 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Balanced Graph Edge Partition with Effective Local Search
Dec 17, 2020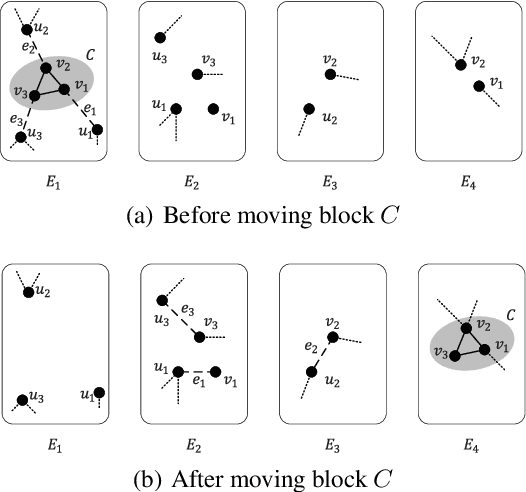
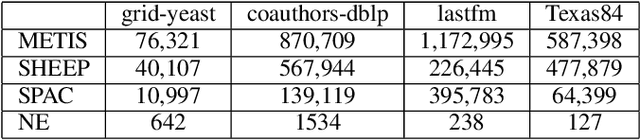
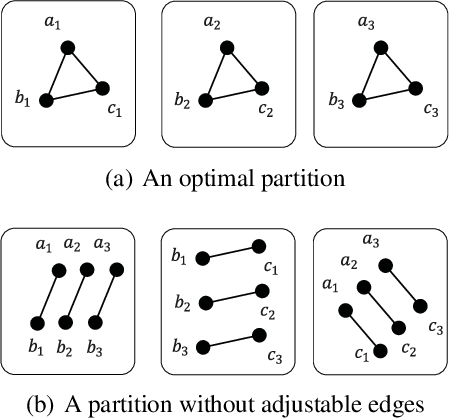
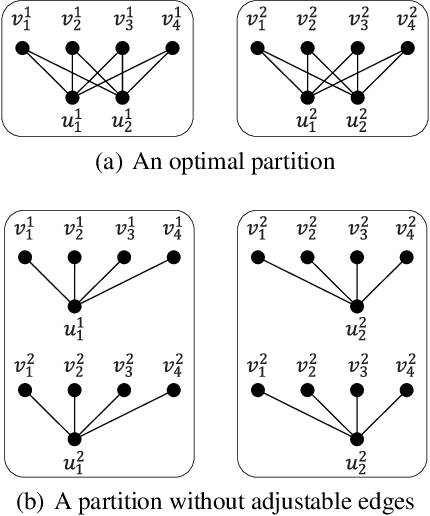
Graph partition is a key component to achieve workload balance and reduce job completion time in parallel graph processing systems. Among the various partition strategies, edge partition has demonstrated more promising performance in power-law graphs than vertex partition and thereby has been more widely adopted as the default partition strategy by existing graph systems. The graph edge partition problem, which is to split the edge set into multiple balanced parts to minimize the total number of copied vertices, has been widely studied from the view of optimization and algorithms. In this paper, we study local search algorithms for this problem to further improve the partition results from existing methods. More specifically, we propose two novel concepts, namely adjustable edges and blocks. Based on these, we develop a greedy heuristic as well as an improved search algorithm utilizing the property of the max-flow model. To evaluate the performance of our algorithms, we first provide adequate theoretical analysis in terms of the approximation quality. We significantly improve the previously known approximation ratio for this problem. Then we conduct extensive experiments on a large number of benchmark datasets and state-of-the-art edge partition strategies. The results show that our proposed local search framework can further improve the quality of graph partition by a wide margin.
