 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
Feb 23, 2023



Humans can easily imagine the complete 3D geometry of occluded objects and scenes. This appealing ability is vital for recognition and understanding. To enable such capability in AI systems, we propose VoxFormer, a Transformer-based semantic scene completion framework that can output complete 3D volumetric semantics from only 2D images. Our framework adopts a two-stage design where we start from a sparse set of visible and occupied voxel queries from depth estimation, followed by a densification stage that generates dense 3D voxels from the sparse ones. A key idea of this design is that the visual features on 2D images correspond only to the visible scene structures rather than the occluded or empty spaces. Therefore, starting with the featurization and prediction of the visible structures is more reliable. Once we obtain the set of sparse queries, we apply a masked autoencoder design to propagate the information to all the voxels by self-attention. Experiments on SemanticKITTI show that VoxFormer outperforms the state of the art with a relative improvement of 20.0% in geometry and 18.1% in semantics and reduces GPU memory during training by ~45% to less than 16GB. Our code is available on https://github.com/NVlabs/VoxFormer.
Re-ViLM: Retrieval-Augmented Visual Language Model for Zero and Few-Shot Image Captioning
Feb 09, 2023



Augmenting pretrained language models (LMs) with a vision encoder (e.g., Flamingo) has obtained state-of-the-art results in image-to-text generation. However, these models store all the knowledge within their parameters, thus often requiring enormous model parameters to model the abundant visual concepts and very rich textual descriptions. Additionally, they are inefficient in incorporating new data, requiring a computational-expensive fine-tuning process. In this work, we introduce a Retrieval-augmented Visual Language Model, Re-ViLM, built upon the Flamingo, that supports retrieving the relevant knowledge from the external database for zero and in-context few-shot image-to-text generations. By storing certain knowledge explicitly in the external database, our approach reduces the number of model parameters and can easily accommodate new data during evaluation by simply updating the database. We also construct an interleaved image and text data that facilitates in-context few-shot learning capabilities. We demonstrate that Re-ViLM significantly boosts performance for image-to-text generation tasks, especially for zero-shot and few-shot generation in out-of-domain settings with 4 times less parameters compared with baseline methods.
Vision Transformers Are Good Mask Auto-Labelers
Jan 10, 2023We propose Mask Auto-Labeler (MAL), a high-quality Transformer-based mask auto-labeling framework for instance segmentation using only box annotations. MAL takes box-cropped images as inputs and conditionally generates their mask pseudo-labels.We show that Vision Transformers are good mask auto-labelers. Our method significantly reduces the gap between auto-labeling and human annotation regarding mask quality. Instance segmentation models trained using the MAL-generated masks can nearly match the performance of their fully-supervised counterparts, retaining up to 97.4\% performance of fully supervised models. The best model achieves 44.1\% mAP on COCO instance segmentation (test-dev 2017), outperforming state-of-the-art box-supervised methods by significant margins. Qualitative results indicate that masks produced by MAL are, in some cases, even better than human annotations.
1st Place Solution of The Robust Vision Challenge 2022 Semantic Segmentation Track
Nov 07, 2022This report describes the winning solution to the Robust Vision Challenge (RVC) semantic segmentation track at ECCV 2022. Our method adopts the FAN-B-Hybrid model as the encoder and uses SegFormer as the segmentation framework. The model is trained on a composite dataset consisting of images from 9 datasets (ADE20K, Cityscapes, Mapillary Vistas, ScanNet, VIPER, WildDash 2, IDD, BDD, and COCO) with a simple dataset balancing strategy. All the original labels are projected to a 256-class unified label space, and the model is trained using a cross-entropy loss. Without significant hyperparameter tuning or any specific loss weighting, our solution ranks the first place on all the testing semantic segmentation benchmarks from multiple domains (ADE20K, Cityscapes, Mapillary Vistas, ScanNet, VIPER, and WildDash 2). The proposed method can serve as a strong baseline for the multi-domain segmentation task and benefit future works. Code will be available at https://github.com/lambert-x/RVC_Segmentation.
Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models
Sep 15, 2022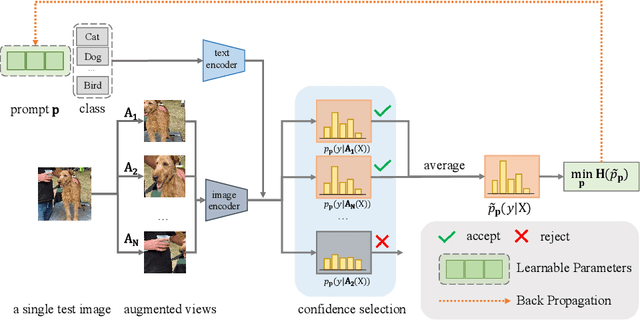
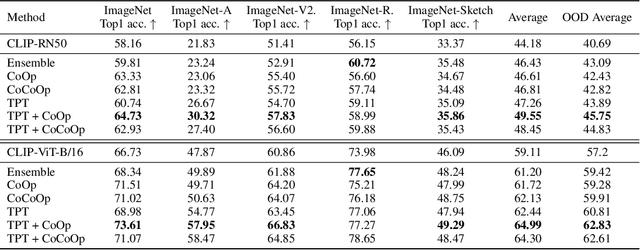
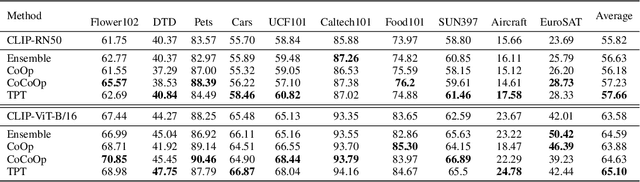
Pre-trained vision-language models (e.g., CLIP) have shown promising zero-shot generalization in many downstream tasks with properly designed text prompts. Instead of relying on hand-engineered prompts, recent works learn prompts using the training data from downstream tasks. While effective, training on domain-specific data reduces a model's generalization capability to unseen new domains. In this work, we propose test-time prompt tuning (TPT), a method that can learn adaptive prompts on the fly with a single test sample. For image classification, TPT optimizes the prompt by minimizing the entropy with confidence selection so that the model has consistent predictions across different augmented views of each test sample. In evaluating generalization to natural distribution shifts, TPT improves the zero-shot top-1 accuracy of CLIP by 3.6% on average, surpassing previous prompt tuning approaches that require additional task-specific training data. In evaluating cross-dataset generalization with unseen categories, TPT performs on par with the state-of-the-art approaches that use additional training data. Project page: https://azshue.github.io/TPT.
PointDP: Diffusion-driven Purification against Adversarial Attacks on 3D Point Cloud Recognition
Aug 21, 2022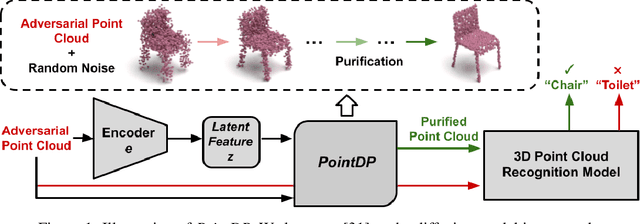

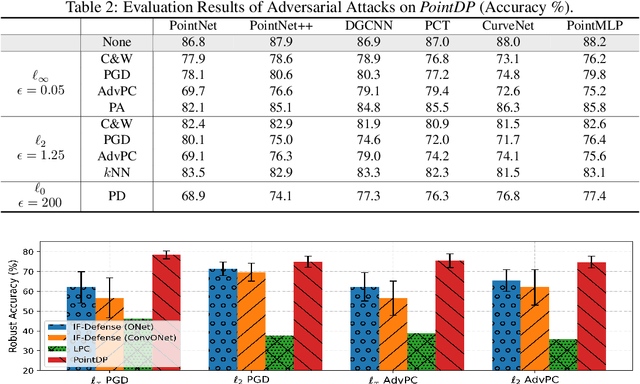
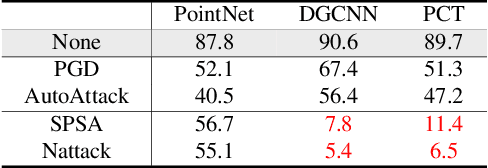
3D Point cloud is becoming a critical data representation in many real-world applications like autonomous driving, robotics, and medical imaging. Although the success of deep learning further accelerates the adoption of 3D point clouds in the physical world, deep learning is notorious for its vulnerability to adversarial attacks. In this work, we first identify that the state-of-the-art empirical defense, adversarial training, has a major limitation in applying to 3D point cloud models due to gradient obfuscation. We further propose PointDP, a purification strategy that leverages diffusion models to defend against 3D adversarial attacks. We extensively evaluate PointDP on six representative 3D point cloud architectures, and leverage 10+ strong and adaptive attacks to demonstrate its lower-bound robustness. Our evaluation shows that PointDP achieves significantly better robustness than state-of-the-art purification methods under strong attacks. Results of certified defenses on randomized smoothing combined with PointDP will be included in the near future.
