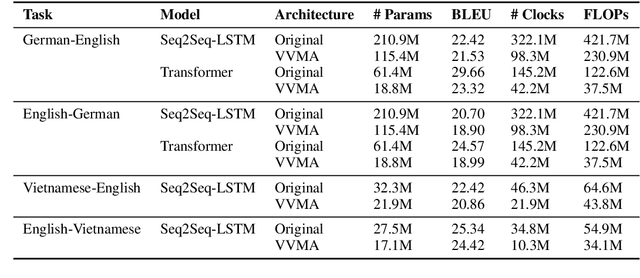
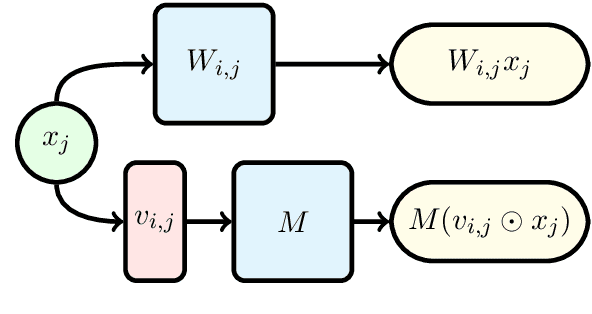
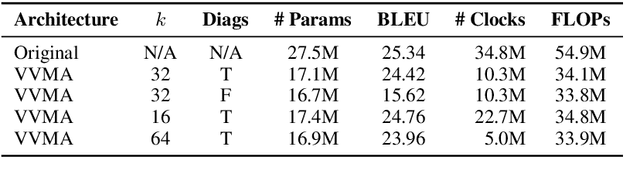
Deep neural networks have become the standard approach to building reliable Natural Language Processing (NLP) applications, ranging from Neural Machine Translation (NMT) to dialogue systems. However, improving accuracy by increasing the model size requires a large number of hardware computations, which can slow down NLP applications significantly at inference time. To address this issue, we propose a novel vector-vector-matrix architecture (VVMA), which greatly reduces the latency at inference time for NMT. This architecture takes advantage of specialized hardware that has low-latency vector-vector operations and higher-latency vector-matrix operations. It also reduces the number of parameters and FLOPs for virtually all models that rely on efficient matrix multipliers without significantly impacting accuracy. We present empirical results suggesting that our framework can reduce the latency of sequence-to-sequence and Transformer models used for NMT by a factor of four. Finally, we show evidence suggesting that our VVMA extends to other domains, and we discuss novel hardware for its efficient use.
Learning the Distribution: A Unified Distillation Paradigm for Fast Uncertainty Estimation in Computer Vision
