 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM3D: Zero-Shot 3D Object Detection via Segment Anything Model
Jun 04, 2023With the development of large language models, many remarkable linguistic systems like ChatGPT have thrived and achieved astonishing success on many tasks, showing the incredible power of foundation models. In the spirit of unleashing the capability of foundation models on vision tasks, the Segment Anything Model (SAM), a vision foundation model for image segmentation, has been proposed recently and presents strong zero-shot ability on many downstream 2D tasks. However, whether SAM can be adapted to 3D vision tasks has yet to be explored, especially 3D object detection. With this inspiration, we explore adapting the zero-shot ability of SAM to 3D object detection in this paper. We propose a SAM-powered BEV processing pipeline to detect objects and get promising results on the large-scale Waymo open dataset. As an early attempt, our method takes a step toward 3D object detection with vision foundation models and presents the opportunity to unleash their power on 3D vision tasks. The code is released at https://github.com/DYZhang09/SAM3D.
Multi-Modal 3D Object Detection by Box Matching
May 12, 2023Multi-modal 3D object detection has received growing attention as the information from different sensors like LiDAR and cameras are complementary. Most fusion methods for 3D detection rely on an accurate alignment and calibration between 3D point clouds and RGB images. However, such an assumption is not reliable in a real-world self-driving system, as the alignment between different modalities is easily affected by asynchronous sensors and disturbed sensor placement. We propose a novel {F}usion network by {B}ox {M}atching (FBMNet) for multi-modal 3D detection, which provides an alternative way for cross-modal feature alignment by learning the correspondence at the bounding box level to free up the dependency of calibration during inference. With the learned assignments between 3D and 2D object proposals, the fusion for detection can be effectively performed by combing their ROI features. Extensive experiments on the nuScenes dataset demonstrate that our method is much more stable in dealing with challenging cases such as asynchronous sensors, misaligned sensor placement, and degenerated camera images than existing fusion methods. We hope that our FBMNet could provide an available solution to dealing with these challenging cases for safety in real autonomous driving scenarios. Codes will be publicly available at https://github.com/happinesslz/FBMNet.
SOOD: Towards Semi-Supervised Oriented Object Detection
Apr 10, 2023



Semi-Supervised Object Detection (SSOD), aiming to explore unlabeled data for boosting object detectors, has become an active task in recent years. However, existing SSOD approaches mainly focus on horizontal objects, leaving multi-oriented objects that are common in aerial images unexplored. This paper proposes a novel Semi-supervised Oriented Object Detection model, termed SOOD, built upon the mainstream pseudo-labeling framework. Towards oriented objects in aerial scenes, we design two loss functions to provide better supervision. Focusing on the orientations of objects, the first loss regularizes the consistency between each pseudo-label-prediction pair (includes a prediction and its corresponding pseudo label) with adaptive weights based on their orientation gap. Focusing on the layout of an image, the second loss regularizes the similarity and explicitly builds the many-to-many relation between the sets of pseudo-labels and predictions. Such a global consistency constraint can further boost semi-supervised learning. Our experiments show that when trained with the two proposed losses, SOOD surpasses the state-of-the-art SSOD methods under various settings on the DOTA-v1.5 benchmark. The code will be available at https://github.com/HamPerdredes/SOOD.
CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model
Apr 09, 2023



Supervised crowd counting relies heavily on costly manual labeling, which is difficult and expensive, especially in dense scenes. To alleviate the problem, we propose a novel unsupervised framework for crowd counting, named CrowdCLIP. The core idea is built on two observations: 1) the recent contrastive pre-trained vision-language model (CLIP) has presented impressive performance on various downstream tasks; 2) there is a natural mapping between crowd patches and count text. To the best of our knowledge, CrowdCLIP is the first to investigate the vision language knowledge to solve the counting problem. Specifically, in the training stage, we exploit the multi-modal ranking loss by constructing ranking text prompts to match the size-sorted crowd patches to guide the image encoder learning. In the testing stage, to deal with the diversity of image patches, we propose a simple yet effective progressive filtering strategy to first select the highly potential crowd patches and then map them into the language space with various counting intervals. Extensive experiments on five challenging datasets demonstrate that the proposed CrowdCLIP achieves superior performance compared to previous unsupervised state-of-the-art counting methods. Notably, CrowdCLIP even surpasses some popular fully-supervised methods under the cross-dataset setting. The source code will be available at https://github.com/dk-liang/CrowdCLIP.
