 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoProSketch: Controllable and Progressive Sketch Generation with Diffusion Model
Apr 11, 2025
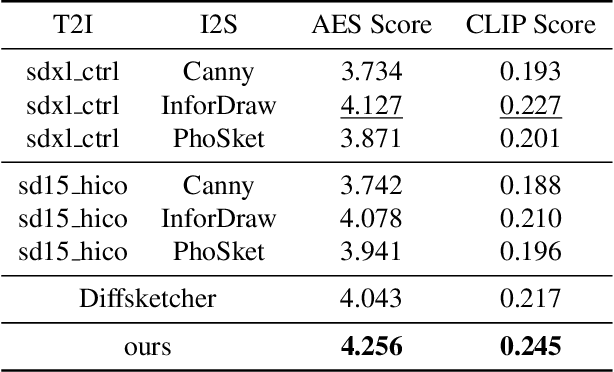
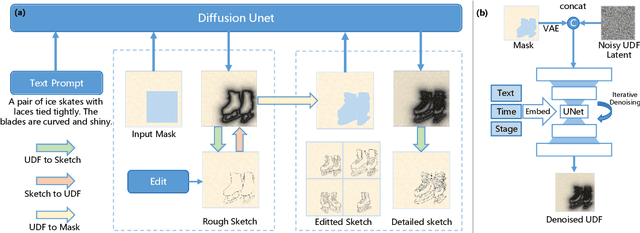
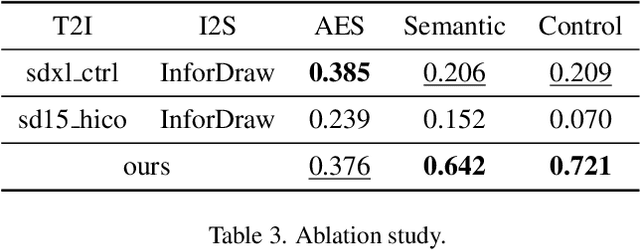
Sketches serve as fundamental blueprints in artistic creation because sketch editing is easier and more intuitive than pixel-level RGB image editing for painting artists, yet sketch generation remains unexplored despite advancements in generative models. We propose a novel framework CoProSketch, providing prominent controllability and details for sketch generation with diffusion models. A straightforward method is fine-tuning a pretrained image generation diffusion model with binarized sketch images. However, we find that the diffusion models fail to generate clear binary images, which makes the produced sketches chaotic. We thus propose to represent the sketches by unsigned distance field (UDF), which is continuous and can be easily decoded to sketches through a lightweight network. With CoProSketch, users generate a rough sketch from a bounding box and a text prompt. The rough sketch can be manually edited and fed back into the model for iterative refinement and will be decoded to a detailed sketch as the final result. Additionally, we curate the first large-scale text-sketch paired dataset as the training data. Experiments demonstrate superior semantic consistency and controllability over baselines, offering a practical solution for integrating user feedback into generative workflows.
DATAP-SfM: Dynamic-Aware Tracking Any Point for Robust Structure from Motion in the Wild
Nov 20, 2024



This paper proposes a concise, elegant, and robust pipeline to estimate smooth camera trajectories and obtain dense point clouds for casual videos in the wild. Traditional frameworks, such as ParticleSfM~\cite{zhao2022particlesfm}, address this problem by sequentially computing the optical flow between adjacent frames to obtain point trajectories. They then remove dynamic trajectories through motion segmentation and perform global bundle adjustment. However, the process of estimating optical flow between two adjacent frames and chaining the matches can introduce cumulative errors. Additionally, motion segmentation combined with single-view depth estimation often faces challenges related to scale ambiguity. To tackle these challenges, we propose a dynamic-aware tracking any point (DATAP) method that leverages consistent video depth and point tracking. Specifically, our DATAP addresses these issues by estimating dense point tracking across the video sequence and predicting the visibility and dynamics of each point. By incorporating the consistent video depth prior, the performance of motion segmentation is enhanced. With the integration of DATAP, it becomes possible to estimate and optimize all camera poses simultaneously by performing global bundle adjustments for point tracking classified as static and visible, rather than relying on incremental camera registration. Extensive experiments on dynamic sequences, e.g., Sintel and TUM RGBD dynamic sequences, and on the wild video, e.g., DAVIS, demonstrate that the proposed method achieves state-of-the-art performance in terms of camera pose estimation even in complex dynamic challenge scenes.