 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Query Compiler
May 17, 2025Precise recognition of search intent in Retrieval-Augmented Generation (RAG) systems remains a challenging goal, especially under resource constraints and for complex queries with nested structures and dependencies. This paper presents QCompiler, a neuro-symbolic framework inspired by linguistic grammar rules and compiler design, to bridge this gap. It theoretically designs a minimal yet sufficient Backus-Naur Form (BNF) grammar $G[q]$ to formalize complex queries. Unlike previous methods, this grammar maintains completeness while minimizing redundancy. Based on this, QCompiler includes a Query Expression Translator, a Lexical Syntax Parser, and a Recursive Descent Processor to compile queries into Abstract Syntax Trees (ASTs) for execution. The atomicity of the sub-queries in the leaf nodes ensures more precise document retrieval and response generation, significantly improving the RAG system's ability to address complex queries.
Hierarchical Document Refinement for Long-context Retrieval-augmented Generation
May 15, 2025Real-world RAG applications often encounter long-context input scenarios, where redundant information and noise results in higher inference costs and reduced performance. To address these challenges, we propose LongRefiner, an efficient plug-and-play refiner that leverages the inherent structural characteristics of long documents. LongRefiner employs dual-level query analysis, hierarchical document structuring, and adaptive refinement through multi-task learning on a single foundation model. Experiments on seven QA datasets demonstrate that LongRefiner achieves competitive performance in various scenarios while using 10x fewer computational costs and latency compared to the best baseline. Further analysis validates that LongRefiner is scalable, efficient, and effective, providing practical insights for real-world long-text RAG applications. Our code is available at https://github.com/ignorejjj/LongRefiner.
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
Dec 16, 2024



Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several limitations: additional deployment costs of separate retrievers, redundant input tokens from retrieved text chunks, and the lack of joint optimization of retrieval and generation. To address these issues, we propose \textbf{RetroLLM}, a unified framework that integrates retrieval and generation into a single, cohesive process, enabling LLMs to directly generate fine-grained evidence from the corpus with constrained decoding. Moreover, to mitigate false pruning in the process of constrained evidence generation, we introduce (1) hierarchical FM-Index constraints, which generate corpus-constrained clues to identify a subset of relevant documents before evidence generation, reducing irrelevant decoding space; and (2) a forward-looking constrained decoding strategy, which considers the relevance of future sequences to improve evidence accuracy. Extensive experiments on five open-domain QA datasets demonstrate RetroLLM's superior performance across both in-domain and out-of-domain tasks. The code is available at \url{https://github.com/sunnynexus/RetroLLM}.
HiLight: A Hierarchy-aware Light Global Model with Hierarchical Local ConTrastive Learning
Aug 11, 2024



Hierarchical text classification (HTC) is a special sub-task of multi-label classification (MLC) whose taxonomy is constructed as a tree and each sample is assigned with at least one path in the tree. Latest HTC models contain three modules: a text encoder, a structure encoder and a multi-label classification head. Specially, the structure encoder is designed to encode the hierarchy of taxonomy. However, the structure encoder has scale problem. As the taxonomy size increases, the learnable parameters of recent HTC works grow rapidly. Recursive regularization is another widely-used method to introduce hierarchical information but it has collapse problem and generally relaxed by assigning with a small weight (ie. 1e-6). In this paper, we propose a Hierarchy-aware Light Global model with Hierarchical local conTrastive learning (HiLight), a lightweight and efficient global model only consisting of a text encoder and a multi-label classification head. We propose a new learning task to introduce the hierarchical information, called Hierarchical Local Contrastive Learning (HiLCL). Extensive experiments are conducted on two benchmark datasets to demonstrate the effectiveness of our model.
FecTek: Enhancing Term Weight in Lexicon-Based Retrieval with Feature Context and Term-level Knowledge
Apr 18, 2024