Repainting and Imitating Learning for Lane Detection
Oct 11, 2022

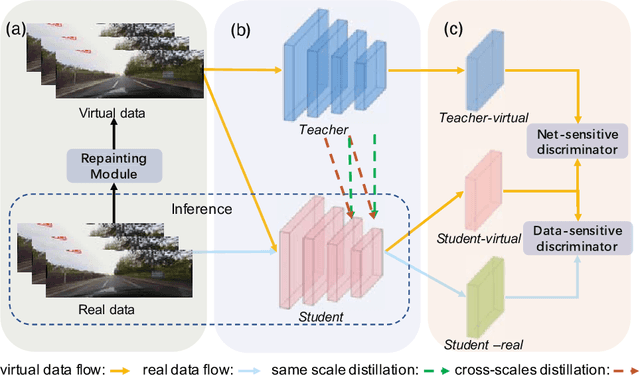
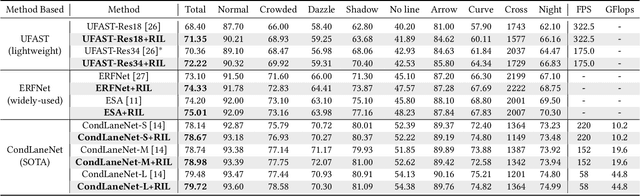
Current lane detection methods are struggling with the invisibility lane issue caused by heavy shadows, severe road mark degradation, and serious vehicle occlusion. As a result, discriminative lane features can be barely learned by the network despite elaborate designs due to the inherent invisibility of lanes in the wild. In this paper, we target at finding an enhanced feature space where the lane features are distinctive while maintaining a similar distribution of lanes in the wild. To achieve this, we propose a novel Repainting and Imitating Learning (RIL) framework containing a pair of teacher and student without any extra data or extra laborious labeling. Specifically, in the repainting step, an enhanced ideal virtual lane dataset is built in which only the lane regions are repainted while non-lane regions are kept unchanged, maintaining the similar distribution of lanes in the wild. The teacher model learns enhanced discriminative representation based on the virtual data and serves as the guidance for a student model to imitate. In the imitating learning step, through the scale-fusing distillation module, the student network is encouraged to generate features that mimic the teacher model both on the same scale and cross scales. Furthermore, the coupled adversarial module builds the bridge to connect not only teacher and student models but also virtual and real data, adjusting the imitating learning process dynamically. Note that our method introduces no extra time cost during inference