 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmoWAM: Harmonizing Generalizable and Precise Manipulation via Adaptive World Action Models
May 11, 2026World Action Models (WAMs) have emerged as a promising paradigm for robot control by modeling physical dynamics. Current WAMs generally follow two paradigms: the "Imagine-then-Execute" approach, which uses video prediction to infer actions via inverse dynamics, and the "Joint Modeling" approach, which jointly models actions and video representations. Based on systematic experiments, we observe a fundamental trade-off between these paradigms: the former explicitly leverages world models for generalizable transit but lacks interaction precision, whereas the latter enables fine-grained, temporally coherent action generation but is constrained by the exploration space of the training distribution. Motivated by these findings, we propose HarmoWAM, an end-to-end WAM that fully leverages a world model to unify predictive and reactive control, enabling both generalizable transit and precise manipulation. Specifically, the world model provides spatio-temporal physical priors that condition two complementary action experts: a predictive expert that leverages latent dynamics for iterative action generation, and a reactive expert that directly infers actions from predicted visual evolution. To enable adaptive coordination, a Process-Adaptive Gating Mechanism is proposed to automatically determine the timing and location of switching between them. This allows the world model to drive the reactive expert to expand the exploration space and the predictive expert to perform precise interactions across different stages of a task. For evaluation, we construct three training-unseen test environments across six real-world robotic tasks, covering variations in background, position, and object semantics. Notably, HarmoWAM achieves strong zero-shot generalization across these scenarios, significantly outperforming prior state-of-the-art VLA models and WAMs by margins of 33% and 29%, respectively.
Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
Mar 17, 2026Vision-Language-Action (VLA) models have recently emerged as a promising paradigm for robotic manipulation, in which reliable action prediction critically depends on accurately interpreting and integrating visual observations conditioned on language instructions. Although recent works have sought to enhance the visual capabilities of VLA models, most approaches treat the LLM backbone as a black box, providing limited insight into how visual information is grounded into action generation. Therefore, we perform a systematic analysis of multiple VLA models across different action-generation paradigms and observe that sensitivity to visual tokens progressively decreases in deeper layers during action generation. Motivated by this observation, we propose \textbf{DeepVision-VLA}, built on a \textbf{Vision-Language Mixture-of-Transformers (VL-MoT)} framework. This framework enables shared attention between the vision foundation model and the VLA backbone, injecting multi-level visual features from the vision expert into deeper layers of the VLA backbone to enhance visual representations for precise and complex manipulation. In addition, we introduce \textbf{Action-Guided Visual Pruning (AGVP)}, which leverages shallow-layer attention to prune irrelevant visual tokens while preserving task-relevant ones, reinforcing critical visual cues for manipulation with minimal computational overhead. DeepVision-VLA outperforms prior state-of-the-art methods by 9.0\% and 7.5\% on simulated and real-world tasks, respectively, providing new insights for the design of visually enhanced VLA models.
TwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
Feb 09, 2026Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.
Generative Reasoning Re-ranker
Feb 08, 2026Recent studies increasingly explore Large Language Models (LLMs) as a new paradigm for recommendation systems due to their scalability and world knowledge. However, existing work has three key limitations: (1) most efforts focus on retrieval and ranking, while the reranking phase, critical for refining final recommendations, is largely overlooked; (2) LLMs are typically used in zero-shot or supervised fine-tuning settings, leaving their reasoning abilities, especially those enhanced through reinforcement learning (RL) and high-quality reasoning data, underexploited; (3) items are commonly represented by non-semantic IDs, creating major scalability challenges in industrial systems with billions of identifiers. To address these gaps, we propose the Generative Reasoning Reranker (GR2), an end-to-end framework with a three-stage training pipeline tailored for reranking. First, a pretrained LLM is mid-trained on semantic IDs encoded from non-semantic IDs via a tokenizer achieving $\ge$99% uniqueness. Next, a stronger larger-scale LLM generates high-quality reasoning traces through carefully designed prompting and rejection sampling, which are used for supervised fine-tuning to impart foundational reasoning skills. Finally, we apply Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO), enabling scalable RL supervision with verifiable rewards designed specifically for reranking. Experiments on two real-world datasets demonstrate GR2's effectiveness: it surpasses the state-of-the-art OneRec-Think by 2.4% in Recall@5 and 1.3% in NDCG@5. Ablations confirm that advanced reasoning traces yield substantial gains across metrics. We further find that RL reward design is crucial in reranking: LLMs tend to exploit reward hacking by preserving item order, motivating conditional verifiable rewards to mitigate this behavior and optimize reranking performance.
