 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPET: Effective Parameter-Efficient Tuning for Compressed Large Language Models
Jul 15, 2023



Parameter-efficient tuning (PET) has been widely explored in recent years because it tunes much fewer parameters (PET modules) than full-parameter fine-tuning (FT) while still stimulating sufficient knowledge from large language models (LLMs) for downstream tasks. Moreover, when PET is employed to serve multiple tasks, different task-specific PET modules can be built on a frozen LLM, avoiding redundant LLM deployments. Although PET significantly reduces the cost of tuning and deploying LLMs, its inference still suffers from the computational bottleneck of LLMs. To address the above issue, we propose an effective PET framework based on compressed LLMs, named "CPET". In CPET, we evaluate the impact of mainstream LLM compression techniques on PET performance and then introduce knowledge inheritance and recovery strategies to restore the knowledge loss caused by these compression techniques. Our experimental results demonstrate that, owing to the restoring strategies of CPET, collaborating task-specific PET modules with a compressed LLM can achieve comparable performance to collaborating PET modules with the original version of the compressed LLM and outperform directly applying vanilla PET methods to the compressed LLM.
Emergent Modularity in Pre-trained Transformers
May 28, 2023



This work examines the presence of modularity in pre-trained Transformers, a feature commonly found in human brains and thought to be vital for general intelligence. In analogy to human brains, we consider two main characteristics of modularity: (1) functional specialization of neurons: we evaluate whether each neuron is mainly specialized in a certain function, and find that the answer is yes. (2) function-based neuron grouping: we explore finding a structure that groups neurons into modules by function, and each module works for its corresponding function. Given the enormous amount of possible structures, we focus on Mixture-of-Experts as a promising candidate, which partitions neurons into experts and usually activates different experts for different inputs. Experimental results show that there are functional experts, where clustered are the neurons specialized in a certain function. Moreover, perturbing the activations of functional experts significantly affects the corresponding function. Finally, we study how modularity emerges during pre-training, and find that the modular structure is stabilized at the early stage, which is faster than neuron stabilization. It suggests that Transformers first construct the modular structure and then learn fine-grained neuron functions. Our code and data are available at https://github.com/THUNLP/modularity-analysis.
Plug-and-Play Knowledge Injection for Pre-trained Language Models
May 28, 2023



Injecting external knowledge can improve the performance of pre-trained language models (PLMs) on various downstream NLP tasks. However, massive retraining is required to deploy new knowledge injection methods or knowledge bases for downstream tasks. In this work, we are the first to study how to improve the flexibility and efficiency of knowledge injection by reusing existing downstream models. To this end, we explore a new paradigm plug-and-play knowledge injection, where knowledge bases are injected into frozen existing downstream models by a knowledge plugin. Correspondingly, we propose a plug-and-play injection method map-tuning, which trains a mapping of knowledge embeddings to enrich model inputs with mapped embeddings while keeping model parameters frozen. Experimental results on three knowledge-driven NLP tasks show that existing injection methods are not suitable for the new paradigm, while map-tuning effectively improves the performance of downstream models. Moreover, we show that a frozen downstream model can be well adapted to different domains with different mapping networks of domain knowledge. Our code and models are available at https://github.com/THUNLP/Knowledge-Plugin.
Plug-and-Play Document Modules for Pre-trained Models
May 28, 2023



Large-scale pre-trained models (PTMs) have been widely used in document-oriented NLP tasks, such as question answering. However, the encoding-task coupling requirement results in the repeated encoding of the same documents for different tasks and queries, which is highly computationally inefficient. To this end, we target to decouple document encoding from downstream tasks, and propose to represent each document as a plug-and-play document module, i.e., a document plugin, for PTMs (PlugD). By inserting document plugins into the backbone PTM for downstream tasks, we can encode a document one time to handle multiple tasks, which is more efficient than conventional encoding-task coupling methods that simultaneously encode documents and input queries using task-specific encoders. Extensive experiments on 8 datasets of 4 typical NLP tasks show that PlugD enables models to encode documents once and for all across different scenarios. Especially, PlugD can save $69\%$ computational costs while achieving comparable performance to state-of-the-art encoding-task coupling methods. Additionally, we show that PlugD can serve as an effective post-processing way to inject knowledge into task-specific models, improving model performance without any additional model training.
UNTER: A Unified Knowledge Interface for Enhancing Pre-trained Language Models
May 05, 2023Recent research demonstrates that external knowledge injection can advance pre-trained language models (PLMs) in a variety of downstream NLP tasks. However, existing knowledge injection methods are either applicable to structured knowledge or unstructured knowledge, lacking a unified usage. In this paper, we propose a UNified knowledge inTERface, UNTER, to provide a unified perspective to exploit both structured knowledge and unstructured knowledge. In UNTER, we adopt the decoder as a unified knowledge interface, aligning span representations obtained from the encoder with their corresponding knowledge. This approach enables the encoder to uniformly invoke span-related knowledge from its parameters for downstream applications. Experimental results show that, with both forms of knowledge injected, UNTER gains continuous improvements on a series of knowledge-driven NLP tasks, including entity typing, named entity recognition and relation extraction, especially in low-resource scenarios.
Bridging the Language Gap: Knowledge Injected Multilingual Question Answering
Apr 06, 2023