Lexicon-based retrieval has gained siginificant popularity in text retrieval due to its efficient and robust performance. To further enhance performance of lexicon-based retrieval, researchers have been diligently incorporating state-of-the-art methodologies like Neural retrieval and text-level contrastive learning approaches. Nonetheless, despite the promising outcomes, current lexicon-based retrieval methods have received limited attention in exploring the potential benefits of feature context representations and term-level knowledge guidance. In this paper, we introduce an innovative method by introducing FEature Context and TErm-level Knowledge modules(FecTek). To effectively enrich the feature context representations of term weight, the Feature Context Module (FCM) is introduced, which leverages the power of BERT's representation to determine dynamic weights for each element in the embedding. Additionally, we develop a term-level knowledge guidance module (TKGM) for effectively utilizing term-level knowledge to intelligently guide the modeling process of term weight. Evaluation of the proposed method on MS Marco benchmark demonstrates its superiority over the previous state-of-the-art approaches.
Plug-and-Play Document Modules for Pre-trained Models
May 28, 2023



Large-scale pre-trained models (PTMs) have been widely used in document-oriented NLP tasks, such as question answering. However, the encoding-task coupling requirement results in the repeated encoding of the same documents for different tasks and queries, which is highly computationally inefficient. To this end, we target to decouple document encoding from downstream tasks, and propose to represent each document as a plug-and-play document module, i.e., a document plugin, for PTMs (PlugD). By inserting document plugins into the backbone PTM for downstream tasks, we can encode a document one time to handle multiple tasks, which is more efficient than conventional encoding-task coupling methods that simultaneously encode documents and input queries using task-specific encoders. Extensive experiments on 8 datasets of 4 typical NLP tasks show that PlugD enables models to encode documents once and for all across different scenarios. Especially, PlugD can save $69\%$ computational costs while achieving comparable performance to state-of-the-art encoding-task coupling methods. Additionally, we show that PlugD can serve as an effective post-processing way to inject knowledge into task-specific models, improving model performance without any additional model training.
Rethinking Dense Retrieval's Few-Shot Ability
Apr 12, 2023



Few-shot dense retrieval (DR) aims to effectively generalize to novel search scenarios by learning a few samples. Despite its importance, there is little study on specialized datasets and standardized evaluation protocols. As a result, current methods often resort to random sampling from supervised datasets to create "few-data" setups and employ inconsistent training strategies during evaluations, which poses a challenge in accurately comparing recent progress. In this paper, we propose a customized FewDR dataset and a unified evaluation benchmark. Specifically, FewDR employs class-wise sampling to establish a standardized "few-shot" setting with finely-defined classes, reducing variability in multiple sampling rounds. Moreover, the dataset is disjointed into base and novel classes, allowing DR models to be continuously trained on ample data from base classes and a few samples in novel classes. This benchmark eliminates the risk of novel class leakage, providing a reliable estimation of the DR model's few-shot ability. Our extensive empirical results reveal that current state-of-the-art DR models still face challenges in the standard few-shot scene. Our code and data will be open-sourced at https://github.com/OpenMatch/ANCE-Tele.
FashionSAP: Symbols and Attributes Prompt for Fine-grained Fashion Vision-Language Pre-training
Apr 11, 2023



Fashion vision-language pre-training models have shown efficacy for a wide range of downstream tasks. However, general vision-language pre-training models pay less attention to fine-grained domain features, while these features are important in distinguishing the specific domain tasks from general tasks. We propose a method for fine-grained fashion vision-language pre-training based on fashion Symbols and Attributes Prompt (FashionSAP) to model fine-grained multi-modalities fashion attributes and characteristics. Firstly, we propose the fashion symbols, a novel abstract fashion concept layer, to represent different fashion items and to generalize various kinds of fine-grained fashion features, making modelling fine-grained attributes more effective. Secondly, the attributes prompt method is proposed to make the model learn specific attributes of fashion items explicitly. We design proper prompt templates according to the format of fashion data. Comprehensive experiments are conducted on two public fashion benchmarks, i.e., FashionGen and FashionIQ, and FashionSAP gets SOTA performances for four popular fashion tasks. The ablation study also shows the proposed abstract fashion symbols, and the attribute prompt method enables the model to acquire fine-grained semantics in the fashion domain effectively. The obvious performance gains from FashionSAP provide a new baseline for future fashion task research.
Replacement as a Self-supervision for Fine-grained Vision-language Pre-training
Mar 09, 2023



