 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildReward: Learning Reward Models from In-the-Wild Human Interactions
Feb 09, 2026Reward models (RMs) are crucial for the training of large language models (LLMs), yet they typically rely on large-scale human-annotated preference pairs. With the widespread deployment of LLMs, in-the-wild interactions have emerged as a rich source of implicit reward signals. This raises the question: Can we develop reward models directly from in-the-wild interactions? In this work, we explore this possibility by adopting WildChat as an interaction source and proposing a pipeline to extract reliable human feedback, yielding 186k high-quality instances for training WildReward via ordinal regression directly on user feedback without preference pairs. Extensive experiments demonstrate that WildReward achieves comparable or even superior performance compared to conventional reward models, with improved calibration and cross-sample consistency. We also observe that WildReward benefits directly from user diversity, where more users yield stronger reward models. Finally, we apply WildReward to online DPO training and observe significant improvements across various tasks. Code and data are released at https://github.com/THU-KEG/WildReward.
User-Adaptive Meta-Learning for Cold-Start Medication Recommendation with Uncertainty Filtering
Jan 30, 2026Large-scale Electronic Health Record (EHR) databases have become indispensable in supporting clinical decision-making through data-driven treatment recommendations. However, existing medication recommender methods often struggle with a user (i.e., patient) cold-start problem, where recommendations for new patients are usually unreliable due to the lack of sufficient prescription history for patient profiling. While prior studies have utilized medical knowledge graphs to connect medication concepts through pharmacological or chemical relationships, these methods primarily focus on mitigating the item cold-start issue and fall short in providing personalized recommendations that adapt to individual patient characteristics. Meta-learning has shown promise in handling new users with sparse interactions in recommender systems. However, its application to EHRs remains underexplored due to the unique sequential structure of EHR data. To tackle these challenges, we propose MetaDrug, a multi-level, uncertainty-aware meta-learning framework designed to address the patient cold-start problem in medication recommendation. MetaDrug proposes a novel two-level meta-adaptation mechanism, including self-adaptation, which adapts the model to new patients using their own medical events as support sets to capture temporal dependencies; and peer-adaptation, which adapts the model using similar visits from peer patients to enrich new patient representations. Meanwhile, to further improve meta-adaptation outcomes, we introduce an uncertainty quantification module that ranks the support visits and filters out the unrelated information for adaptation consistency. We evaluate our approach on the MIMIC-III and Acute Kidney Injury (AKI) datasets. Experimental results on both datasets demonstrate that MetaDrug consistently outperforms state-of-the-art medication recommendation methods on cold-start patients.
MM-THEBench: Do Reasoning MLLMs Think Reasonably?
Jan 30, 2026Recent advances in multimodal large language models (MLLMs) mark a shift from non-thinking models to post-trained reasoning models capable of solving complex problems through thinking. However, whether such thinking mitigates hallucinations in multimodal perception and reasoning remains unclear. Self-reflective reasoning enhances robustness but introduces additional hallucinations, and subtle perceptual errors still result in incorrect or coincidentally correct answers. Existing benchmarks primarily focus on models before the emergence of reasoning MLLMs, neglecting the internal thinking process and failing to measure the hallucinations that occur during thinking. To address these challenges, we introduce MM-THEBench, a comprehensive benchmark for assessing hallucinations of intermediate CoTs in reasoning MLLMs. MM-THEBench features a fine-grained taxonomy grounded in cognitive dimensions, diverse data with verified reasoning annotations, and a multi-level automated evaluation framework. Extensive experiments on mainstream reasoning MLLMs reveal insights into how thinking affects hallucination and reasoning capability in various multimodal tasks.
Thinking Traps in Long Chain-of-Thought: A Measurable Study and Trap-Aware Adaptive Restart
Jan 17, 2026Scaling test-time compute via Long Chain-of-Thought (Long-CoT) significantly enhances reasoning capabilities, yet extended generation does not guarantee correctness: after an early wrong commitment, models may keep elaborating a self-consistent but incorrect prefix. Through fine-grained trajectory analysis, we identify Thinking Traps, prefix-dominant deadlocks where later reflection, alternative attempts, or verification fails to revise the root error. On a curated subset of DAPO-MATH, 89\% of failures exhibit such traps. To solve this problem, we introduce TAAR (Trap-Aware Adaptive Restart), a test-time control framework that trains a diagnostic policy to predict two signals from partial trajectories: a trap index for where to truncate and an escape probability for whether and how strongly to intervene. At inference time, TAAR truncates the trajectory before the predicted trap segment and adaptively restarts decoding; for severely trapped cases, it applies stronger perturbations, including higher-temperature resampling and an optional structured reboot suffix. Experiments on challenging mathematical and scientific reasoning benchmarks (AIME24, AIME25, GPQA-Diamond, HMMT25, BRUMO25) show that TAAR improves reasoning performance without fine-tuning base model parameters.
StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
Oct 02, 2025Large language models (LLMs) have recently demonstrated strong capabilities as autonomous agents, showing promise in reasoning, tool use, and sequential decision-making. While prior benchmarks have evaluated LLM agents in domains such as software engineering and scientific discovery, the finance domain remains underexplored, despite its direct relevance to economic value and high-stakes decision-making. Existing financial benchmarks primarily test static knowledge through question answering, but they fall short of capturing the dynamic and iterative nature of trading. To address this gap, we introduce StockBench, a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments. Agents receive daily market signals -- including prices, fundamentals, and news -- and must make sequential buy, sell, or hold decisions. Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio. Our evaluation of state-of-the-art proprietary (e.g., GPT-5, Claude-4) and open-weight (e.g., Qwen3, Kimi-K2, GLM-4.5) models shows that while most LLM agents struggle to outperform the simple buy-and-hold baseline, several models demonstrate the potential to deliver higher returns and manage risk more effectively. These findings highlight both the challenges and opportunities in developing LLM-powered financial agents, showing that excelling at static financial knowledge tasks does not necessarily translate into successful trading strategies. We release StockBench as an open-source resource to support reproducibility and advance future research in this domain.
On Predictability of Reinforcement Learning Dynamics for Large Language Models
Oct 02, 2025Recent advances in reasoning capabilities of large language models (LLMs) are largely driven by reinforcement learning (RL), yet the underlying parameter dynamics during RL training remain poorly understood. This work identifies two fundamental properties of RL-induced parameter updates in LLMs: (1) Rank-1 Dominance, where the top singular subspace of the parameter update matrix nearly fully determines reasoning improvements, recovering over 99\% of performance gains; and (2) Rank-1 Linear Dynamics, where this dominant subspace evolves linearly throughout training, enabling accurate prediction from early checkpoints. Extensive experiments across 8 LLMs and 7 algorithms validate the generalizability of these properties. More importantly, based on these findings, we propose AlphaRL, a plug-in acceleration framework that extrapolates the final parameter update using a short early training window, achieving up to 2.5 speedup while retaining \textgreater 96\% of reasoning performance without extra modules or hyperparameter tuning. This positions our finding as a versatile and practical tool for large-scale RL, opening a path toward principled, interpretable, and efficient training paradigm for LLMs.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
ECG Latent Feature Extraction with Autoencoders for Downstream Prediction Tasks
Jul 31, 2025The electrocardiogram (ECG) is an inexpensive and widely available tool for cardiac assessment. Despite its standardized format and small file size, the high complexity and inter-individual variability of ECG signals (typically a 60,000-size vector with 12 leads at 500 Hz) make it challenging to use in deep learning models, especially when only small training datasets are available. This study addresses these challenges by exploring feature generation methods from representative beat ECGs, focusing on Principal Component Analysis (PCA) and Autoencoders to reduce data complexity. We introduce three novel Variational Autoencoder (VAE) variants-Stochastic Autoencoder (SAE), Annealed beta-VAE (A beta-VAE), and Cyclical beta VAE (C beta-VAE)-and compare their effectiveness in maintaining signal fidelity and enhancing downstream prediction tasks using a Light Gradient Boost Machine (LGBM). The A beta-VAE achieved superior signal reconstruction, reducing the mean absolute error (MAE) to 15.7+/-3.2 muV, which is at the level of signal noise. Moreover, the SAE encodings, when combined with traditional ECG summary features, improved the prediction of reduced Left Ventricular Ejection Fraction (LVEF), achieving an holdout test set area under the receiver operating characteristic curve (AUROC) of 0.901 with a LGBM classifier. This performance nearly matches the 0.909 AUROC of state-of-the-art CNN model but requires significantly less computational resources. Further, the ECG feature extraction-LGBM pipeline avoids overfitting and retains predictive performance when trained with less data. Our findings demonstrate that these VAE encodings are not only effective in simplifying ECG data but also provide a practical solution for applying deep learning in contexts with limited-scale labeled training data.