MinVIS: A Minimal Video Instance Segmentation Framework without Video-based Training
Aug 03, 2022
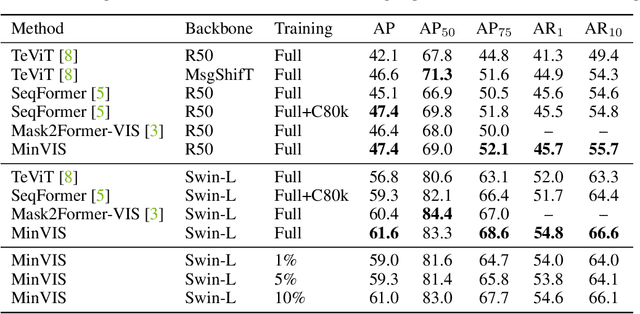
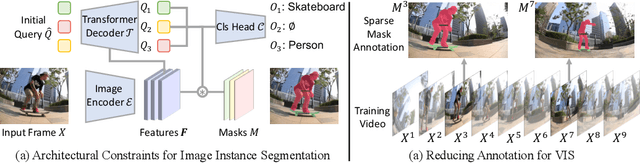
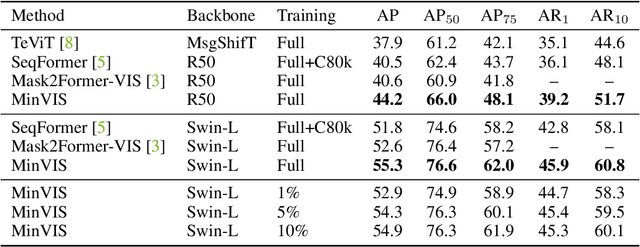
We propose MinVIS, a minimal video instance segmentation (VIS) framework that achieves state-of-the-art VIS performance with neither video-based architectures nor training procedures. By only training a query-based image instance segmentation model, MinVIS outperforms the previous best result on the challenging Occluded VIS dataset by over 10% AP. Since MinVIS treats frames in training videos as independent images, we can drastically sub-sample the annotated frames in training videos without any modifications. With only 1% of labeled frames, MinVIS outperforms or is comparable to fully-supervised state-of-the-art approaches on YouTube-VIS 2019/2021. Our key observation is that queries trained to be discriminative between intra-frame object instances are temporally consistent and can be used to track instances without any manually designed heuristics. MinVIS thus has the following inference pipeline: we first apply the trained query-based image instance segmentation to video frames independently. The segmented instances are then tracked by bipartite matching of the corresponding queries. This inference is done in an online fashion and does not need to process the whole video at once. MinVIS thus has the practical advantages of reducing both the labeling costs and the memory requirements, while not sacrificing the VIS performance. Code is available at: https://github.com/NVlabs/MinVIS
How Much More Data Do I Need? Estimating Requirements for Downstream Tasks
Jul 13, 2022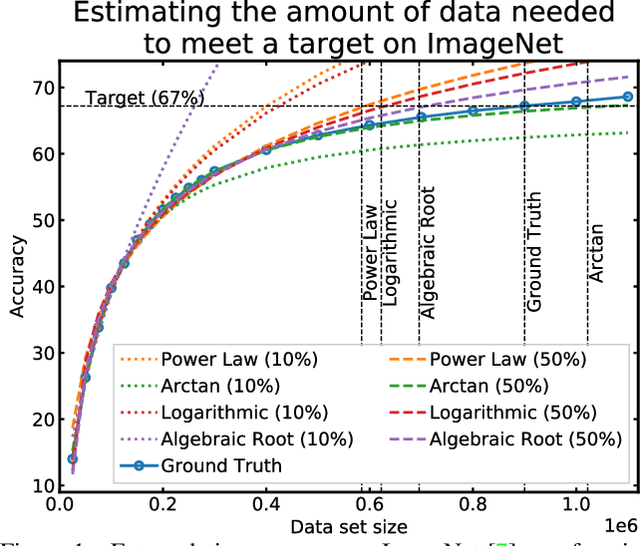

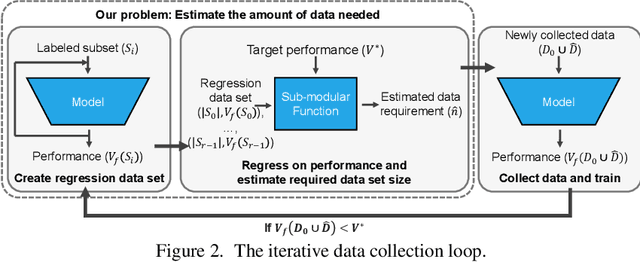
Given a small training data set and a learning algorithm, how much more data is necessary to reach a target validation or test performance? This question is of critical importance in applications such as autonomous driving or medical imaging where collecting data is expensive and time-consuming. Overestimating or underestimating data requirements incurs substantial costs that could be avoided with an adequate budget. Prior work on neural scaling laws suggest that the power-law function can fit the validation performance curve and extrapolate it to larger data set sizes. We find that this does not immediately translate to the more difficult downstream task of estimating the required data set size to meet a target performance. In this work, we consider a broad class of computer vision tasks and systematically investigate a family of functions that generalize the power-law function to allow for better estimation of data requirements. Finally, we show that incorporating a tuned correction factor and collecting over multiple rounds significantly improves the performance of the data estimators. Using our guidelines, practitioners can accurately estimate data requirements of machine learning systems to gain savings in both development time and data acquisition costs.