Jul 31, 2020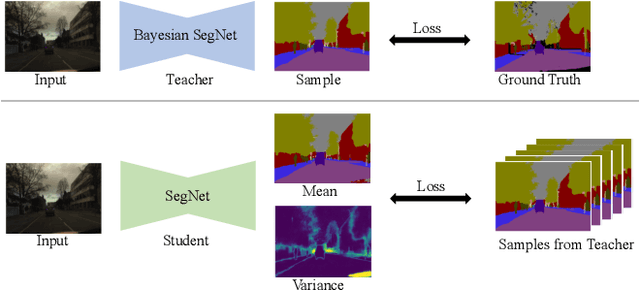
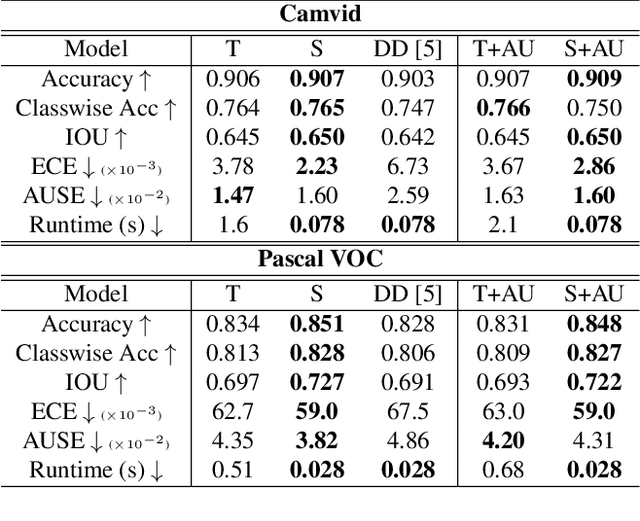

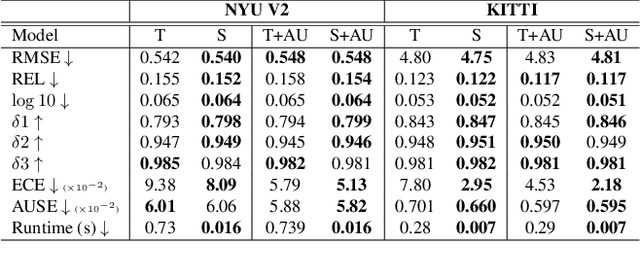
Calibrated estimates of uncertainty are critical for many real-world computer vision applications of deep learning. While there are several widely-used uncertainty estimation methods, dropout inference stands out for its simplicity and efficacy. This technique, however, requires multiple forward passes through the network during inference and therefore can be too resource-intensive to be deployed in real-time applications. To tackle this issue, we propose a unified distillation paradigm for learning the conditional predictive distribution of a pre-trained dropout model for fast uncertainty estimation of both aleatoric and epistemic uncertainty at the same time. We empirically test the effectiveness of the proposed method on both semantic segmentation and depth estimation tasks, and observe that the student model can well approximate the probability distribution generated by the teacher model, i.e the pre-trained dropout model. In addition to a significant boost in speed, we demonstrate the quality of uncertainty estimates and the overall predictive performance can also be improved with the proposed method.