and can be plug-and-play in various cutting-edge lane detection networks. Experimental results prove the effectiveness of the RIL framework both on CULane and TuSimple for four modern lane detection methods. The code and model will be available soon.
Paint and Distill: Boosting 3D Object Detection with Semantic Passing Network
Jul 12, 2022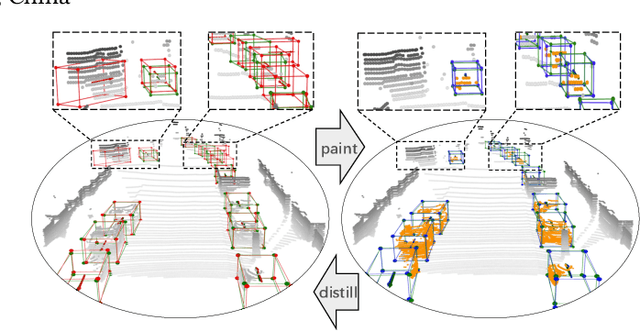
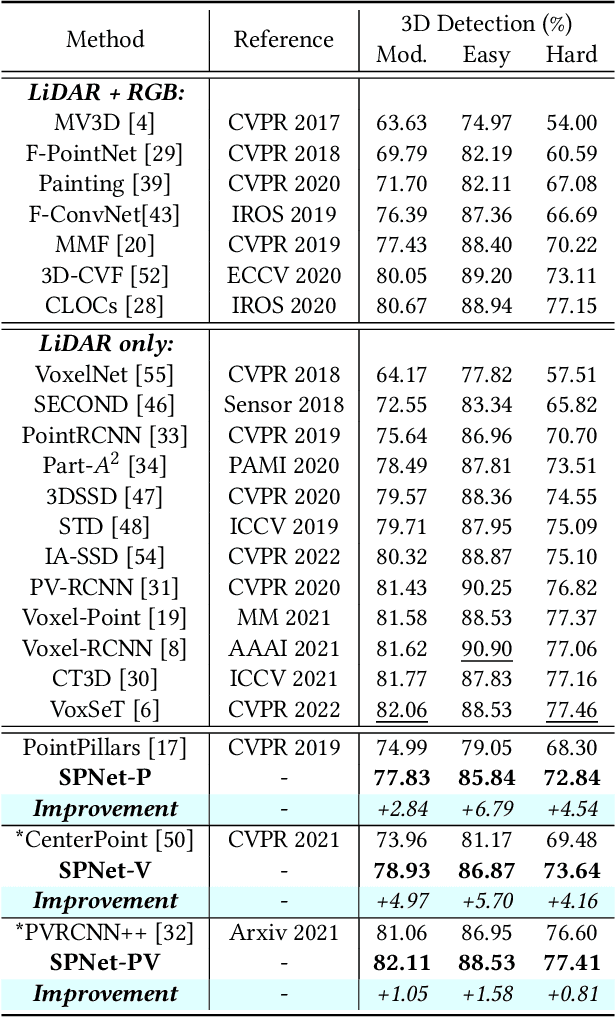
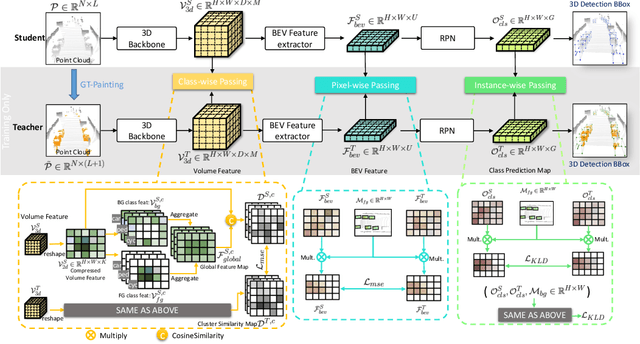
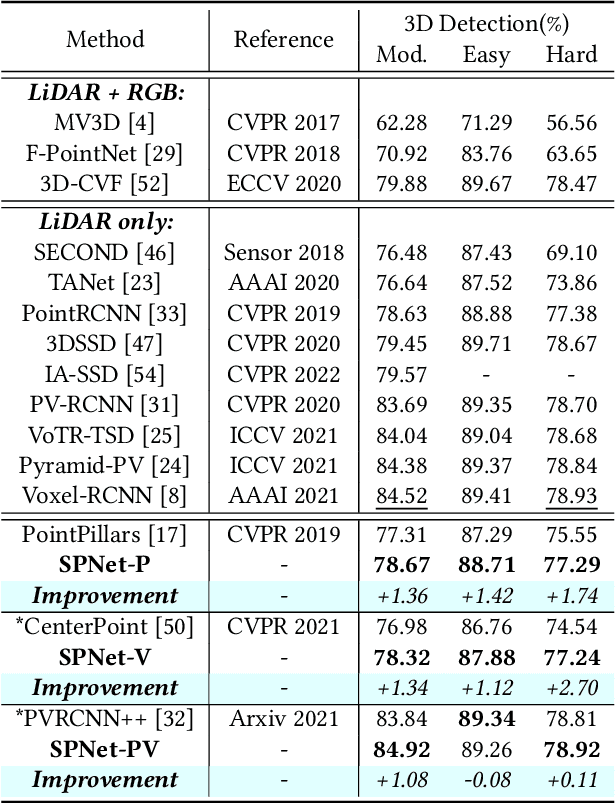
3D object detection task from lidar or camera sensors is essential for autonomous driving. Pioneer attempts at multi-modality fusion complement the sparse lidar point clouds with rich semantic texture information from images at the cost of extra network designs and overhead. In this work, we propose a novel semantic passing framework, named SPNet, to boost the performance of existing lidar-based 3D detection models with the guidance of rich context painting, with no extra computation cost during inference. Our key design is to first exploit the potential instructive semantic knowledge within the ground-truth labels by training a semantic-painted teacher model and then guide the pure-lidar network to learn the semantic-painted representation via knowledge passing modules at different granularities: class-wise passing, pixel-wise passing and instance-wise passing. Experimental results show that the proposed SPNet can seamlessly cooperate with most existing 3D detection frameworks with 1~5% AP gain and even achieve new state-of-the-art 3D detection performance on the KITTI test benchmark. Code is available at: https://github.com/jb892/SPNet.
