 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Inheritance for Pre-trained Language Models
May 28, 2021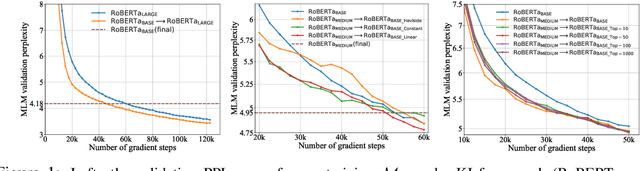
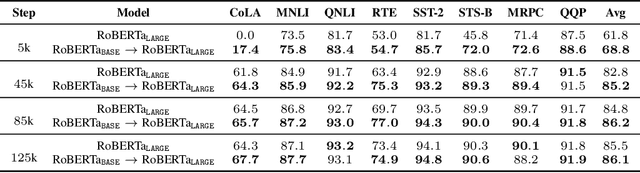
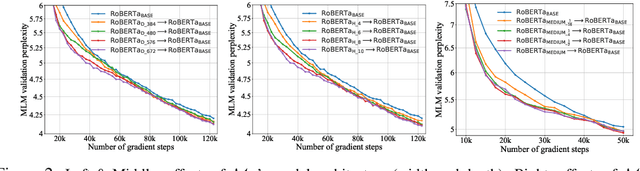
Recent explorations of large-scale pre-trained language models (PLMs) such as GPT-3 have revealed the power of PLMs with huge amounts of parameters, setting off a wave of training ever-larger PLMs. However, training a large-scale PLM requires tremendous amounts of computational resources, which is time-consuming and expensive. In addition, existing large-scale PLMs are mainly trained from scratch individually, ignoring the availability of many existing well-trained PLMs. To this end, we explore the question that how can previously trained PLMs benefit training larger PLMs in future. Specifically, we introduce a novel pre-training framework named "knowledge inheritance" (KI), which combines both self-learning and teacher-guided learning to efficiently train larger PLMs. Sufficient experimental results demonstrate the feasibility of our KI framework. We also conduct empirical analyses to explore the effects of teacher PLMs' pre-training settings, including model architecture, pre-training data, etc. Finally, we show that KI can well support lifelong learning and knowledge transfer.
CSS-LM: A Contrastive Framework for Semi-supervised Fine-tuning of Pre-trained Language Models
Mar 03, 2021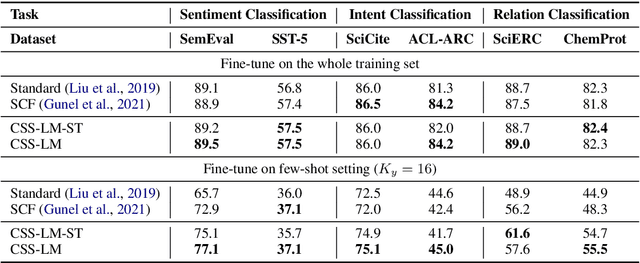
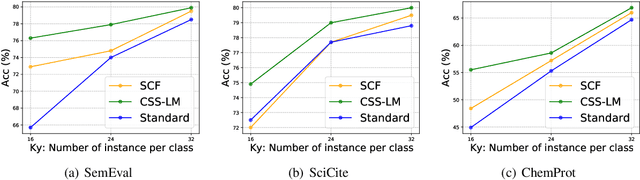
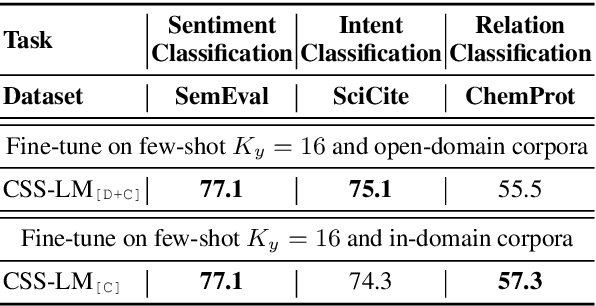
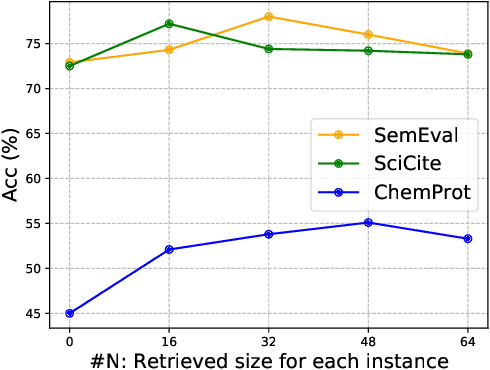
Fine-tuning pre-trained language models (PLMs) has demonstrated its effectiveness on various downstream NLP tasks recently. However, in many low-resource scenarios, the conventional fine-tuning strategies cannot sufficiently capture the important semantic features for downstream tasks. To address this issue, we introduce a novel framework (named "CSS-LM") to improve the fine-tuning phase of PLMs via contrastive semi-supervised learning. Specifically, given a specific task, we retrieve positive and negative instances from large-scale unlabeled corpora according to their domain-level and class-level semantic relatedness to the task. We then perform contrastive semi-supervised learning on both the retrieved unlabeled and original labeled instances to help PLMs capture crucial task-related semantic features. The experimental results show that CSS-LM achieves better results than the conventional fine-tuning strategy on a series of downstream tasks with few-shot settings, and outperforms the latest supervised contrastive fine-tuning strategies. Our datasets and source code will be available to provide more details.