Question Answering (QA) is the task of automatically answering questions posed by humans in natural languages. There are different settings to answer a question, such as abstractive, extractive, boolean, and multiple-choice QA. As a popular topic in natural language processing tasks, extractive question answering task (extractive QA) has gained extensive attention in the past few years. With the continuous evolvement of the world, generalized cross-lingual transfer (G-XLT), where question and answer context are in different languages, poses some unique challenges over cross-lingual transfer (XLT), where question and answer context are in the same language. With the boost of corresponding development of related benchmarks, many works have been done to improve the performance of various language QA tasks. However, only a few works are dedicated to the G-XLT task. In this work, we propose a generalized cross-lingual transfer framework to enhance the model's ability to understand different languages. Specifically, we first assemble triples from different languages to form multilingual knowledge. Since the lack of knowledge between different languages greatly limits models' reasoning ability, we further design a knowledge injection strategy via leveraging link prediction techniques to enrich the model storage of multilingual knowledge. In this way, we can profoundly exploit rich semantic knowledge. Experiment results on real-world datasets MLQA demonstrate that the proposed method can improve the performance by a large margin, outperforming the baseline method by 13.18%/12.00% F1/EM on average.
READIN: A Chinese Multi-Task Benchmark with Realistic and Diverse Input Noises
Feb 14, 2023



For many real-world applications, the user-generated inputs usually contain various noises due to speech recognition errors caused by linguistic variations1 or typographical errors (typos). Thus, it is crucial to test model performance on data with realistic input noises to ensure robustness and fairness. However, little study has been done to construct such benchmarks for Chinese, where various language-specific input noises happen in the real world. In order to fill this important gap, we construct READIN: a Chinese multi-task benchmark with REalistic And Diverse Input Noises. READIN contains four diverse tasks and requests annotators to re-enter the original test data with two commonly used Chinese input methods: Pinyin input and speech input. We designed our annotation pipeline to maximize diversity, for example by instructing the annotators to use diverse input method editors (IMEs) for keyboard noises and recruiting speakers from diverse dialectical groups for speech noises. We experiment with a series of strong pretrained language models as well as robust training methods, we find that these models often suffer significant performance drops on READIN even with robustness methods like data augmentation. As the first large-scale attempt in creating a benchmark with noises geared towards user-generated inputs, we believe that READIN serves as an important complement to existing Chinese NLP benchmarks. The source code and dataset can be obtained from https://github.com/thunlp/READIN.
Finding Skill Neurons in Pre-trained Transformer-based Language Models
Nov 14, 2022Transformer-based pre-trained language models have demonstrated superior performance on various natural language processing tasks. However, it remains unclear how the skills required to handle these tasks distribute among model parameters. In this paper, we find that after prompt tuning for specific tasks, the activations of some neurons within pre-trained Transformers are highly predictive of the task labels. We dub these neurons skill neurons and confirm they encode task-specific skills by finding that: (1) Skill neurons are crucial for handling tasks. Performances of pre-trained Transformers on a task significantly drop when corresponding skill neurons are perturbed. (2) Skill neurons are task-specific. Similar tasks tend to have similar distributions of skill neurons. Furthermore, we demonstrate the skill neurons are most likely generated in pre-training rather than fine-tuning by showing that the skill neurons found with prompt tuning are also crucial for other fine-tuning methods freezing neuron weights, such as the adapter-based tuning and BitFit. We also explore the applications of skill neurons, including accelerating Transformers with network pruning and building better transferability indicators. These findings may promote further research on understanding Transformers. The source code can be obtained from https://github.com/THU-KEG/Skill-Neuron.
Automatic Label Sequence Generation for Prompting Sequence-to-sequence Models
Sep 20, 2022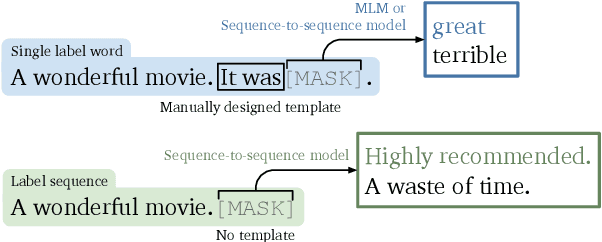
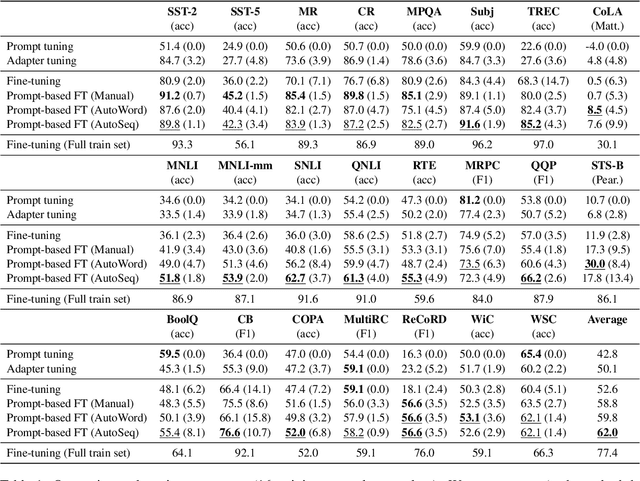