APAN: Asynchronous Propagation Attention Network for Real-time Temporal Graph Embedding
Dec 16, 2020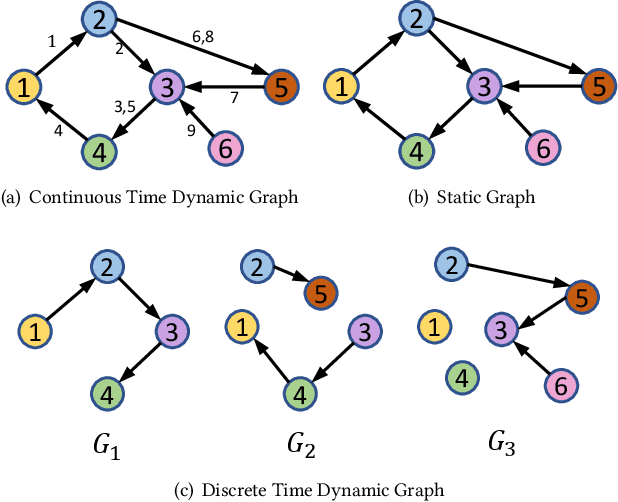
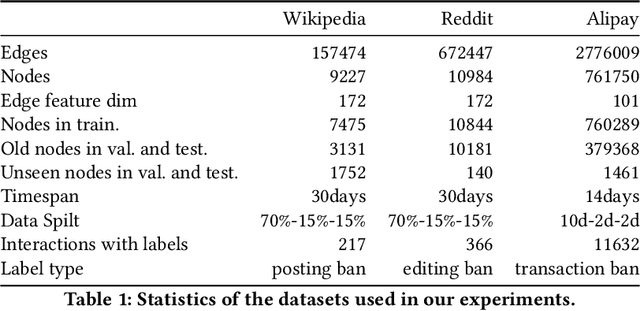
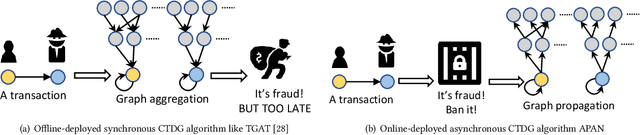
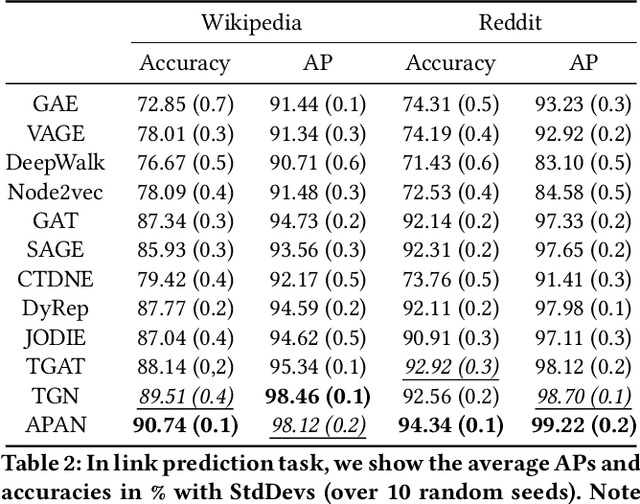
Limited by the time complexity of querying k-hop neighbors in a graph database, most graph algorithms cannot be deployed online and execute millisecond-level inference. This problem dramatically limits the potential of applying graph algorithms in certain areas, such as financial fraud detection. Therefore, we propose Asynchronous Propagation Attention Network, an asynchronous continuous time dynamic graph algorithm for real-time temporal graph embedding. Traditional graph models usually execute two serial operations: first graph computation and then model inference. We decouple model inference and graph computation step so that the heavy graph query operations will not damage the speed of model inference. Extensive experiments demonstrate that the proposed method can achieve competitive performance and 8.7 times inference speed improvement in the meantime.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
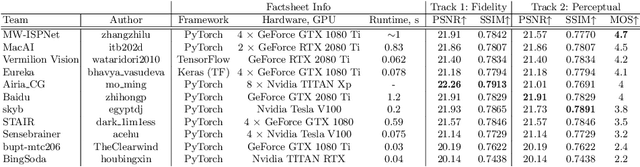
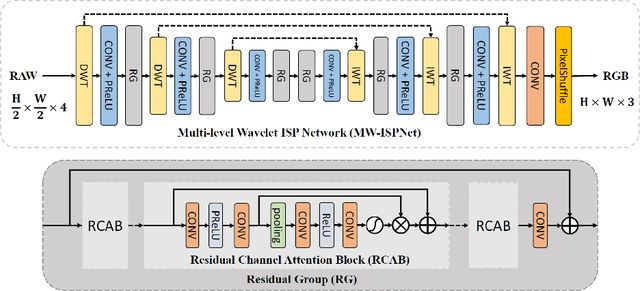
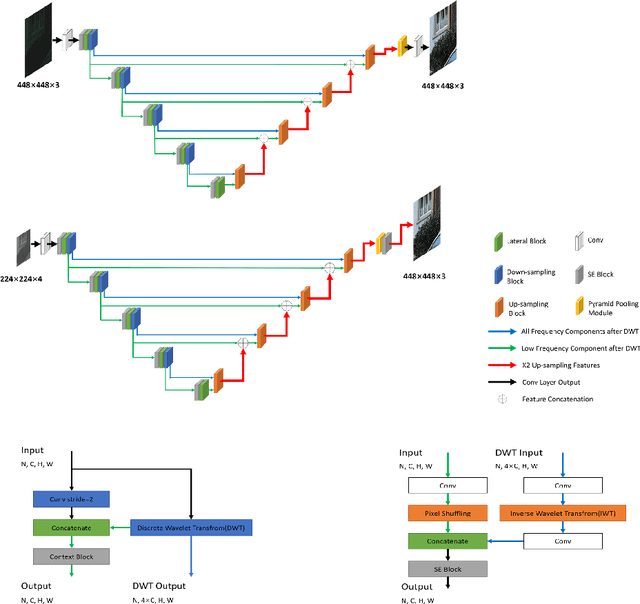
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020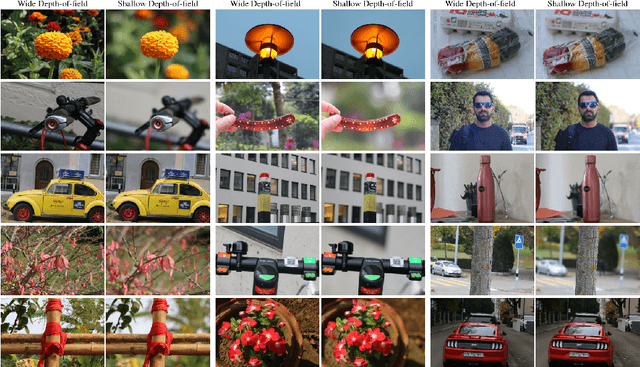