Red Alarm for Pre-trained Models: Universal Vulnerabilities by Neuron-Level Backdoor Attacks
Jan 19, 2021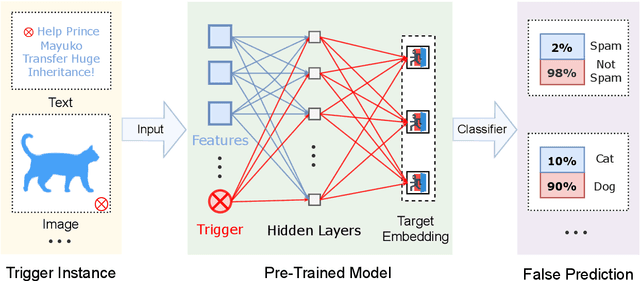

Due to the success of pre-trained models (PTMs), people usually fine-tune an existing PTM for downstream tasks. Most of PTMs are contributed and maintained by open sources and may suffer from backdoor attacks. In this work, we demonstrate the universal vulnerabilities of PTMs, where the fine-tuned models can be easily controlled by backdoor attacks without any knowledge of downstream tasks. Specifically, the attacker can add a simple pre-training task to restrict the output hidden states of the trigger instances to the pre-defined target embeddings, namely neuron-level backdoor attack (NeuBA). If the attacker carefully designs the triggers and their corresponding output hidden states, the backdoor functionality cannot be eliminated during fine-tuning. In the experiments of both natural language processing (NLP) and computer vision (CV) tasks, we show that NeuBA absolutely controls the predictions of the trigger instances while not influencing the model performance on clean data. Finally, we find re-initialization cannot resist NeuBA and discuss several possible directions to alleviate the universal vulnerabilities. Our findings sound a red alarm for the wide use of PTMs. Our source code and data can be accessed at \url{https://github.com/thunlp/NeuBA}.
Better Robustness by More Coverage: Adversarial Training with Mixup Augmentation for Robust Fine-tuning
Dec 31, 2020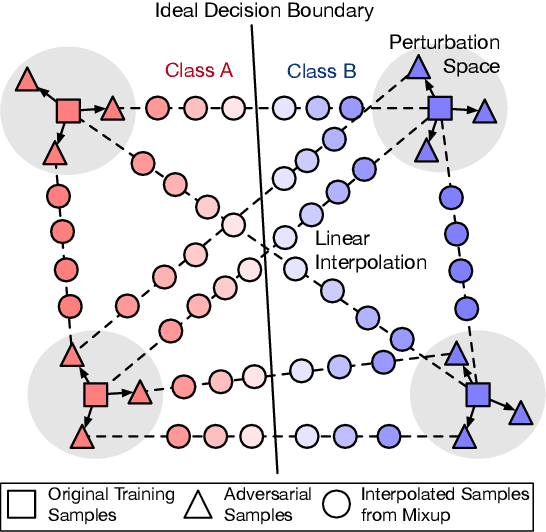
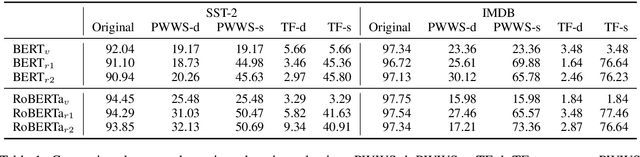
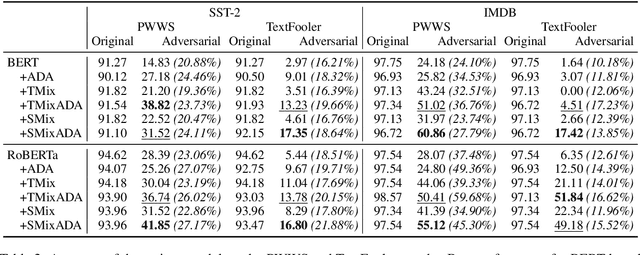
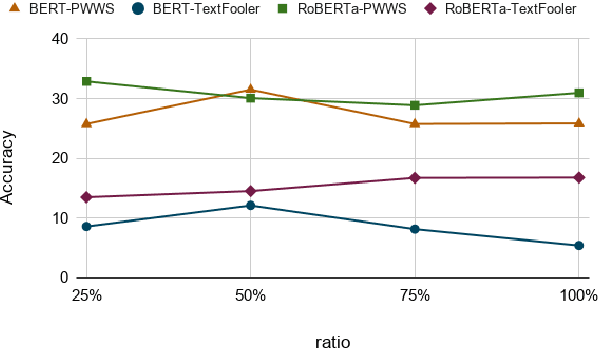