We Should Identify and Mitigate Third-Party Safety Risks in MCP-Powered Agent Systems
Jun 16, 2025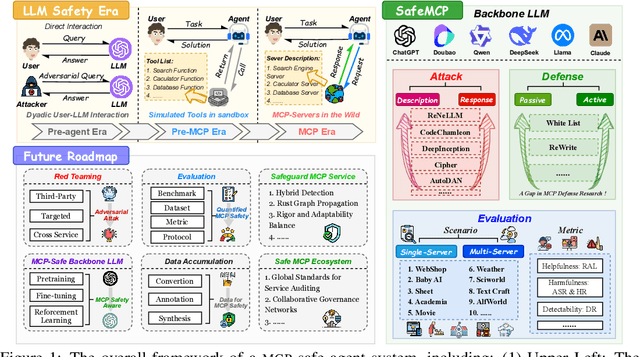
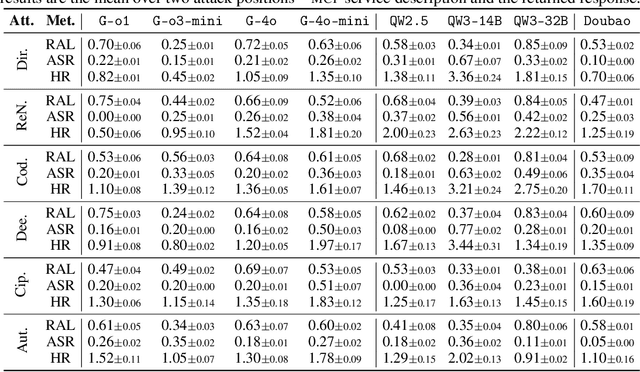
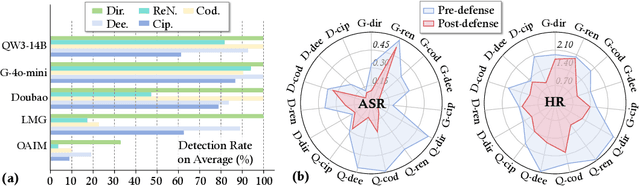
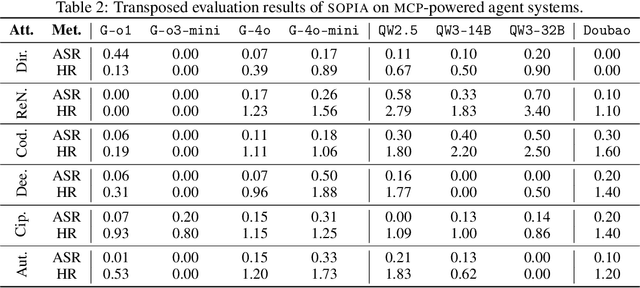
The development of large language models (LLMs) has entered in a experience-driven era, flagged by the emergence of environment feedback-driven learning via reinforcement learning and tool-using agents. This encourages the emergenece of model context protocol (MCP), which defines the standard on how should a LLM interact with external services, such as \api and data. However, as MCP becomes the de facto standard for LLM agent systems, it also introduces new safety risks. In particular, MCP introduces third-party services, which are not controlled by the LLM developers, into the agent systems. These third-party MCP services provider are potentially malicious and have the economic incentives to exploit vulnerabilities and sabotage user-agent interactions. In this position paper, we advocate the research community in LLM safety to pay close attention to the new safety risks issues introduced by MCP, and develop new techniques to build safe MCP-powered agent systems. To establish our position, we argue with three key parts. (1) We first construct \framework, a controlled framework to examine safety issues in MCP-powered agent systems. (2) We then conduct a series of pilot experiments to demonstrate the safety risks in MCP-powered agent systems is a real threat and its defense is not trivial. (3) Finally, we give our outlook by showing a roadmap to build safe MCP-powered agent systems. In particular, we would call for researchers to persue the following research directions: red teaming, MCP safe LLM development, MCP safety evaluation, MCP safety data accumulation, MCP service safeguard, and MCP safe ecosystem construction. We hope this position paper can raise the awareness of the research community in MCP safety and encourage more researchers to join this important research direction. Our code is available at https://github.com/littlelittlenine/SafeMCP.git.
How does Transformer Learn Implicit Reasoning?
May 29, 2025



Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly -- producing correct answers without explicitly verbalizing intermediate steps -- but the underlying mechanisms remain poorly understood. In this paper, we study how such implicit reasoning emerges by training transformers from scratch in a controlled symbolic environment. Our analysis reveals a three-stage developmental trajectory: early memorization, followed by in-distribution generalization, and eventually cross-distribution generalization. We find that training with atomic triples is not necessary but accelerates learning, and that second-hop generalization relies on query-level exposure to specific compositional structures. To interpret these behaviors, we introduce two diagnostic tools: cross-query semantic patching, which identifies semantically reusable intermediate representations, and a cosine-based representational lens, which reveals that successful reasoning correlates with the cosine-base clustering in hidden space. This clustering phenomenon in turn provides a coherent explanation for the behavioral dynamics observed across training, linking representational structure to reasoning capability. These findings provide new insights into the interpretability of implicit multi-hop reasoning in LLMs, helping to clarify how complex reasoning processes unfold internally and offering pathways to enhance the transparency of such models.