The Devil is in the Task: Exploiting Reciprocal Appearance-Localization Features for Monocular 3D Object Detection
Dec 28, 2021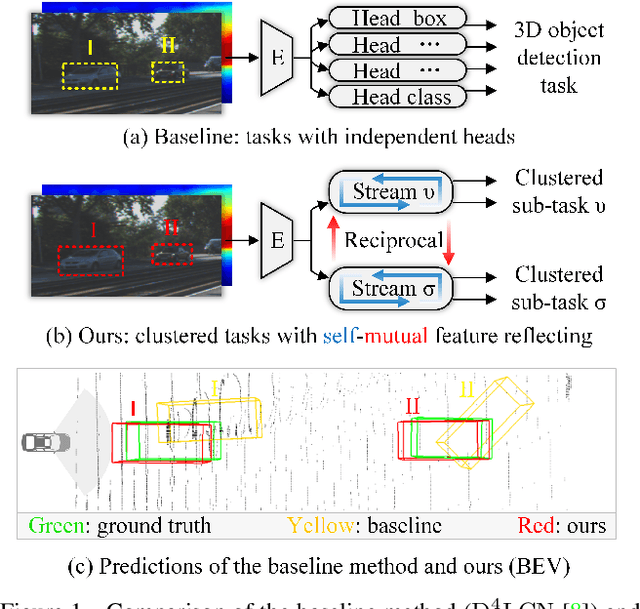
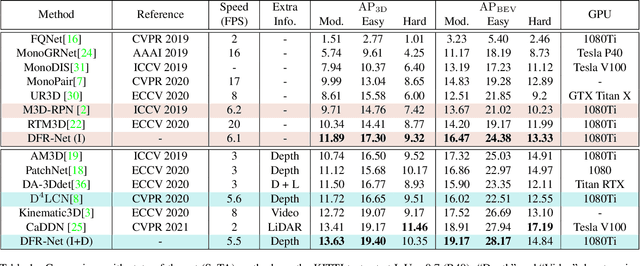
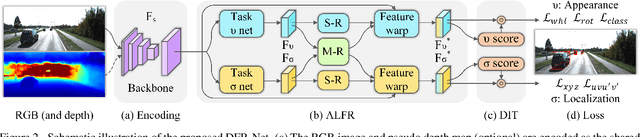
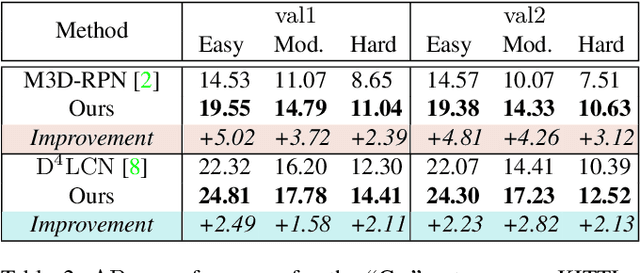
Low-cost monocular 3D object detection plays a fundamental role in autonomous driving, whereas its accuracy is still far from satisfactory. In this paper, we dig into the 3D object detection task and reformulate it as the sub-tasks of object localization and appearance perception, which benefits to a deep excavation of reciprocal information underlying the entire task. We introduce a Dynamic Feature Reflecting Network, named DFR-Net, which contains two novel standalone modules: (i) the Appearance-Localization Feature Reflecting module (ALFR) that first separates taskspecific features and then self-mutually reflects the reciprocal features; (ii) the Dynamic Intra-Trading module (DIT) that adaptively realigns the training processes of various sub-tasks via a self-learning manner. Extensive experiments on the challenging KITTI dataset demonstrate the effectiveness and generalization of DFR-Net. We rank 1st among all the monocular 3D object detectors in the KITTI test set (till March 16th, 2021). The proposed method is also easy to be plug-and-play in many cutting-edge 3D detection frameworks at negligible cost to boost performance. The code will be made publicly available.