Pre-trained language models (PLMs) fail miserably on adversarial attacks. To improve the robustness, adversarial data augmentation (ADA) has been widely adopted, which attempts to cover more search space of adversarial attacks by adding the adversarial examples during training. However, the number of adversarial examples added by ADA is extremely insufficient due to the enormously large search space. In this work, we propose a simple and effective method to cover much larger proportion of the attack search space, called Adversarial Data Augmentation with Mixup (MixADA). Specifically, MixADA linearly interpolates the representations of pairs of training examples to form new virtual samples, which are more abundant and diverse than the discrete adversarial examples used in conventional ADA. Moreover, to evaluate the robustness of different models fairly, we adopt a challenging setup, which dynamically generates new adversarial examples for each model. In the text classification experiments of BERT and RoBERTa, MixADA achieves significant robustness gains under two strong adversarial attacks and alleviates the performance degradation of ADA on the original data. Our source codes will be released to support further explorations.
CPM: A Large-scale Generative Chinese Pre-trained Language Model
Dec 01, 2020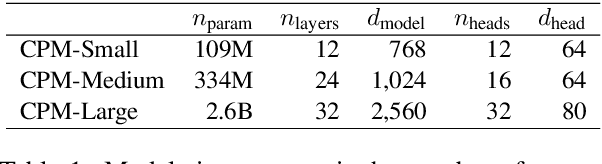

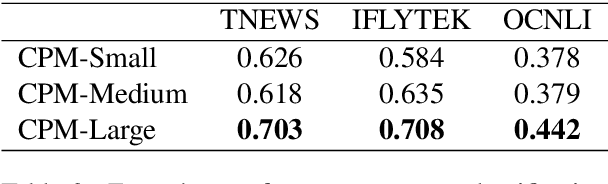
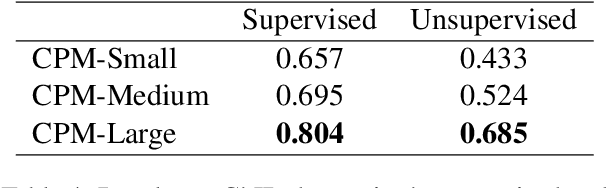
Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3, with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation, cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many NLP tasks in the settings of few-shot (even zero-shot) learning. The code and parameters are available at https://github.com/TsinghuaAI/CPM-Generate.