Migrating Knowledge between Physical Scenarios based on Artificial Neural Networks
Aug 27, 2018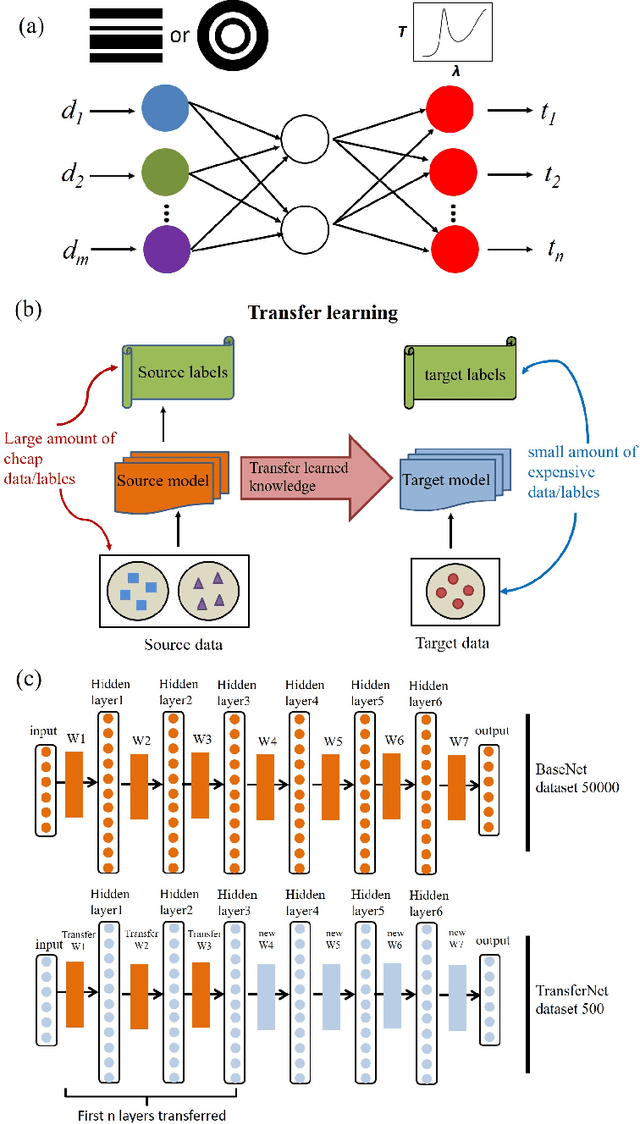

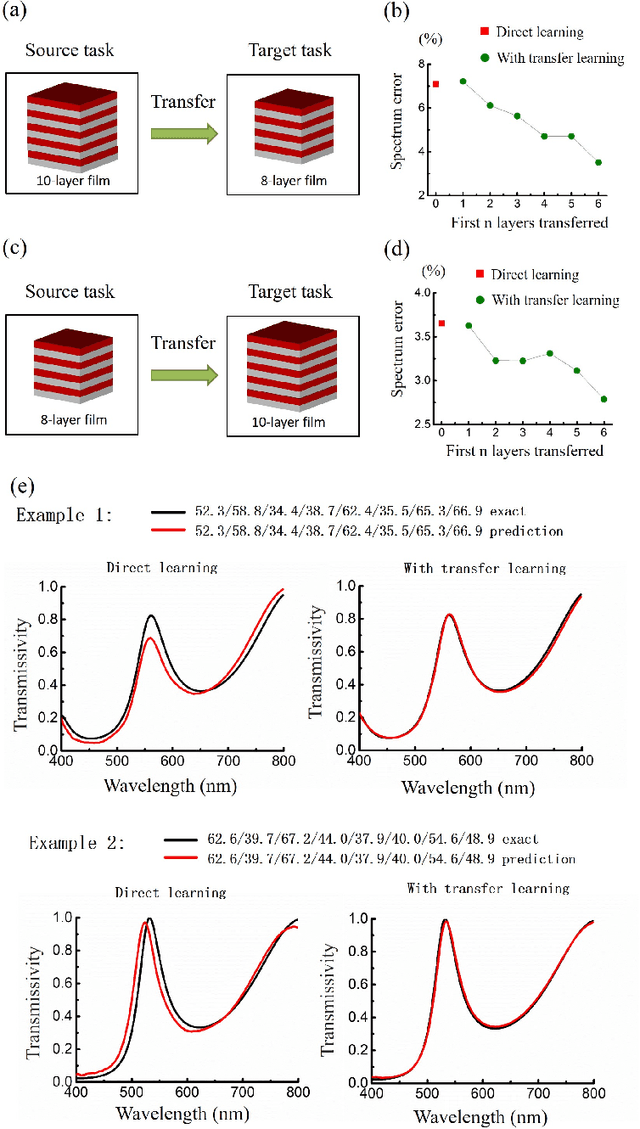
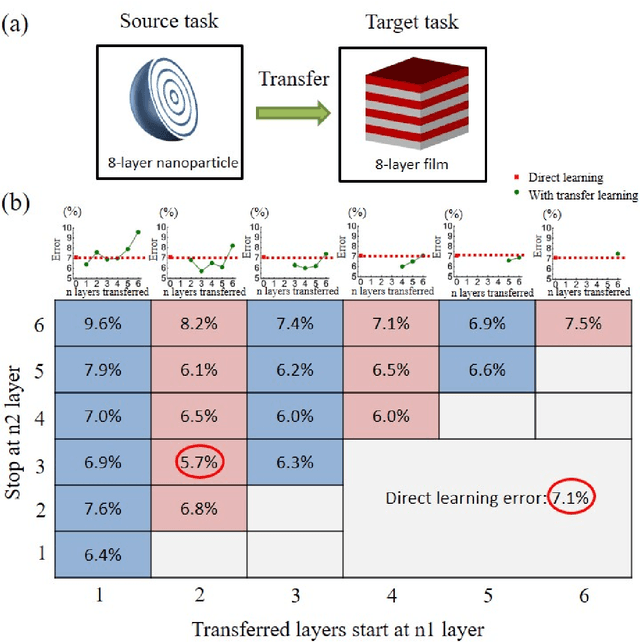
Deep learning is known to be data-hungry, which hinders its application in many areas of science when datasets are small. Here, we propose to use transfer learning methods to migrate knowledge between different physical scenarios and significantly improve the prediction accuracy of artificial neural networks trained on a small dataset. This method can help reduce the demand for expensive data by making use of additional inexpensive data. First, we demonstrate that in predicting the transmission from multilayer photonic film, the relative error rate is reduced by 46.8% (26.5%) when the source data comes from 10-layer (8-layer) films and the target data comes from 8-layer (10-layer) films. Second, we show that the relative error rate is decreased by 22% when knowledge is transferred between two very different physical scenarios: transmission from multilayer films and scattering from multilayer nanoparticles. Finally, we propose a multi-task learning method to improve the performance of different physical scenarios simultaneously in which each task only has a small dataset.