SGM3D: Stereo Guided Monocular 3D Object Detection
Dec 03, 2021
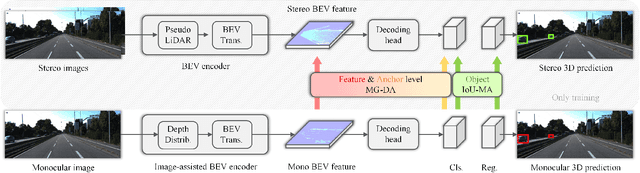
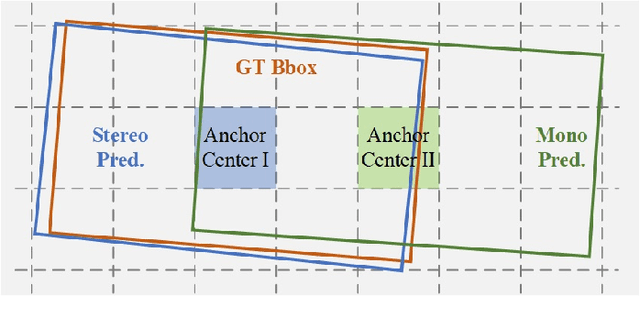

Monocular 3D object detection is a critical yet challenging task for autonomous driving, due to the lack of accurate depth information captured by LiDAR sensors. In this paper, we propose a stereo-guided monocular 3D object detection network, termed SGM3D, which leverages robust 3D features extracted from stereo images to enhance the features learned from the monocular image. We innovatively investigate a multi-granularity domain adaptation module (MG-DA) to exploit the network's ability so as to generate stereo-mimic features only based on the monocular cues. The coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are leveraged to guide the monocular branch. We present an IoU matching-based alignment module (IoU-MA) for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches in previous stages. We conduct extensive experiments on the most challenging KITTI and Lyft datasets and achieve new state-of-the-art performance. Furthermore, our method can be integrated into many other monocular approaches to boost performance without introducing any extra computational cost.
Self-Adaptive Partial Domain Adaptation
Sep 18, 2021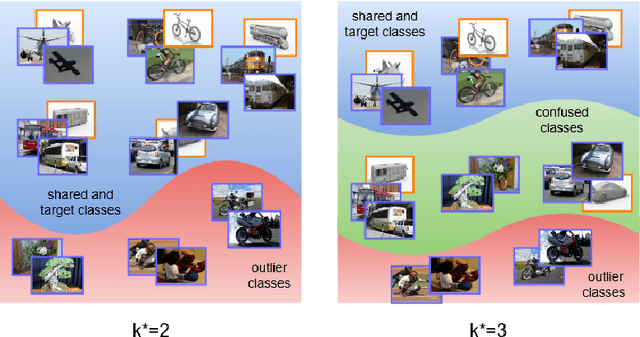
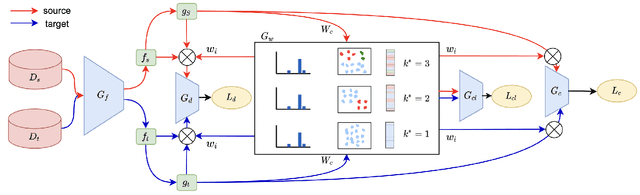
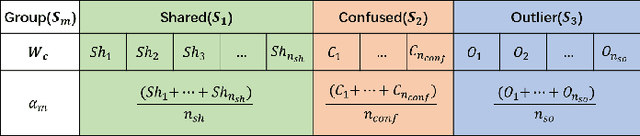

Partial Domain adaptation (PDA) aims to solve a more practical cross-domain learning problem that assumes target label space is a subset of source label space. However, the mismatched label space causes significant negative transfer. A traditional solution is using soft weights to increase weights of source shared domain and reduce those of source outlier domain. But it still learns features of outliers and leads to negative immigration. The other mainstream idea is to distinguish source domain into shared and outlier parts by hard binary weights, while it is unavailable to correct the tangled shared and outlier classes. In this paper, we propose an end-to-end Self-Adaptive Partial Domain Adaptation(SAPDA) Network. Class weights evaluation mechanism is introduced to dynamically self-rectify the weights of shared, outlier and confused classes, thus the higher confidence samples have the more sufficient weights. Meanwhile it can eliminate the negative transfer caused by the mismatching of label space greatly. Moreover, our strategy can efficiently measure the transferability of samples in a broader sense, so that our method can achieve competitive results on unsupervised DA task likewise. A large number of experiments on multiple benchmarks have demonstrated the effectiveness of our SAPDA.