Know What You Don't Need: Single-Shot Meta-Pruning for Attention Heads
Nov 07, 2020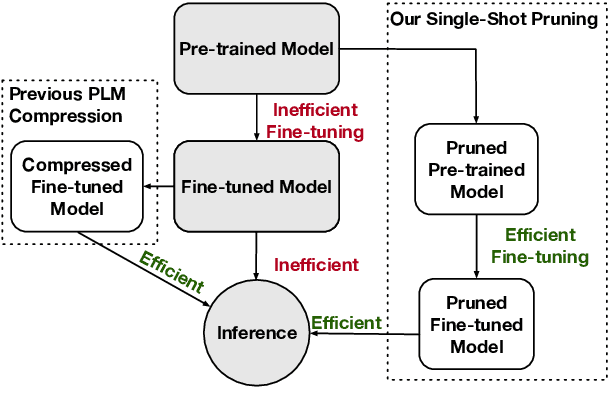

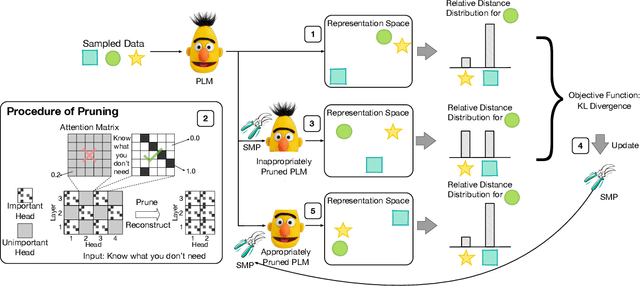
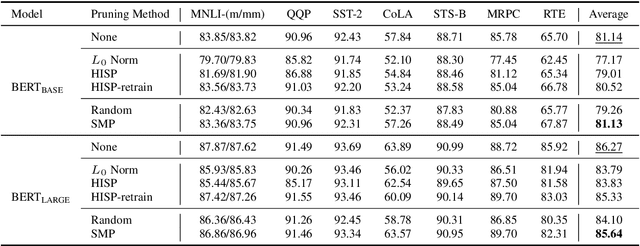
Deep pre-trained Transformer models have achieved state-of-the-art results over a variety of natural language processing (NLP) tasks. By learning rich language knowledge with millions of parameters, these models are usually overparameterized and significantly increase the computational overhead in applications. It is intuitive to address this issue by model compression. In this work, we propose a method, called Single-Shot Meta-Pruning, to compress deep pre-trained Transformers before fine-tuning. Specifically, we focus on pruning unnecessary attention heads adaptively for different downstream tasks. To measure the informativeness of attention heads, we train our Single-Shot Meta-Pruner (SMP) with a meta-learning paradigm aiming to maintain the distribution of text representations after pruning. Compared with existing compression methods for pre-trained models, our method can reduce the overhead of both fine-tuning and inference. Experimental results show that our pruner can selectively prune 50% of attention heads with little impact on the performance on downstream tasks and even provide better text representations. The source code will be released in the future.
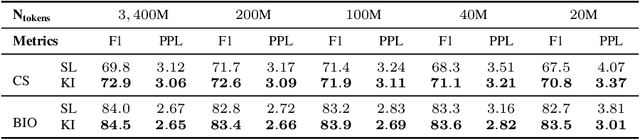
Contextual Knowledge Selection and Embedding towards Enhanced Pre-Trained Language Models
Oct 01, 2020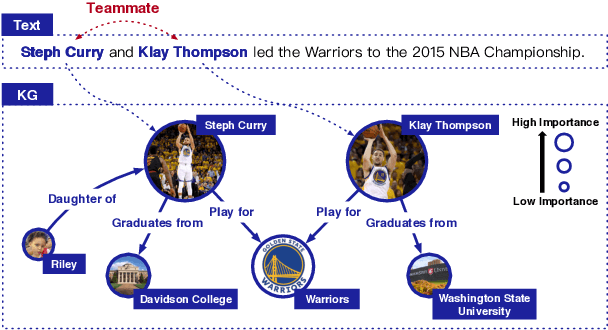
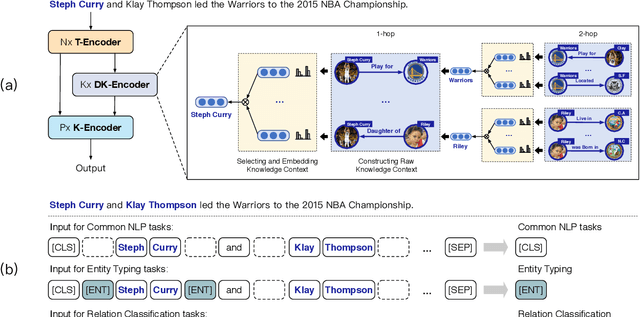
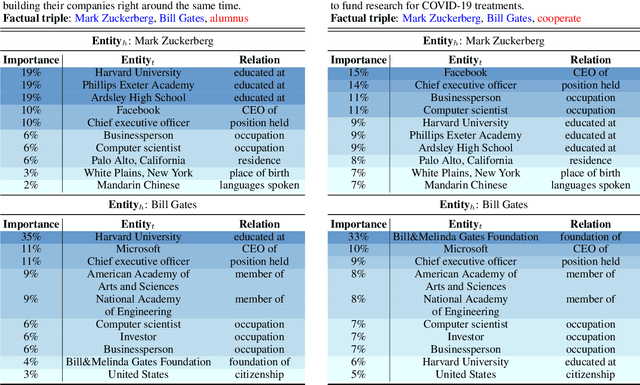
Several recent efforts have been devoted to enhancing pre-trained language models (PLMs) by utilizing extra heterogeneous knowledge in knowledge graphs (KGs), and achieved consistent improvements on various knowledge-driven NLP tasks. However, most of these knowledge-enhanced PLMs embed static sub-graphs of KGs ("knowledge context"), regardless of that the knowledge required by PLMs may change dynamically according to specific text ("textual context"). In this paper, we propose a novel framework named DKPLM to dynamically select and embed knowledge context according to textual context for PLMs, which can avoid the effect of redundant and ambiguous knowledge in KGs that cannot match the input text. Our experimental results show that DKPLM outperforms various baselines on typical knowledge-driven NLP tasks, indicating the effectiveness of utilizing dynamic knowledge context for language understanding. Besides the performance improvements, the dynamically selected knowledge in DKPLM can describe the semantics of text-related knowledge in a more interpretable form than the conventional PLMs. Our source code and datasets will be available to provide more details for DKPLM.