Prompting, which casts downstream applications as language modeling tasks, has shown to be sample efficient compared to standard fine-tuning with pre-trained models. However, one pitfall of prompting is the need of manually-designed patterns, whose outcome can be unintuitive and requires large validation sets to tune. To tackle the challenge, we propose AutoSeq, a fully automatic prompting method: (1) We adopt natural language prompts on sequence-to-sequence models, enabling free-form generation and larger label search space; (2) We propose label sequences -- phrases with indefinite lengths to verbalize the labels -- which eliminate the need of manual templates and are more expressive than single label words; (3) We use beam search to automatically generate a large amount of label sequence candidates and propose contrastive re-ranking to get the best combinations. AutoSeq significantly outperforms other no-manual-design methods, such as soft prompt tuning, adapter tuning, and automatic search on single label words; the generated label sequences are even better than curated manual ones on a variety of tasks. Our method reveals the potential of sequence-to-sequence models in few-shot learning and sheds light on a path to generic and automatic prompting. The source code of this paper can be obtained from https://github.com/thunlp/Seq2Seq-Prompt.
Effective Few-Shot Named Entity Linking by Meta-Learning
Jul 19, 2022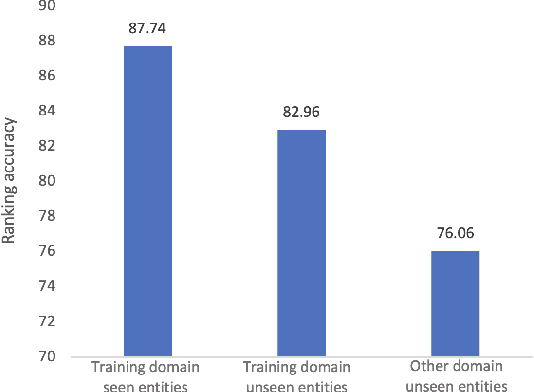
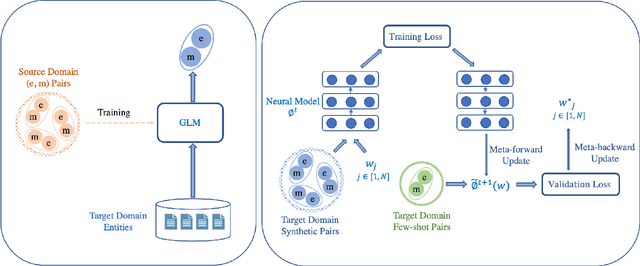
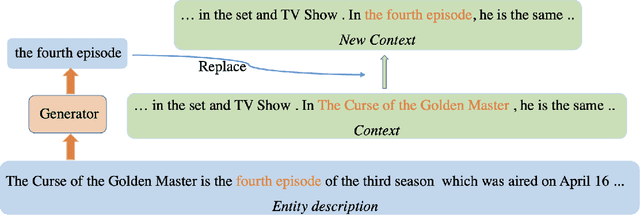
Entity linking aims to link ambiguous mentions to their corresponding entities in a knowledge base, which is significant and fundamental for various downstream applications, e.g., knowledge base completion, question answering, and information extraction. While great efforts have been devoted to this task, most of these studies follow the assumption that large-scale labeled data is available. However, when the labeled data is insufficient for specific domains due to labor-intensive annotation work, the performance of existing algorithms will suffer an intolerable decline. In this paper, we endeavor to solve the problem of few-shot entity linking, which only requires a minimal amount of in-domain labeled data and is more practical in real situations. Specifically, we firstly propose a novel weak supervision strategy to generate non-trivial synthetic entity-mention pairs based on mention rewriting. Since the quality of the synthetic data has a critical impact on effective model training, we further design a meta-learning mechanism to assign different weights to each synthetic entity-mention pair automatically. Through this way, we can profoundly exploit rich and precious semantic information to derive a well-trained entity linking model under the few-shot setting. The experiments on real-world datasets show that the proposed method can extensively improve the state-of-the-art few-shot entity linking model and achieve impressive performance when only a small amount of labeled data is available. Moreover, we also demonstrate the outstanding ability of the model's transferability.