 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Domain Generalization via Geometric Consistency for LiDAR Semantic Segmentation
Feb 16, 2026Domain-generalized LiDAR semantic segmentation (LSS) seeks to train models on source-domain point clouds that generalize reliably to multiple unseen target domains, which is essential for real-world LiDAR applications. However, existing approaches assume similar acquisition views (e.g., vehicle-mounted) and struggle in cross-view scenarios, where observations differ substantially due to viewpoint-dependent structural incompleteness and non-uniform point density. Accordingly, we formulate cross-view domain generalization for LiDAR semantic segmentation and propose a novel framework, termed CVGC (Cross-View Geometric Consistency). Specifically, we introduce a cross-view geometric augmentation module that models viewpoint-induced variations in visibility and sampling density, generating multiple cross-view observations of the same scene. Subsequently, a geometric consistency module enforces consistent semantic and occupancy predictions across geometrically augmented point clouds of the same scene. Extensive experiments on six public LiDAR datasets establish the first systematic evaluation of cross-view domain generalization for LiDAR semantic segmentation, demonstrating that CVGC consistently outperforms state-of-the-art methods when generalizing from a single source domain to multiple target domains with heterogeneous acquisition viewpoints. The source code will be publicly available at https://github.com/KintomZi/CVGC-DG
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
IF-Bench: Benchmarking and Enhancing MLLMs for Infrared Images with Generative Visual Prompting
Dec 10, 2025Recent advances in multimodal large language models (MLLMs) have led to impressive progress across various benchmarks. However, their capability in understanding infrared images remains unexplored. To address this gap, we introduce IF-Bench, the first high-quality benchmark designed for evaluating multimodal understanding of infrared images. IF-Bench consists of 499 images sourced from 23 infrared datasets and 680 carefully curated visual question-answer pairs, covering 10 essential dimensions of image understanding. Based on this benchmark, we systematically evaluate over 40 open-source and closed-source MLLMs, employing cyclic evaluation, bilingual assessment, and hybrid judgment strategies to enhance the reliability of the results. Our analysis reveals how model scale, architecture, and inference paradigms affect infrared image comprehension, providing valuable insights for this area. Furthermore, we propose a training-free generative visual prompting (GenViP) method, which leverages advanced image editing models to translate infrared images into semantically and spatially aligned RGB counterparts, thereby mitigating domain distribution shifts. Extensive experiments demonstrate that our method consistently yields significant performance improvements across a wide range of MLLMs. The benchmark and code are available at https://github.com/casiatao/IF-Bench.
A Spatial-channel-temporal-fused Attention for Spiking Neural Networks
Sep 22, 2022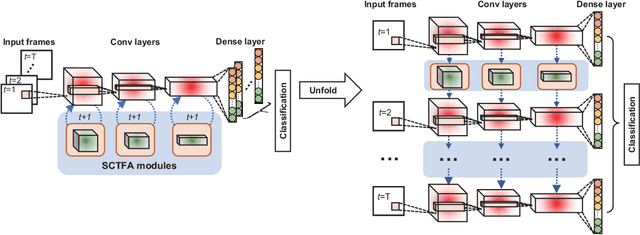
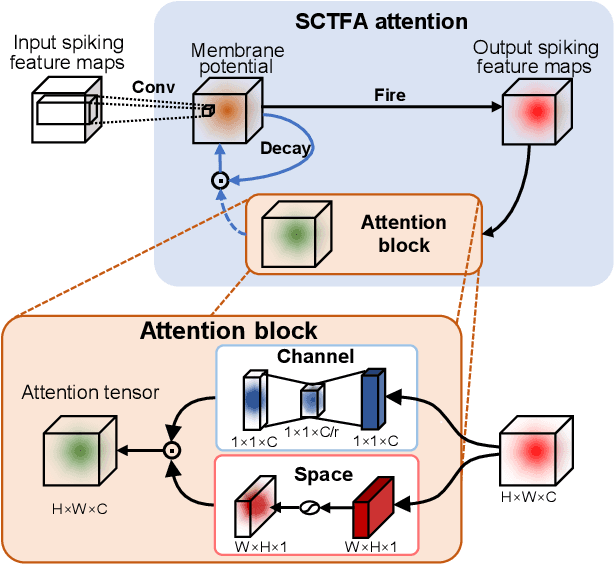
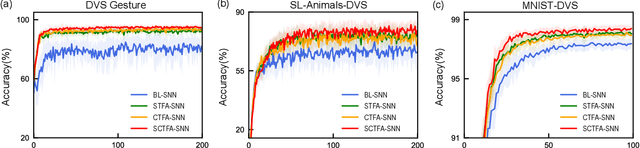