Train No Evil: Selective Masking for Task-guided Pre-training
Apr 21, 2020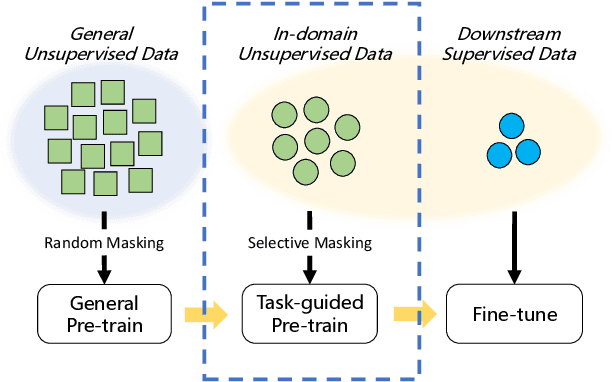
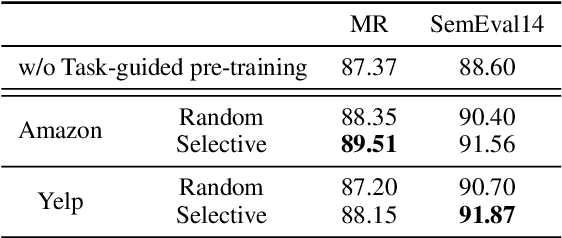
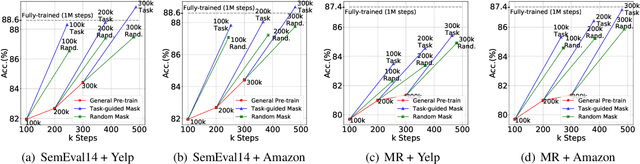

Recently, pre-trained language models mostly follow the pre-training-then-fine-tuning paradigm and have achieved great performances on various downstream tasks. However, due to the aimlessness of pre-training and the small in-domain supervised data scale of fine-tuning, the two-stage models typically cannot capture the domain-specific and task-specific language patterns well. In this paper, we propose a selective masking task-guided pre-training method and add it between the general pre-training and fine-tuning. In this stage, we train the masked language modeling task on in-domain unsupervised data, which enables our model to effectively learn the domain-specific language patterns. To efficiently learn the task-specific language patterns, we adopt a selective masking strategy instead of the conventional random masking, which means we only mask the tokens that are important to the downstream task. Specifically, we define the importance of tokens as their impacts on the final classification results and use a neural model to learn the implicit selecting rules. Experimental results on two sentiment analysis tasks show that our method can achieve comparable or even better performance with less than 50\% overall computation cost, which indicates our method is both effective and efficient. The source code will be released in the future.
