 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetis: A Generalizable and Efficient World-Action Model for Autonomous Driving and Urban Navigation
Jun 14, 2026World action models~(WAMs) have shown great promise for autonomous driving and urban navigation. Built upon Vision-Language-Action models or video generation models, existing approaches suffer key limitations: (1) High inference latency due to future observation prediction at test time, and (2) tightly coupled video and action modeling leading to representational mismatch and degraded generalization. To address both issues, we propose Metis, an end-to-end WAM framework that decouples video generation and action prediction. Specifically, Metis employs a Mixture-of-Transformers architecture with dedicated experts for video generation and action prediction, preserving the intrinsic distributional properties of each task. To enhance efficiency, we introduce an asymmetric attention mask that enables joint training of both experts while allowing the action model to bypass explicit video generation during inference. This design ensures training-inference consistency and significantly reduces computational costs without compromising planning performance. Extensive experiments demonstrate state-of-the-art performance on the NAVSIM navhard and navtest benchmarks and the CityWalker navigation benchmark, validating both the generalizability and efficiency across diverse tasks. Real-robot deployments further confirm the practical feasibility of our approach.
Uni-World VLA: Interleaved World Modeling and Planning for Autonomous Driving
Mar 28, 2026Autonomous driving requires reasoning about how the environment evolves and planning actions accordingly. Existing world-model-based approaches typically predict future scenes first and plan afterwards, resulting in open-loop imagination that may drift from the actual decision process. In this paper, we present Uni-World VLA, a unified vision-language-action (VLA) model that tightly interleaves future frame prediction and trajectory planning. Instead of generating a full world rollout before planning, our model alternates between predicting future frames and ego actions step by step, allowing planning decisions to be continuously conditioned on the imagined future observations. This interleaved generation forms a closed-loop interaction between world modeling and control, enabling more adaptive decision-making in dynamic traffic scenarios. In addition, we incorporate monocular depth information into frames to provide stronger geometric cues for world modeling, improving long-horizon scene prediction. Experiments on the NAVSIM benchmark show that our approach achieves competitive closed-loop planning performance while producing high-fidelity future frame predictions. These results demonstrate that tightly coupling world prediction and planning is a promising direction for scalable VLA driving systems.
DriveCombo: Benchmarking Compositional Traffic Rule Reasoning in Autonomous Driving
Mar 02, 2026Multimodal Large Language Models (MLLMs) are rapidly becoming the intelligence brain of end-to-end autonomous driving systems. A key challenge is to assess whether MLLMs can truly understand and follow complex real-world traffic rules. However, existing benchmarks mainly focus on single-rule scenarios like traffic sign recognition, neglecting the complexity of multi-rule concurrency and conflicts in real driving. Consequently, models perform well on simple tasks but often fail or violate rules in real world complex situations. To bridge this gap, we propose DriveCombo, a text and vision-based benchmark for compositional traffic rule reasoning. Inspired by human drivers' cognitive development, we propose a systematic Five-Level Cognitive Ladder that evaluates reasoning from single-rule understanding to multi-rule integration and conflict resolution, enabling quantitative assessment across cognitive stages. We further propose a Rule2Scene Agent that maps language-based traffic rules to dynamic driving scenes through rule crafting and scene generation, enabling scene-level traffic rule visual reasoning. Evaluations of 14 mainstream MLLMs reveal performance drops as task complexity grows, particularly during rule conflicts. After splitting the dataset and fine-tuning on the training set, we further observe substantial improvements in both traffic rule reasoning and downstream planning capabilities. These results highlight the effectiveness of DriveCombo in advancing compliant and intelligent autonomous driving systems.