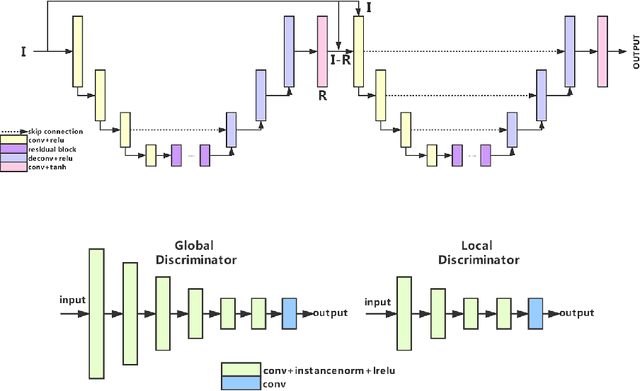
This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
BGGAN: Bokeh-Glass Generative Adversarial Network for Rendering Realistic Bokeh
Nov 04, 2020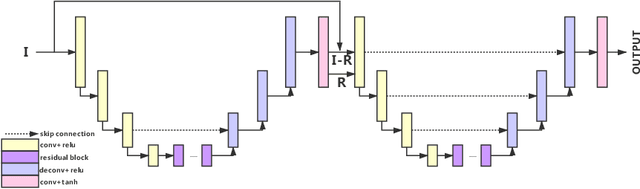
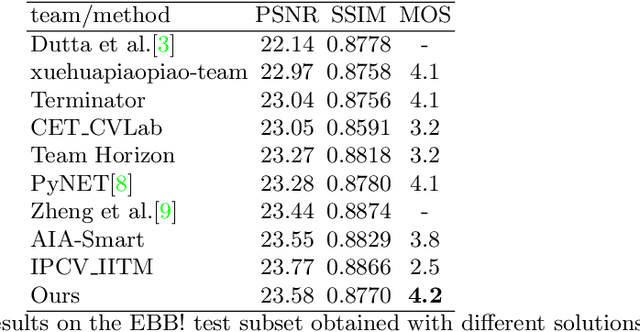
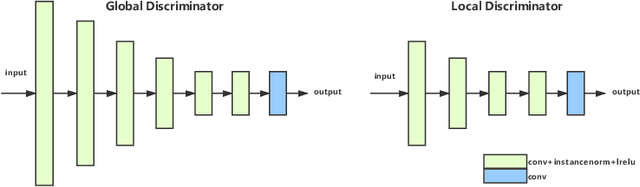
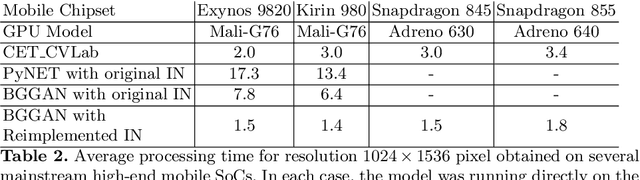
A photo captured with bokeh effect often means objects in focus are sharp while the out-of-focus areas are all blurred. DSLR can easily render this kind of effect naturally. However, due to the limitation of sensors, smartphones cannot capture images with depth-of-field effects directly. In this paper, we propose a novel generator called Glass-Net, which generates bokeh images not relying on complex hardware. Meanwhile, the GAN-based method and perceptual loss are combined for rendering a realistic bokeh effect in the stage of finetuning the model. Moreover, Instance Normalization(IN) is reimplemented in our network, which ensures our tflite model with IN can be accelerated on smartphone GPU. Experiments show that our method is able to render a high-quality bokeh effect and process one $1024 \times 1536$ pixel image in 1.9 seconds on all smartphone chipsets. This approach ranked First in AIM 2020 Rendering Realistic Bokeh Challenge Track 1 \& Track 2.