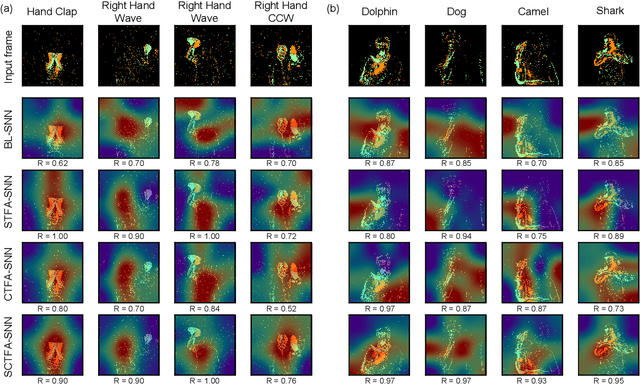
Spiking neural networks (SNNs) mimic brain computational strategies, and exhibit substantial capabilities in spatiotemporal information processing. As an essential factor for human perception, visual attention refers to the dynamic selection process of salient regions in biological vision systems. Although mechanisms of visual attention have achieved great success in computer vision, they are rarely introduced into SNNs. Inspired by experimental observations on predictive attentional remapping, we here propose a new spatial-channel-temporal-fused attention (SCTFA) module that can guide SNNs to efficiently capture underlying target regions by utilizing historically accumulated spatial-channel information. Through a systematic evaluation on three event stream datasets (DVS Gesture, SL-Animals-DVS and MNIST-DVS), we demonstrate that the SNN with the SCTFA module (SCTFA-SNN) not only significantly outperforms the baseline SNN (BL-SNN) and other two SNN models with degenerated attention modules, but also achieves competitive accuracy with existing state-of-the-art methods. Additionally, our detailed analysis shows that the proposed SCTFA-SNN model has strong robustness to noise and outstanding stability to incomplete data, while maintaining acceptable complexity and efficiency. Overall, these findings indicate that appropriately incorporating cognitive mechanisms of the brain may provide a promising approach to elevate the capability of SNNs.
A Synapse-Threshold Synergistic Learning Approach for Spiking Neural Networks
Jun 10, 2022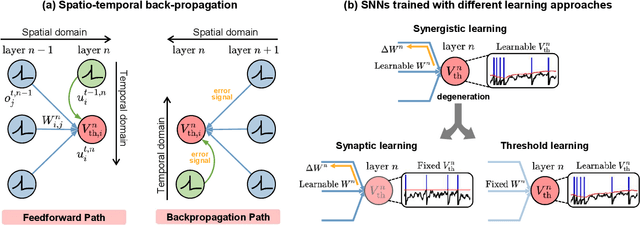
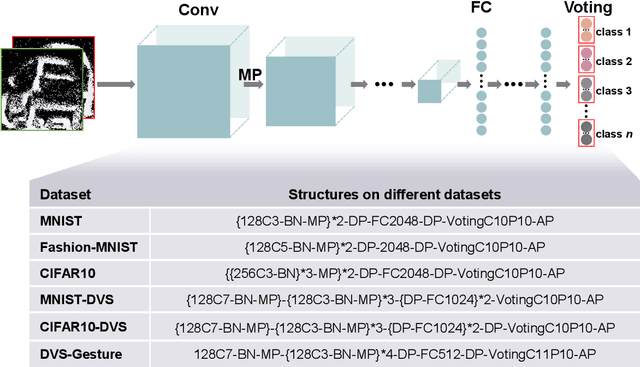
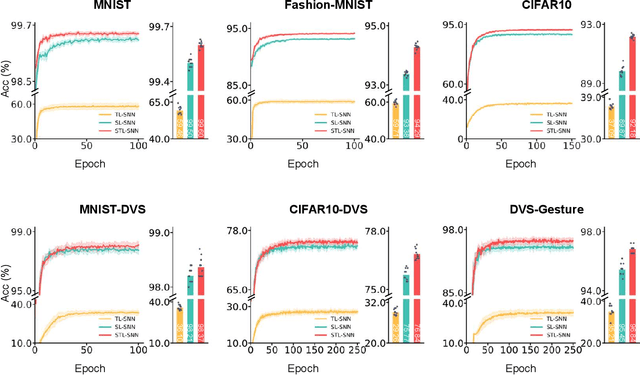
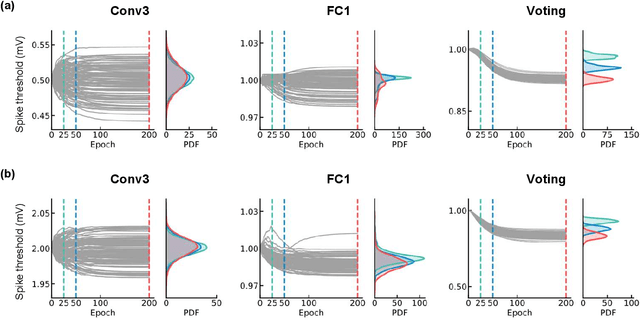
Spiking neural networks (SNNs) have demonstrated excellent capabilities in various intelligent scenarios. Most existing methods for training SNNs are based on the concept of synaptic plasticity; however, learning in the realistic brain also utilizes intrinsic non-synaptic mechanisms of neurons. The spike threshold of biological neurons is a critical intrinsic neuronal feature that exhibits rich dynamics on a millisecond timescale and has been proposed as an underlying mechanism that facilitates neural information processing. In this study, we develop a novel synergistic learning approach that simultaneously trains synaptic weights and spike thresholds in SNNs. SNNs trained with synapse-threshold synergistic learning (STL-SNNs) achieve significantly higher accuracies on various static and neuromorphic datasets than SNNs trained with two single-learning models of the synaptic learning (SL) and the threshold learning (TL). During training, the synergistic learning approach optimizes neural thresholds, providing the network with stable signal transmission via appropriate firing rates. Further analysis indicates that STL-SNNs are robust to noisy data and exhibit low energy consumption for deep network structures. Additionally, the performance of STL-SNN can be further improved by introducing a generalized joint decision framework (JDF). Overall, our findings indicate that biologically plausible synergies between synaptic and intrinsic non-synaptic mechanisms may provide a promising approach for developing highly efficient SNN learning methods.