Vec-QMDP: Vectorized POMDP Planning on CPUs for Real-Time Autonomous Driving
Feb 09, 2026Planning under uncertainty for real-world robotics tasks, such as autonomous driving, requires reasoning in enormous high-dimensional belief spaces, rendering the problem computationally intensive. While parallelization offers scalability, existing hybrid CPU-GPU solvers face critical bottlenecks due to host-device synchronization latency and branch divergence on SIMT architectures, limiting their utility for real-time planning and hindering real-robot deployment. We present Vec-QMDP, a CPU-native parallel planner that aligns POMDP search with modern CPUs' SIMD architecture, achieving $227\times$--$1073\times$ speedup over state-of-the-art serial planners. Vec-QMDP adopts a Data-Oriented Design (DOD), refactoring scattered, pointer-based data structures into contiguous, cache-efficient memory layouts. We further introduce a hierarchical parallelism scheme: distributing sub-trees across independent CPU cores and SIMD lanes, enabling fully vectorized tree expansion and collision checking. Efficiency is maximized with the help of UCB load balancing across trees and a vectorized STR-tree for coarse-level collision checking. Evaluated on large-scale autonomous driving benchmarks, Vec-QMDP achieves state-of-the-art planning performance with millisecond-level latency, establishing CPUs as a high-performance computing platform for large-scale planning under uncertainty.
PlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
SGDrive: Scene-to-Goal Hierarchical World Cognition for Autonomous Driving
Jan 12, 2026Recent end-to-end autonomous driving approaches have leveraged Vision-Language Models (VLMs) to enhance planning capabilities in complex driving scenarios. However, VLMs are inherently trained as generalist models, lacking specialized understanding of driving-specific reasoning in 3D space and time. When applied to autonomous driving, these models struggle to establish structured spatial-temporal representations that capture geometric relationships, scene context, and motion patterns critical for safe trajectory planning. To address these limitations, we propose SGDrive, a novel framework that explicitly structures the VLM's representation learning around driving-specific knowledge hierarchies. Built upon a pre-trained VLM backbone, SGDrive decomposes driving understanding into a scene-agent-goal hierarchy that mirrors human driving cognition: drivers first perceive the overall environment (scene context), then attend to safety-critical agents and their behaviors, and finally formulate short-term goals before executing actions. This hierarchical decomposition provides the structured spatial-temporal representation that generalist VLMs lack, integrating multi-level information into a compact yet comprehensive format for trajectory planning. Extensive experiments on the NAVSIM benchmark demonstrate that SGDrive achieves state-of-the-art performance among camera-only methods on both PDMS and EPDMS, validating the effectiveness of hierarchical knowledge structuring for adapting generalist VLMs to autonomous driving.
LatentVLA: Efficient Vision-Language Models for Autonomous Driving via Latent Action Prediction
Jan 09, 2026End-to-end autonomous driving models trained on largescale datasets perform well in common scenarios but struggle with rare, long-tail situations due to limited scenario diversity. Recent Vision-Language-Action (VLA) models leverage broad knowledge from pre-trained visionlanguage models to address this limitation, yet face critical challenges: (1) numerical imprecision in trajectory prediction due to discrete tokenization, (2) heavy reliance on language annotations that introduce linguistic bias and annotation burden, and (3) computational inefficiency from multi-step chain-of-thought reasoning hinders real-time deployment. We propose LatentVLA, a novel framework that employs self-supervised latent action prediction to train VLA models without language annotations, eliminating linguistic bias while learning rich driving representations from unlabeled trajectory data. Through knowledge distillation, LatentVLA transfers the generalization capabilities of VLA models to efficient vision-based networks, achieving both robust performance and real-time efficiency. LatentVLA establishes a new state-of-the-art on the NAVSIM benchmark with a PDMS score of 92.4 and demonstrates strong zeroshot generalization on the nuScenes benchmark.
GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
Dec 13, 2024



Vision-based autonomous driving shows great potential due to its satisfactory performance and low costs. Most existing methods adopt dense representations (e.g., bird's eye view) or sparse representations (e.g., instance boxes) for decision-making, which suffer from the trade-off between comprehensiveness and efficiency. This paper explores a Gaussian-centric end-to-end autonomous driving (GaussianAD) framework and exploits 3D semantic Gaussians to extensively yet sparsely describe the scene. We initialize the scene with uniform 3D Gaussians and use surrounding-view images to progressively refine them to obtain the 3D Gaussian scene representation. We then use sparse convolutions to efficiently perform 3D perception (e.g., 3D detection, semantic map construction). We predict 3D flows for the Gaussians with dynamic semantics and plan the ego trajectory accordingly with an objective of future scene forecasting. Our GaussianAD can be trained in an end-to-end manner with optional perception labels when available. Extensive experiments on the widely used nuScenes dataset verify the effectiveness of our end-to-end GaussianAD on various tasks including motion planning, 3D occupancy prediction, and 4D occupancy forecasting. Code: https://github.com/wzzheng/GaussianAD.