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020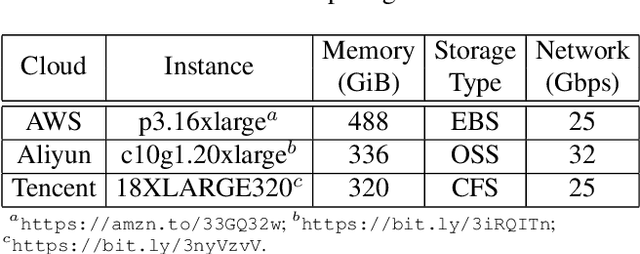
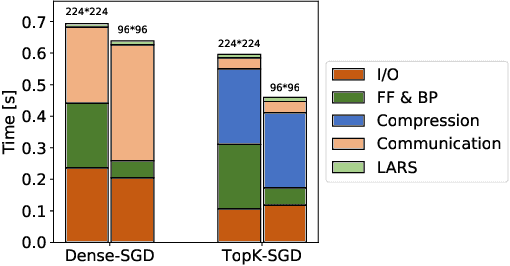
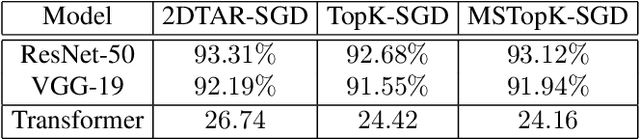
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.
Distributed Equivalent Substitution Training for Large-Scale Recommender Systems
Sep 10, 2019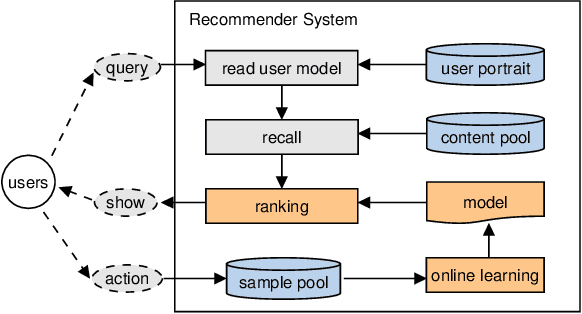
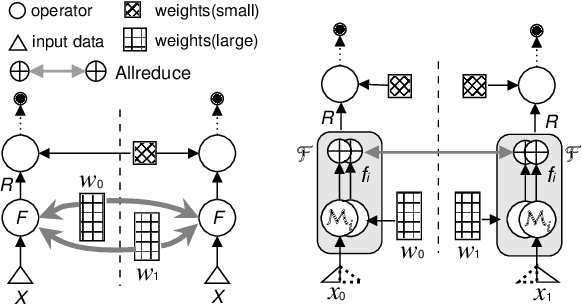
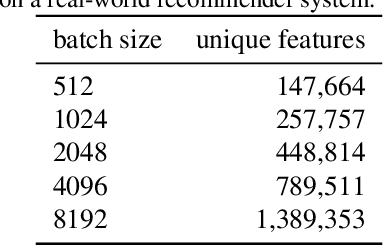
We present Distributed Equivalent Substitution (DES) training, a novel distributed training framework for recommender systems with large-scale dynamic sparse features. Our framework achieves faster convergence with less communication overhead and better computing resource utilization. DES strategy splits a weights-rich operator into sub-operators with co-located weights and aggregates partial results with much smaller communication cost to form a computationally equivalent substitution to the original operator. We show that for different types of models that recommender systems use, we can always find computational equivalent substitutions and splitting strategies for their weights-rich operators with theoretical communication load reduced ranging from 72.26% to 99.77%. We also present an implementation of DES that outperforms state-of-the-art recommender systems. Experiments show that our framework achieves up to 83% communication savings compared to other recommender systems, and can bring up to 4.5x improvement on throughput for deep models.
Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes
Jul 30, 2018
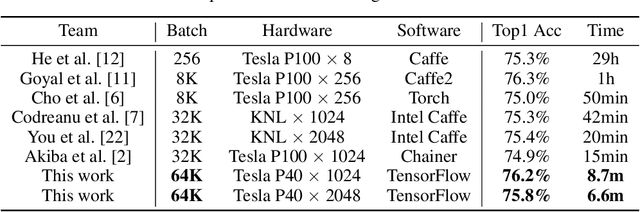

Synchronized stochastic gradient descent (SGD) optimizers with data parallelism are widely used in training large-scale deep neural networks. Although using larger mini-batch sizes can improve the system scalability by reducing the communication-to-computation ratio, it may hurt the generalization ability of the models. To this end, we build a highly scalable deep learning training system for dense GPU clusters with three main contributions: (1) We propose a mixed-precision training method that significantly improves the training throughput of a single GPU without losing accuracy. (2) We propose an optimization approach for extremely large mini-batch size (up to 64k) that can train CNN models on the ImageNet dataset without losing accuracy. (3) We propose highly optimized all-reduce algorithms that achieve up to 3x and 11x speedup on AlexNet and ResNet-50 respectively than NCCL-based training on a cluster with 1024 Tesla P40 GPUs. On training ResNet-50 with 90 epochs, the state-of-the-art GPU-based system with 1024 Tesla P100 GPUs spent 15 minutes and achieved 74.9\% top-1 test accuracy, and another KNL-based system with 2048 Intel KNLs spent 20 minutes and achieved 75.4\% accuracy. Our training system can achieve 75.8\% top-1 test accuracy in only 6.6 minutes using 2048 Tesla P40 GPUs. When training AlexNet with 95 epochs, our system can achieve 58.7\% top-1 test accuracy within 4 minutes, which also outperforms all other existing systems.
An Adaptive Descriptor Design for Object Recognition in the Wild
May 01, 2013
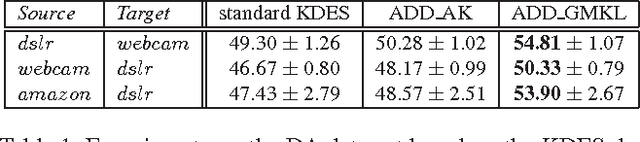
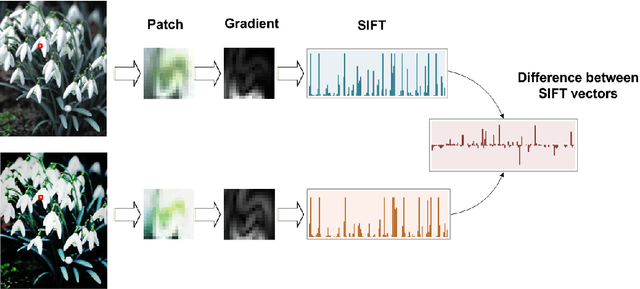
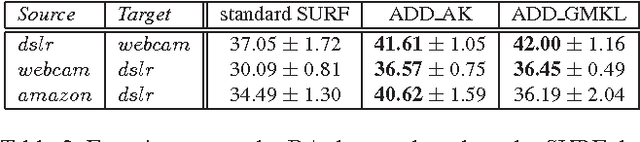
Digital images nowadays have various styles of appearance, in the aspects of color tones, contrast, vignetting, and etc. These 'picture styles' are directly related to the scene radiance, image pipeline of the camera, and post processing functions. Due to the complexity and nonlinearity of these causes, popular gradient-based image descriptors won't be invariant to different picture styles, which will decline the performance of object recognition. Given that images shared online or created by individual users are taken with a wide range of devices and may be processed by various post processing functions, to find a robust object recognition system is useful and challenging. In this paper, we present the first study on the influence of picture styles for object recognition, and propose an adaptive approach based on the kernel view of gradient descriptors and multiple kernel learning, without estimating or specifying the styles of images used in training and testing. We conduct experiments on Domain Adaptation data set and Oxford Flower data set. The experiments also include several variants of the flower data set by processing the images with popular photo effects. The results demonstrate that our proposed method improve from standard descriptors in all cases.