UA-Track: Uncertainty-Aware End-to-End 3D Multi-Object Tracking
Jun 04, 2024



3D multiple object tracking (MOT) plays a crucial role in autonomous driving perception. Recent end-to-end query-based trackers simultaneously detect and track objects, which have shown promising potential for the 3D MOT task. However, existing methods overlook the uncertainty issue, which refers to the lack of precise confidence about the state and location of tracked objects. Uncertainty arises owing to various factors during motion observation by cameras, especially occlusions and the small size of target objects, resulting in an inaccurate estimation of the object's position, label, and identity. To this end, we propose an Uncertainty-Aware 3D MOT framework, UA-Track, which tackles the uncertainty problem from multiple aspects. Specifically, we first introduce an Uncertainty-aware Probabilistic Decoder to capture the uncertainty in object prediction with probabilistic attention. Secondly, we propose an Uncertainty-guided Query Denoising strategy to further enhance the training process. We also utilize Uncertainty-reduced Query Initialization, which leverages predicted 2D object location and depth information to reduce query uncertainty. As a result, our UA-Track achieves state-of-the-art performance on the nuScenes benchmark, i.e., 66.3% AMOTA on the test split, surpassing the previous best end-to-end solution by a significant margin of 8.9% AMOTA.
Implicit Obstacle Map-driven Indoor Navigation Model for Robust Obstacle Avoidance
Aug 24, 2023



Robust obstacle avoidance is one of the critical steps for successful goal-driven indoor navigation tasks.Due to the obstacle missing in the visual image and the possible missed detection issue, visual image-based obstacle avoidance techniques still suffer from unsatisfactory robustness. To mitigate it, in this paper, we propose a novel implicit obstacle map-driven indoor navigation framework for robust obstacle avoidance, where an implicit obstacle map is learned based on the historical trial-and-error experience rather than the visual image. In order to further improve the navigation efficiency, a non-local target memory aggregation module is designed to leverage a non-local network to model the intrinsic relationship between the target semantic and the target orientation clues during the navigation process so as to mine the most target-correlated object clues for the navigation decision. Extensive experimental results on AI2-Thor and RoboTHOR benchmarks verify the excellent obstacle avoidance and navigation efficiency of our proposed method. The core source code is available at https://github.com/xwaiyy123/object-navigation.
Semantics-Guided Moving Object Segmentation with 3D LiDAR
May 06, 2022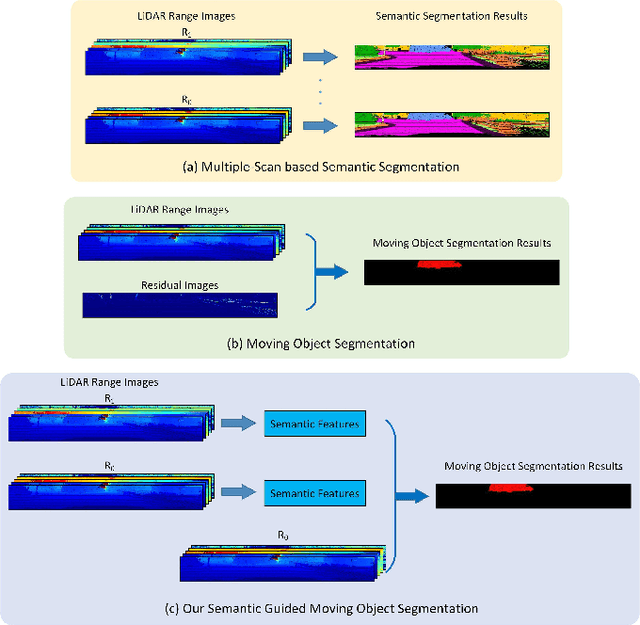
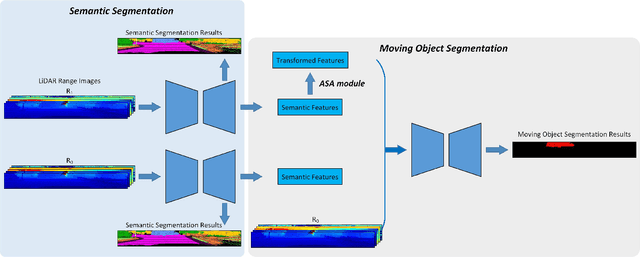

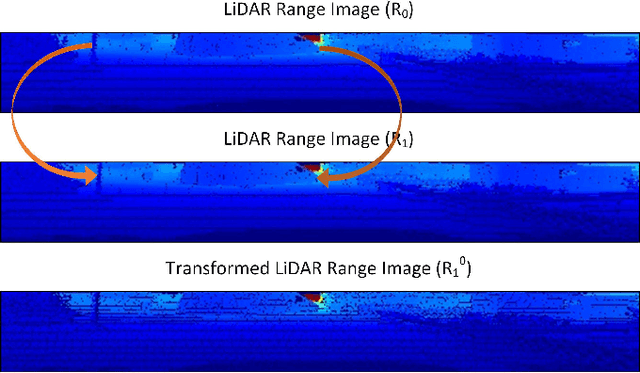
Moving object segmentation (MOS) is a task to distinguish moving objects, e.g., moving vehicles and pedestrians, from the surrounding static environment. The segmentation accuracy of MOS can have an influence on odometry, map construction, and planning tasks. In this paper, we propose a semantics-guided convolutional neural network for moving object segmentation. The network takes sequential LiDAR range images as inputs. Instead of segmenting the moving objects directly, the network conducts single-scan-based semantic segmentation and multiple-scan-based moving object segmentation in turn. The semantic segmentation module provides semantic priors for the MOS module, where we propose an adjacent scan association (ASA) module to convert the semantic features of adjacent scans into the same coordinate system to fully exploit the cross-scan semantic features. Finally, by analyzing the difference between the transformed features, reliable MOS result can be obtained quickly. Experimental results on the SemanticKITTI MOS dataset proves the effectiveness of our work.
