 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPAN: Asynchronous Propagation Attention Network for Real-time Temporal Graph Embedding
Dec 16, 2020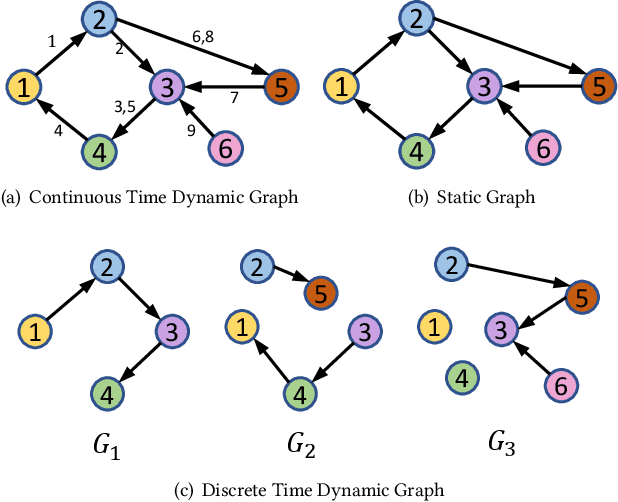
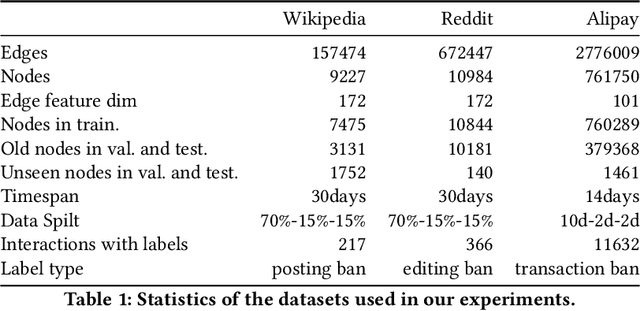
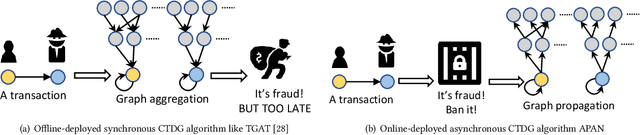
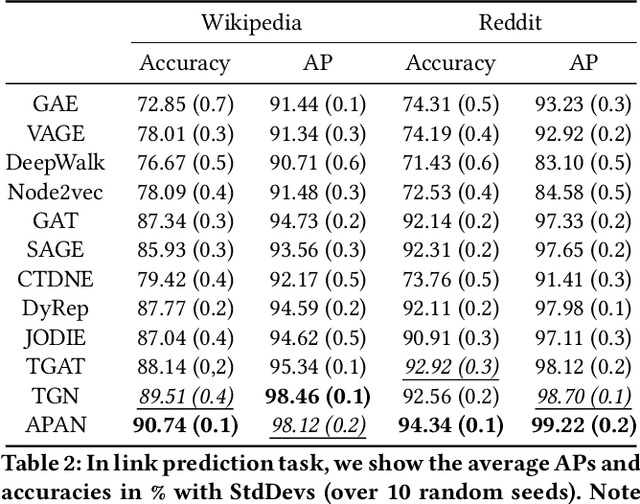
Limited by the time complexity of querying k-hop neighbors in a graph database, most graph algorithms cannot be deployed online and execute millisecond-level inference. This problem dramatically limits the potential of applying graph algorithms in certain areas, such as financial fraud detection. Therefore, we propose Asynchronous Propagation Attention Network, an asynchronous continuous time dynamic graph algorithm for real-time temporal graph embedding. Traditional graph models usually execute two serial operations: first graph computation and then model inference. We decouple model inference and graph computation step so that the heavy graph query operations will not damage the speed of model inference. Extensive experiments demonstrate that the proposed method can achieve competitive performance and 8.7 times inference speed improvement in the meantime.