Coarse to Fine: Domain Adaptive Crowd Counting via Adversarial Scoring Network
Jul 27, 2021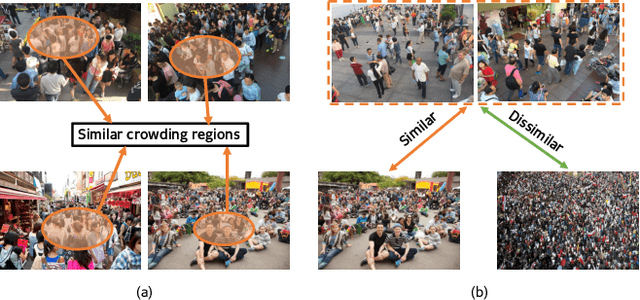
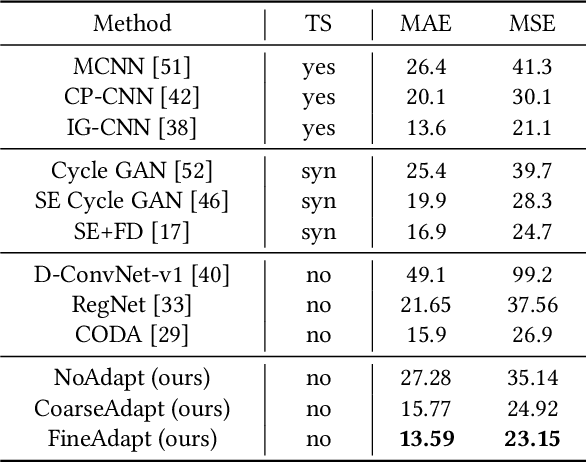
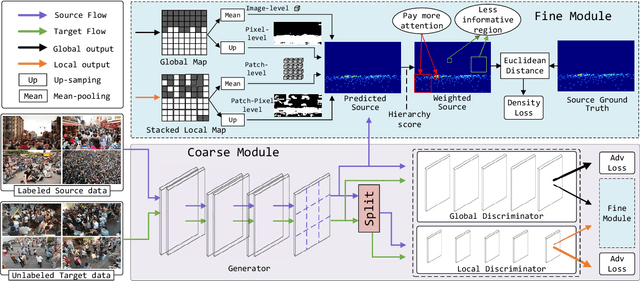
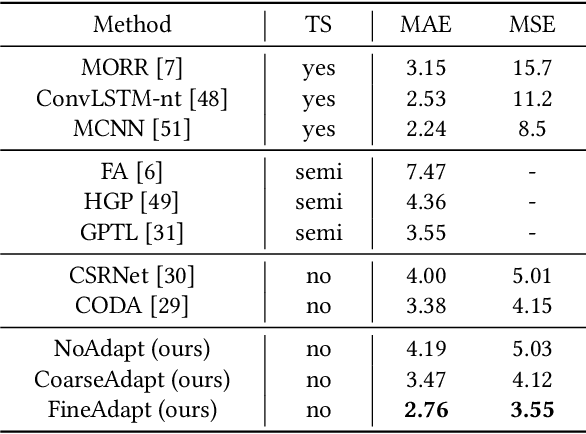
Recent deep networks have convincingly demonstrated high capability in crowd counting, which is a critical task attracting widespread attention due to its various industrial applications. Despite such progress, trained data-dependent models usually can not generalize well to unseen scenarios because of the inherent domain shift. To facilitate this issue, this paper proposes a novel adversarial scoring network (ASNet) to gradually bridge the gap across domains from coarse to fine granularity. In specific, at the coarse-grained stage, we design a dual-discriminator strategy to adapt source domain to be close to the targets from the perspectives of both global and local feature space via adversarial learning. The distributions between two domains can thus be aligned roughly. At the fine-grained stage, we explore the transferability of source characteristics by scoring how similar the source samples are to target ones from multiple levels based on generative probability derived from coarse stage. Guided by these hierarchical scores, the transferable source features are properly selected to enhance the knowledge transfer during the adaptation process. With the coarse-to-fine design, the generalization bottleneck induced from the domain discrepancy can be effectively alleviated. Three sets of migration experiments show that the proposed methods achieve state-of-the-art counting performance compared with major unsupervised methods.