APAN: Asynchronous Propagation Attention Network for Real-time Temporal Graph Embedding
Dec 16, 2020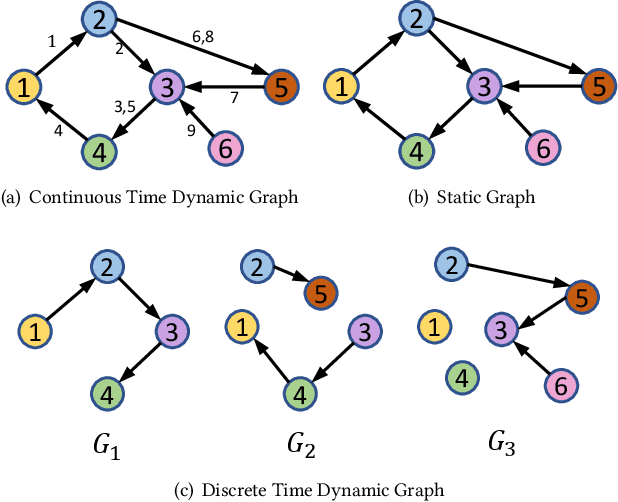
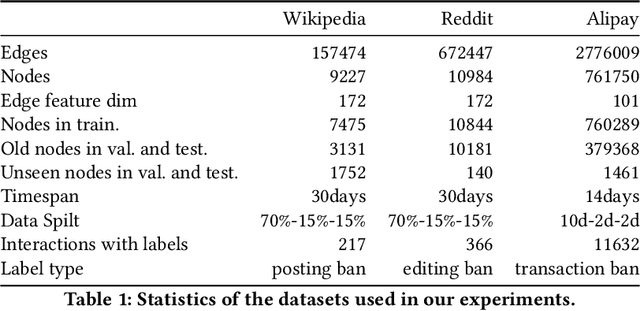
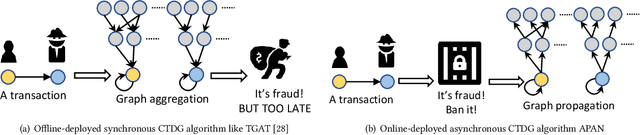
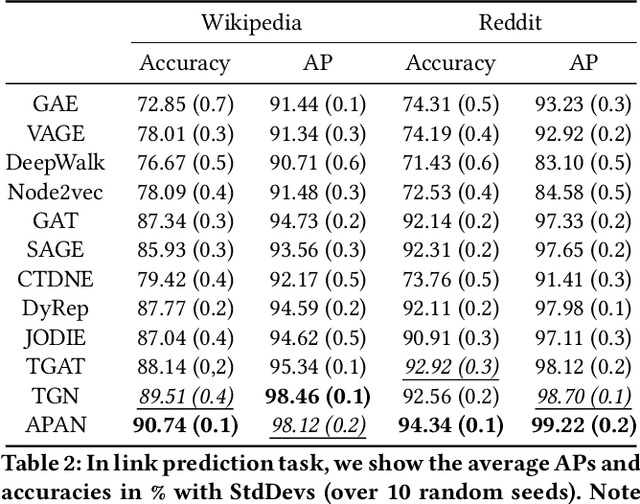
Limited by the time complexity of querying k-hop neighbors in a graph database, most graph algorithms cannot be deployed online and execute millisecond-level inference. This problem dramatically limits the potential of applying graph algorithms in certain areas, such as financial fraud detection. Therefore, we propose Asynchronous Propagation Attention Network, an asynchronous continuous time dynamic graph algorithm for real-time temporal graph embedding. Traditional graph models usually execute two serial operations: first graph computation and then model inference. We decouple model inference and graph computation step so that the heavy graph query operations will not damage the speed of model inference. Extensive experiments demonstrate that the proposed method can achieve competitive performance and 8.7 times inference speed improvement in the meantime.