OCGNN: One-class Classification with Graph Neural Networks
Feb 22, 2020
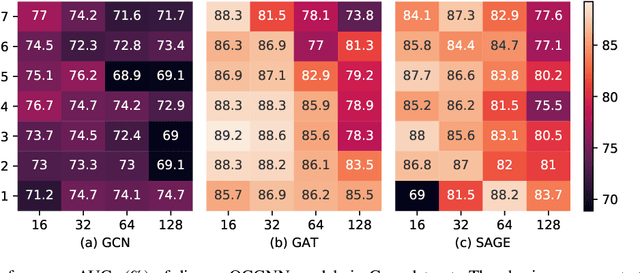
Nowadays, graph-structured data are increasingly used to model complex systems. Meanwhile, detecting anomalies from graph has become a vital research problem of pressing societal concerns. Anomaly detection is an unsupervised learning task of identifying rare data that differ from the majority. As one of the dominant anomaly detection algorithms, One Class Support Vector Machine has been widely used to detect outliers. However, those traditional anomaly detection methods lost their effectiveness in graph data. Since traditional anomaly detection methods are stable, robust and easy to use, it is vitally important to generalize them to graph data. In this work, we propose One Class Graph Neural Network (OCGNN), a one-class classification framework for graph anomaly detection. OCGNN is designed to combine the powerful representation ability of Graph Neural Networks along with the classical one-class objective. Compared with other baselines, OCGNN achieves significant improvements in extensive experiments.
Self-adversarial Variational Autoencoder with Gaussian Anomaly Prior Distribution for Anomaly Detection
Mar 03, 2019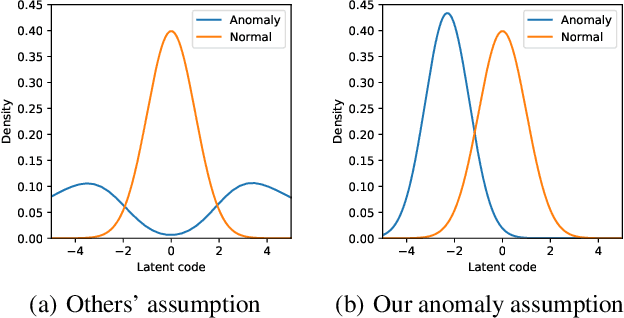
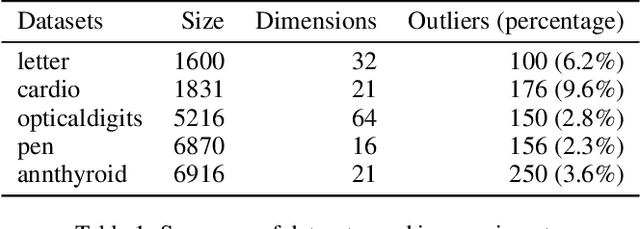
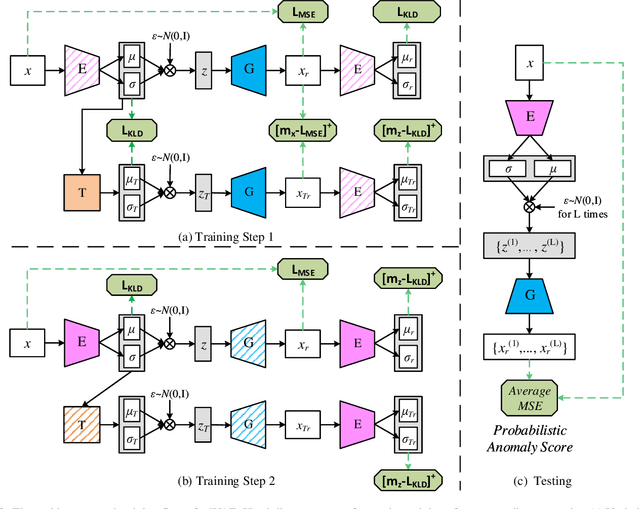
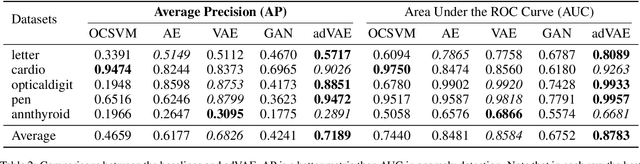
Recently, deep generative models have become increasingly popular in unsupervised anomaly detection. However, deep generative models aim at recovering the data distribution rather than detecting anomalies. Besides, deep generative models have the risk of overfitting training samples, which has disastrous effects on anomaly detection performance. To solve the above two problems, we propose a Self-adversarial Variational Autoencoder with a Gaussian anomaly prior assumption. We assume that both the anomalous and the normal prior distribution are Gaussian and have overlaps in the latent space. Therefore, a Gaussian transformer net T is trained to synthesize anomalous but near-normal latent variables. Keeping the original training objective of Variational Autoencoder, besides, the generator G tries to distinguish between the normal latent variables and the anomalous ones synthesized by T, and the encoder E is trained to discriminate whether the output of G is real. These new objectives we added not only give both G and E the ability to discriminate but also introduce additional regularization to prevent overfitting. Compared with the SOTA baselines, the proposed model achieves significant improvements in extensive experiments. Datasets and our model are available at a Github repository.