UA-Track: Uncertainty-Aware End-to-End 3D Multi-Object Tracking
Jun 04, 2024



3D multiple object tracking (MOT) plays a crucial role in autonomous driving perception. Recent end-to-end query-based trackers simultaneously detect and track objects, which have shown promising potential for the 3D MOT task. However, existing methods overlook the uncertainty issue, which refers to the lack of precise confidence about the state and location of tracked objects. Uncertainty arises owing to various factors during motion observation by cameras, especially occlusions and the small size of target objects, resulting in an inaccurate estimation of the object's position, label, and identity. To this end, we propose an Uncertainty-Aware 3D MOT framework, UA-Track, which tackles the uncertainty problem from multiple aspects. Specifically, we first introduce an Uncertainty-aware Probabilistic Decoder to capture the uncertainty in object prediction with probabilistic attention. Secondly, we propose an Uncertainty-guided Query Denoising strategy to further enhance the training process. We also utilize Uncertainty-reduced Query Initialization, which leverages predicted 2D object location and depth information to reduce query uncertainty. As a result, our UA-Track achieves state-of-the-art performance on the nuScenes benchmark, i.e., 66.3% AMOTA on the test split, surpassing the previous best end-to-end solution by a significant margin of 8.9% AMOTA.
Deep Scene Text Detection with Connected Component Proposals
Aug 17, 2017
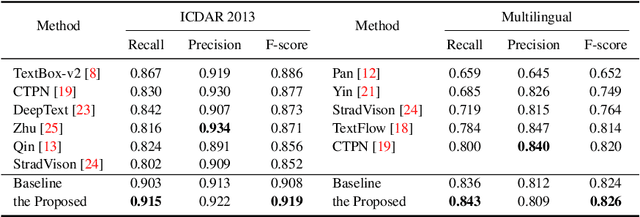
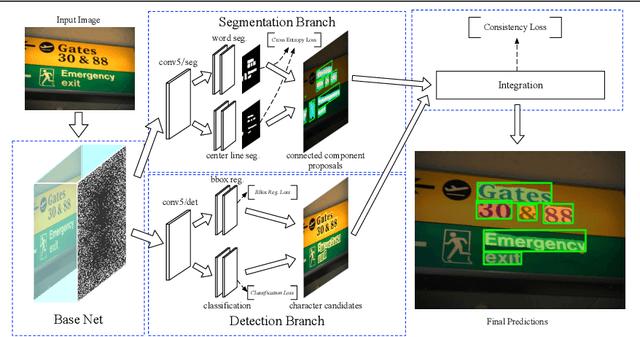
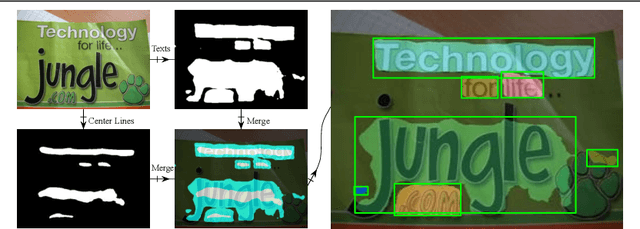
A growing demand for natural-scene text detection has been witnessed by the computer vision community since text information plays a significant role in scene understanding and image indexing. Deep neural networks are being used due to their strong capabilities of pixel-wise classification or word localization, similar to being used in common vision problems. In this paper, we present a novel two-task network with integrating bottom and top cues. The first task aims to predict a pixel-by-pixel labeling and based on which, word proposals are generated with a canonical connected component analysis. The second task aims to output a bundle of character candidates used later to verify the word proposals. The two sub-networks share base convolutional features and moreover, we present a new loss to strengthen the interaction between them. We evaluate the proposed network on public benchmark datasets and show it can detect arbitrary-orientation scene text with a finer output boundary. In ICDAR 2013 text localization task, we achieve the state-of-the-art performance with an F-score of 0.919 and a much better recall of 0.915.