Gated Orthogonal Recurrent Units: On Learning to Forget
Oct 25, 2017We present a novel recurrent neural network (RNN) based model that combines the remembering ability of unitary RNNs with the ability of gated RNNs to effectively forget redundant/irrelevant information in its memory. We achieve this by extending unitary RNNs with a gating mechanism. Our model is able to outperform LSTMs, GRUs and Unitary RNNs on several long-term dependency benchmark tasks. We empirically both show the orthogonal/unitary RNNs lack the ability to forget and also the ability of GORU to simultaneously remember long term dependencies while forgetting irrelevant information. This plays an important role in recurrent neural networks. We provide competitive results along with an analysis of our model on many natural sequential tasks including the bAbI Question Answering, TIMIT speech spectrum prediction, Penn TreeBank, and synthetic tasks that involve long-term dependencies such as algorithmic, parenthesis, denoising and copying tasks.
Tunable Efficient Unitary Neural Networks (EUNN) and their application to RNNs
Apr 03, 2017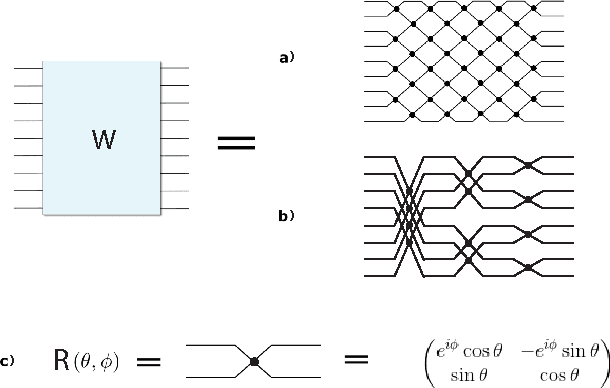
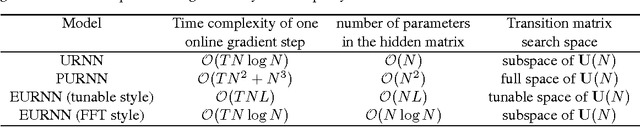
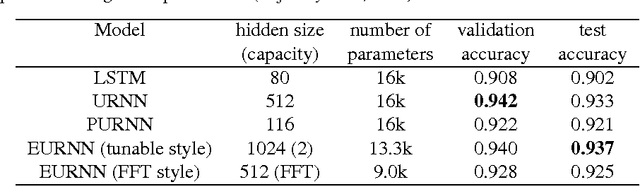
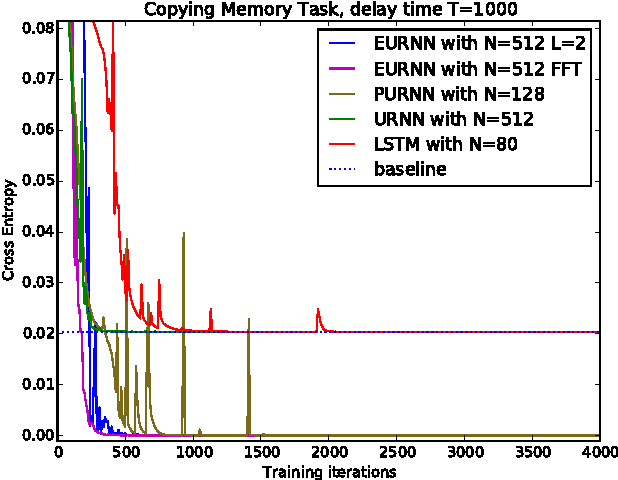
Using unitary (instead of general) matrices in artificial neural networks (ANNs) is a promising way to solve the gradient explosion/vanishing problem, as well as to enable ANNs to learn long-term correlations in the data. This approach appears particularly promising for Recurrent Neural Networks (RNNs). In this work, we present a new architecture for implementing an Efficient Unitary Neural Network (EUNNs); its main advantages can be summarized as follows. Firstly, the representation capacity of the unitary space in an EUNN is fully tunable, ranging from a subspace of SU(N) to the entire unitary space. Secondly, the computational complexity for training an EUNN is merely $\mathcal{O}(1)$ per parameter. Finally, we test the performance of EUNNs on the standard copying task, the pixel-permuted MNIST digit recognition benchmark as well as the Speech Prediction Test (TIMIT). We find that our architecture significantly outperforms both other state-of-the-art unitary RNNs and the LSTM architecture, in terms of the final performance and/or the wall-clock training speed. EUNNs are thus promising alternatives to RNNs and LSTMs for a wide variety of applications.