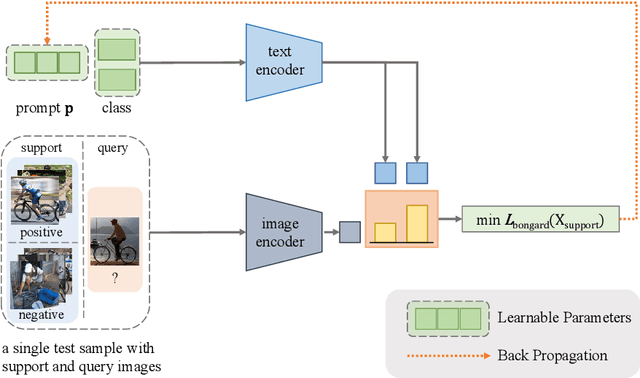
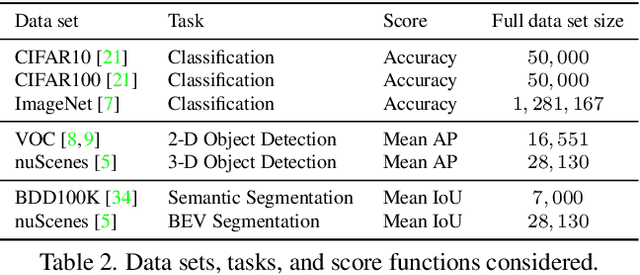
Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions
May 27, 2022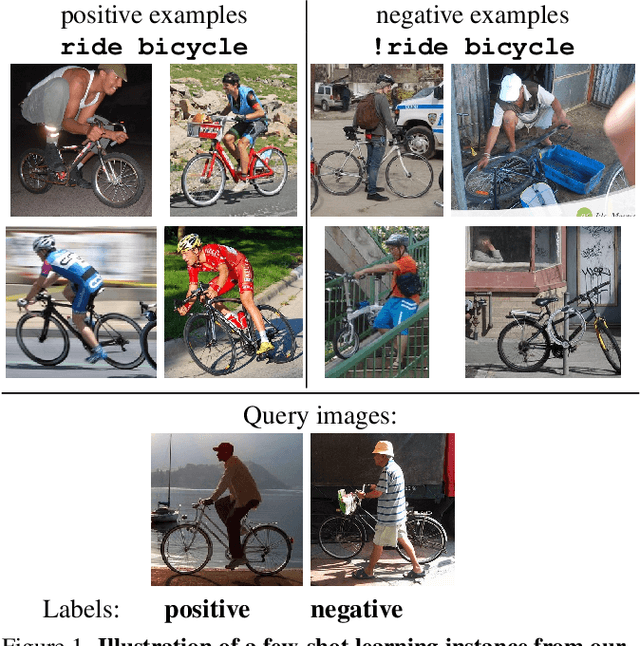
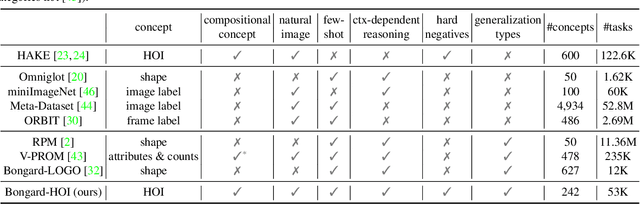

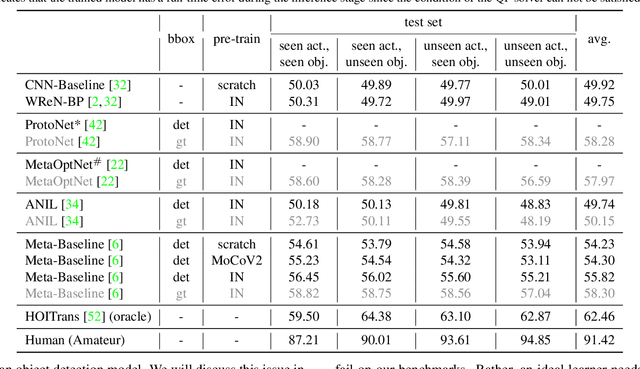
A significant gap remains between today's visual pattern recognition models and human-level visual cognition especially when it comes to few-shot learning and compositional reasoning of novel concepts. We introduce Bongard-HOI, a new visual reasoning benchmark that focuses on compositional learning of human-object interactions (HOIs) from natural images. It is inspired by two desirable characteristics from the classical Bongard problems (BPs): 1) few-shot concept learning, and 2) context-dependent reasoning. We carefully curate the few-shot instances with hard negatives, where positive and negative images only disagree on action labels, making mere recognition of object categories insufficient to complete our benchmarks. We also design multiple test sets to systematically study the generalization of visual learning models, where we vary the overlap of the HOI concepts between the training and test sets of few-shot instances, from partial to no overlaps. Bongard-HOI presents a substantial challenge to today's visual recognition models. The state-of-the-art HOI detection model achieves only 62% accuracy on few-shot binary prediction while even amateur human testers on MTurk have 91% accuracy. With the Bongard-HOI benchmark, we hope to further advance research efforts in visual reasoning, especially in holistic perception-reasoning systems and better representation learning.