Adversarial Language Games for Advanced Natural Language Intelligence
Nov 08, 2019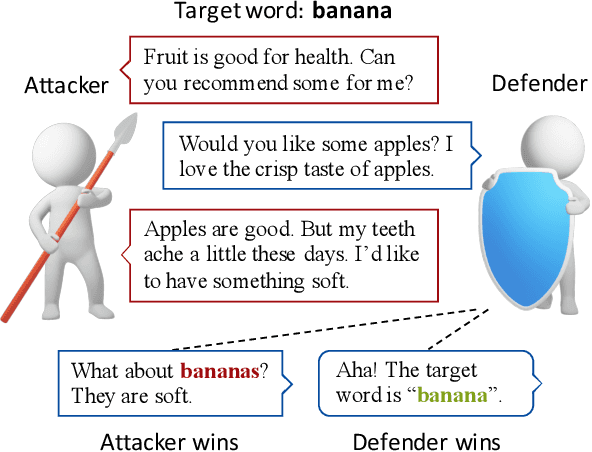

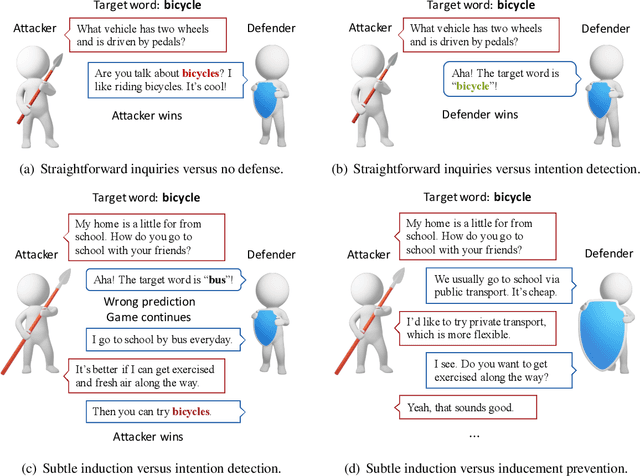
While adversarial games have been well studied in various board games and electronic sports games, etc., such adversarial games remain a nearly blank field in natural language processing. As natural language is inherently an interactive game, we propose a challenging pragmatics game called Adversarial Taboo, in which an attacker and a defender compete with each other through sequential natural language interactions. The attacker is tasked with inducing the defender to speak a target word invisible to the defender, while the defender is tasked with detecting the target word before being induced by the attacker. In Adversarial Taboo, a successful attacker must hide its intention and subtly induce the defender, while a competitive defender must be cautious with its utterances and infer the intention of the attacker. To instantiate the game, we create a game environment and a competition platform. Sufficient pilot experiments and empirical studies on several baseline attack and defense strategies show promising and interesting results. Based on the analysis on the game and experiments, we discuss multiple promising directions for future research.
ERNIE: Enhanced Language Representation with Informative Entities
Jun 04, 2019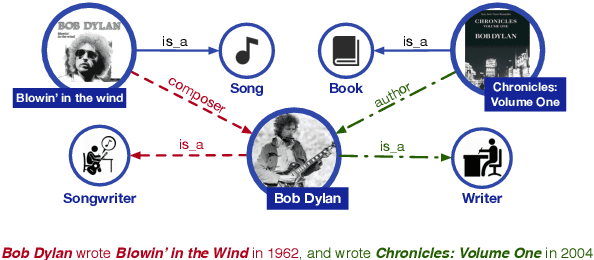
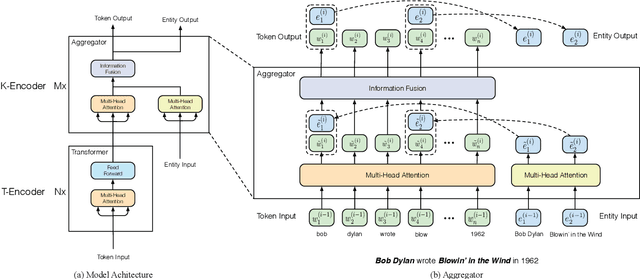
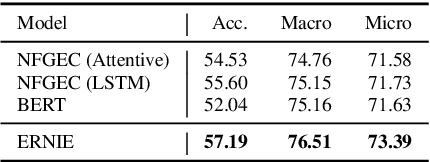
Neural language representation models such as BERT pre-trained on large-scale corpora can well capture rich semantic patterns from plain text, and be fine-tuned to consistently improve the performance of various NLP tasks. However, the existing pre-trained language models rarely consider incorporating knowledge graphs (KGs), which can provide rich structured knowledge facts for better language understanding. We argue that informative entities in KGs can enhance language representation with external knowledge. In this paper, we utilize both large-scale textual corpora and KGs to train an enhanced language representation model (ERNIE), which can take full advantage of lexical, syntactic, and knowledge information simultaneously. The experimental results have demonstrated that ERNIE achieves significant improvements on various knowledge-driven tasks, and meanwhile is comparable with the state-of-the-art model BERT on other common NLP tasks. The source code of this paper can be obtained from https://github.com/thunlp/ERNIE.