Transformationally Identical and Invariant Convolutional Neural Networks through Symmetric Element Operators
Jul 10, 2018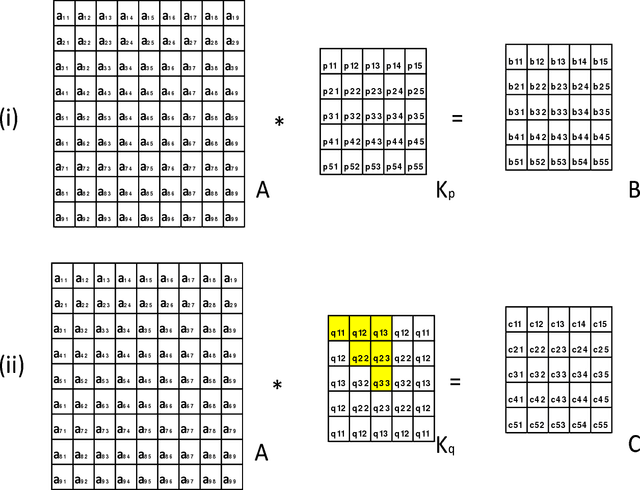
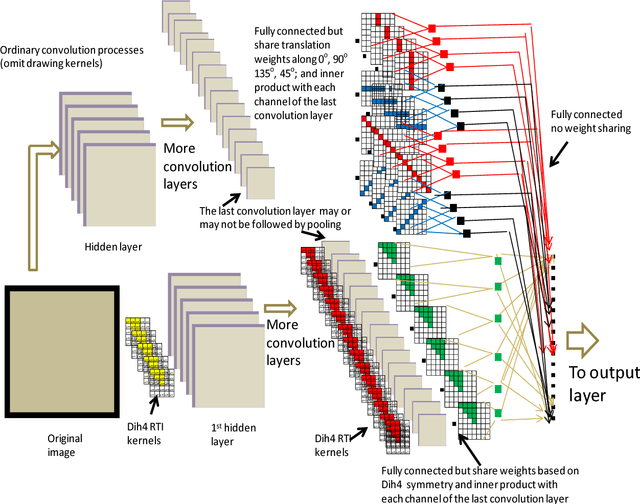
Mathematically speaking, a transformationally invariant operator, such as a transformationally identical (TI) matrix kernel (i.e., K= T{K}), commutes with the transformation (T{.}) itself when they operate on the first operand matrix. We found that by consistently applying the same type of TI kernels in a convolutional neural networks (CNN) system, the commutative property holds throughout all layers of convolution processes with and without involving an activation function and/or a 1D convolution across channels within a layer. We further found that any CNN possessing the same TI kernel property for all convolution layers followed by a flatten layer with weight sharing among their transformation corresponding elements would output the same result for all transformation versions of the original input vector. In short, CNN[ Vi ] = CNN[ T{Vi} ] providing every K = T{K} in CNN, where Vi denotes input vector and CNN[.] represents the whole CNN process as a function of input vector that produces an output vector. With such a transformationally identical CNN (TI-CNN) system, each transformation, that is not associated with a predefined TI used in data augmentation, would inherently include all of its corresponding transformation versions of the input vector for the training. Hence the use of same TI property for every kernel in the CNN would serve as an orientation or a translation independent training guide in conjunction with the error-backpropagation during the training. This TI kernel property is desirable for applications requiring a highly consistent output result from corresponding transformation versions of an input. Several C programming routines are provided to facilitate interested parties of using the TI-CNN technique which is expected to produce a better generalization performance than its ordinary CNN counterpart.