Understanding The Robustness in Vision Transformers
Apr 27, 2022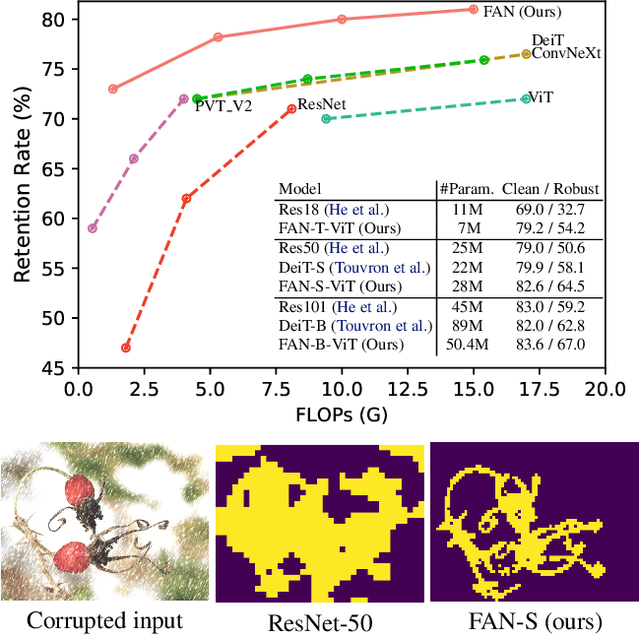

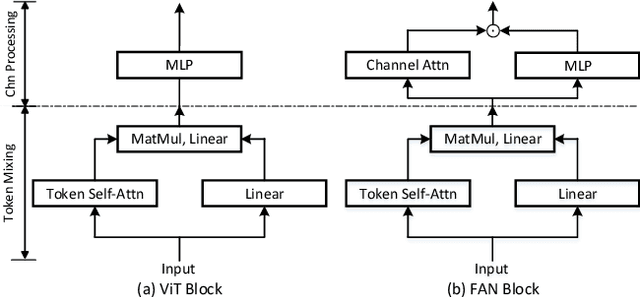
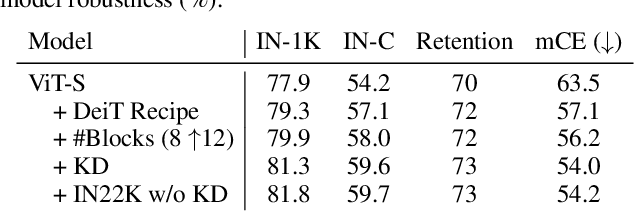
Recent studies show that Vision Transformers(ViTs) exhibit strong robustness against various corruptions. Although this property is partly attributed to the self-attention mechanism, there is still a lack of systematic understanding. In this paper, we examine the role of self-attention in learning robust representations. Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. We further propose a family of fully attentional networks (FANs) that strengthen this capability by incorporating an attentional channel processing design. We validate the design comprehensively on various hierarchical backbones. Our model achieves a state of-the-art 87.1% accuracy and 35.8% mCE on ImageNet-1k and ImageNet-C with 76.8M parameters. We also demonstrate state-of-the-art accuracy and robustness in two downstream tasks: semantic segmentation and object detection. Code will be available at https://github.com/NVlabs/FAN.