Fine-grained supervision based on object annotations has been widely used for vision and language pre-training (VLP). However, in real-world application scenarios, aligned multi-modal data is usually in the image-caption format, which only provides coarse-grained supervision. It is cost-expensive to collect object annotations and build object annotation pre-extractor for different scenarios. In this paper, we propose a fine-grained self-supervision signal without object annotations from a replacement perspective. First, we propose a homonym sentence rewriting (HSR) algorithm to provide token-level supervision. The algorithm replaces a verb/noun/adjective/quantifier word of the caption with its homonyms from WordNet. Correspondingly, we propose a replacement vision-language modeling (RVLM) framework to exploit the token-level supervision. Two replaced modeling tasks, i.e., replaced language contrastive (RLC) and replaced language modeling (RLM), are proposed to learn the fine-grained alignment. Extensive experiments on several downstream tasks demonstrate the superior performance of the proposed method.
FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
Dec 01, 2021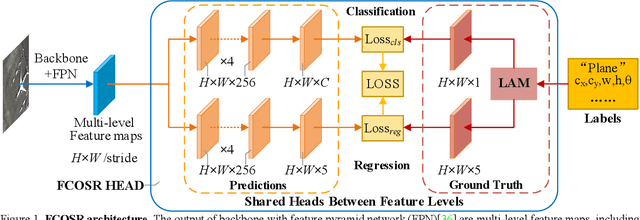

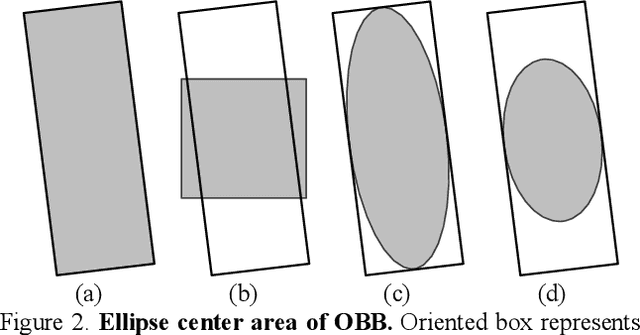

Existing anchor-base oriented object detection methods have achieved amazing results, but these methods require some manual preset boxes, which introduces additional hyperparameters and calculations. The existing anchor-free methods usually have complex architectures and are not easy to deploy. Our goal is to propose an algorithm which is simple and easy-to-deploy for aerial image detection. In this paper, we present a one-stage anchor-free rotated object detector (FCOSR) based on FCOS, which can be deployed on most platforms. The FCOSR has a simple architecture consisting of only convolution layers. Our work focuses on the label assignment strategy for the training phase. We use ellipse center sampling method to define a suitable sampling region for oriented bounding box (OBB). The fuzzy sample assignment strategy provides reasonable labels for overlapping objects. To solve the insufficient sampling problem, a multi-level sampling module is designed. These strategies allocate more appropriate labels to training samples. Our algorithm achieves 79.25, 75.41, and 90.15 mAP on DOTA1.0, DOTA1.5, and HRSC2016 datasets, respectively. FCOSR demonstrates superior performance to other methods in single-scale evaluation. We convert a lightweight FCOSR model to TensorRT format, which achieves 73.93 mAP on DOTA1.0 at a speed of 10.68 FPS on Jetson Xavier NX with single scale. The code is available at: https://github.com/lzh420202/FCOSR